


Apakah Netflix menggunakan kafka?
Menampilkan Apache Kafka di Netflix Studio and Finance World
Ringkasan:
Di Netflix, sebagian besar aplikasi menggunakan Perpustakaan Klien Java untuk menghasilkan data ke Keystone Pipeline. Pipa ini terdiri dari fronting kluster Kafka, yang bertanggung jawab untuk mengumpulkan dan buffering data, dan kluster Kafka konsumen, yang berisi topik untuk konsumen real-time. Netflix mengoperasikan total 36 kelompok kafka yang menangani lebih dari 700 miliar pesan setiap hari. Untuk mencapai pengiriman lossless, pipa memungkinkan tingkat kehilangan data kurang dari 0.01%. Produsen dan broker dikonfigurasi untuk memastikan ketersediaan dan pengalaman pengguna yang baik.
Poin -Poin Kunci:
- Aplikasi Netflix Gunakan Pustaka Klien Java untuk menghasilkan data ke Keystone Pipeline
- Ada beberapa produsen kafka di setiap instance aplikasi
- Fronting Kafka Clusters mengumpulkan dan buffer pesan
- Konsumen Kafka Cluster berisi topik untuk konsumen real-time
- Netflix mengoperasikan 36 kelompok kafka dengan lebih dari 700 miliar pesan setiap hari
- Tingkat kehilangan data kurang dari 0.01%
- Produsen dan broker dikonfigurasi untuk memastikan ketersediaan
- Produsen menggunakan konfigurasi dinamis untuk routing topik dan isolasi wastafel
- Aplikasi non-java dapat mengirim acara ke titik akhir istirahat Keystone
- Pemesanan pesan dibuat dalam pemrosesan batch atau lapisan perutean
Pertanyaan:
- Bagaimana Aplikasi Netflix Menghasilkan Data ke Keystone Pipeline?
- Apa peran fronting kafka cluster?
- Jenis kelompok kafka apa yang ada di pipa Keystone?
- Berapa banyak kelompok kafka yang dioperasikan Netflix?
- Berapa tingkat konsumsi data rata -rata untuk Netflix?
- Apa versi kafka saat ini yang digunakan oleh Netflix?
- Bagaimana Netflix mencapai pengiriman lossless di dalam pipa?
- Apa konfigurasi bagi produsen dan broker untuk memastikan ketersediaan?
- Bagaimana pemesanan pesan dipertahankan?
- Mengapa Aplikasi Klien Tidak Mengonsumsi Langsung Dari Menghasilkan Kafka Clusters?
- Tantangan apa yang muncul saat menjalankan kafka di cloud?
- Bagaimana Replikasi Dampak Ketersediaan Kafka?
- Apa yang telah dilakukan Netflix untuk mengatasi insiden dan mempertahankan stabilitas cluster?
- Apa strategi penyebaran Netflix untuk kluster Kafka?
Sebagian besar aplikasi Netflix menggunakan Perpustakaan Klien Java untuk menghasilkan data ke pipa Keystone. Setiap instance aplikasi memiliki beberapa produsen kafka.
Menghadapi kluster Kafka mengumpulkan dan buffer pesan dari produsen. Mereka berfungsi sebagai pintu gerbang untuk injeksi pesan.
Pipa Keystone terdiri dari Fronting Kafka Clusters dan Consumer Kafka Clusters.
Netflix mengoperasikan 36 kluster kafka.
Netflix menelan lebih dari 700 miliar pesan setiap hari.
Netflix beralih dari Kafka Versi 0.8.2.1 hingga 0.9.0.1.
Akuntansi untuk volume data yang sangat besar, Netflix telah bekerja dengan tim untuk menerima jumlah kehilangan data yang dapat diterima, menghasilkan tingkat kehilangan data harian kurang dari 0.01%.
Produsen dan broker dikonfigurasi dengan blok “ACKS = 1”, “.pada.penyangga.penuh = false “, dan” najis.pemimpin.pemilihan.aktifkan = true “.
Produsen tidak menggunakan pesan kunci, dan pemesanan pesan didirikan kembali di lapisan pemrosesan batch atau lapisan perutean.
Aplikasi klien tidak diperbolehkan mengonsumsi secara langsung dari fronting kluster Kafka untuk memastikan beban dan stabilitas yang dapat diprediksi.
Menjalankan kafka di cloud menimbulkan tantangan seperti siklus hidup instance yang tidak dapat diprediksi, masalah jaringan sementara, dan outlier yang menyebabkan masalah kinerja.
Replikasi meningkatkan ketersediaan, tetapi broker outlier dapat menyebabkan efek cascading dan penurunan pesan karena lag replikasi dan kelelahan buffer.
Netflix Mengurangi Konsepsi dan Kompleksitas, Mengimplementasikan Deteksi Luar, dan Mengembangkan Langkah -langkah untuk dengan cepat pulih dari insiden.
Netflix mendukung beberapa cluster Kafka kecil di atas satu cluster raksasa untuk mengurangi ketergantungan dan meningkatkan stabilitas.
Kafka di dalam pipa keystone
Kami memiliki dua set kluster Kafka di Keystone Pipeline: Fronting Kafka dan konsumen kafka. Fronting Kafka Clusters bertanggung jawab untuk mendapatkan pesan dari produsen yang hampir setiap contoh aplikasi di Netflix. Peran mereka adalah pengumpulan data dan buffering untuk sistem hilir. Konsumen Kafka Cluster berisi subset topik yang dialihkan oleh Samza untuk konsumen real-time.
Kami saat ini mengoperasikan 36 kluster kafka yang terdiri dari 4.000+ instance broker untuk fronting kafka dan konsumen kafka. Lebih dari 700 miliar pesan dicerna pada hari rata -rata. Kami saat ini sedang beralih dari Kafka Versi 0.8.2.1 hingga 0.9.0.1.
Prinsip desain
Mengingat arsitektur kafka saat ini dan volume data besar kami, untuk mencapai pengiriman lossless untuk pipa data kami adalah penghalang biaya di AWS EC2. Akuntansi untuk ini, kami’VE bekerja dengan tim yang bergantung pada infrastruktur kami untuk mencapai jumlah kehilangan data yang dapat diterima, sambil menyeimbangkan biaya. Kami’VE mencapai tingkat kehilangan data harian kurang dari 0.01%. Metrik dikumpulkan untuk pesan yang dijatuhkan sehingga kami dapat mengambil tindakan jika diperlukan.
Pipa Keystone menghasilkan pesan secara tidak sinkron tanpa memblokir aplikasi. Jika pesan tidak dapat dikirimkan setelah coba lagi, itu akan dijatuhkan oleh produser untuk memastikan ketersediaan aplikasi dan pengalaman pengguna yang baik. Inilah sebabnya kami telah memilih konfigurasi berikut untuk produser dan broker kami:
- ACKS = 1
- memblokir.pada.penyangga.full = false
- najis.pemimpin.pemilihan.aktifkan = true
Sebagian besar aplikasi di Netflix menggunakan Perpustakaan Klien Java kami untuk memproduksi ke Keystone Pipeline. Pada setiap contoh dari aplikasi tersebut, ada beberapa produsen kafka, dengan masing -masing memproduksi cluster kafka yang fronting untuk isolasi tingkat wastafel. Produsen memiliki routing topik yang fleksibel dan konfigurasi wastafel yang didorong melalui konfigurasi dinamis yang dapat diubah saat runtime tanpa harus memulai kembali proses aplikasi. Ini memungkinkan untuk hal -hal seperti mengarahkan kembali lalu lintas dan migrasi topik di seluruh kluster Kafka. Untuk aplikasi non-java, mereka dapat memilih untuk mengirim acara ke titik akhir istirahat Keystone yang menyampaikan pesan ke fronting kluster kafka.
Untuk fleksibilitas yang lebih besar, produsen tidak menggunakan pesan kunci. Perkiraan Pesan Pesan didirikan kembali di lapisan pemrosesan batch (Hive / Elasticsearch) atau lapisan perutean untuk streaming konsumen.
Kami menempatkan stabilitas kelompok kafka fronting kami pada prioritas tinggi karena mereka adalah gerbang untuk injeksi pesan. Oleh karena itu kami tidak mengizinkan aplikasi klien untuk secara langsung mengkonsumsi dari mereka untuk memastikan mereka memiliki beban yang dapat diprediksi.
Tantangan menjalankan kafka di cloud
Kafka dikembangkan dengan pusat data sebagai target penempatan di LinkedIn. Kami telah melakukan upaya penting untuk membuat kafka berjalan lebih baik di cloud.
Di cloud, contoh memiliki siklus hidup yang tidak terduga dan dapat diakhiri kapan saja karena masalah perangkat keras. Masalah jaringan sementara diharapkan. Ini bukan masalah untuk layanan tanpa kewarganegaraan tetapi menimbulkan tantangan besar bagi layanan stateful yang membutuhkan penjatahan dan pengontrol tunggal untuk koordinasi.
Sebagian besar masalah kami dimulai dengan broker outlier. Pencilan dapat disebabkan oleh beban kerja yang tidak rata, masalah perangkat keras atau lingkungan spesifiknya, misalnya, tetangga yang berisik karena multi-tenancy. Pialang outlier mungkin memiliki respons yang lambat terhadap permintaan atau sering kali tentangan/transmisi TCP. Produser yang mengirim acara ke broker seperti itu akan memiliki peluang bagus untuk menghabiskan buffer lokal mereka sambil menunggu tanggapan, setelah itu macet drop menjadi kepastian. Faktor Kontribusi Lainnya untuk Menyusun Kelelahan adalah bahwa Kafka 0.8.2 produser tidak’t mendukung waktu habis untuk pesan menunggu di buffer.
Kafka’S Replication meningkatkan ketersediaan. Namun, replikasi mengarah pada ketergantungan antar-ketergantungan di antara pialang di mana outlier dapat menyebabkan efek cascading. Jika outlier memperlambat replikasi, lag replikasi dapat menumpuk dan akhirnya menyebabkan para pemimpin partisi membaca dari disk untuk melayani permintaan replikasi. Ini memperlambat broker yang terkena dampak dan akhirnya mengakibatkan produsen menjatuhkan pesan karena buffer yang kelelahan seperti yang dijelaskan dalam kasus sebelumnya.
Selama hari -hari awal kami mengoperasikan kafka, kami mengalami insiden di mana produsen menjatuhkan sejumlah besar pesan ke gugus kafka dengan ratusan contoh karena masalah kebun binatang sementara ada sedikit yang bisa kami lakukan. Debugging masalah seperti ini di jendela waktu kecil dengan ratusan broker sama sekali tidak realistis.
Setelah insiden itu, upaya dilakukan untuk mengurangi keutamaan dan kompleksitas untuk kelompok Kafka kami, mendeteksi outlier, dan menemukan cara untuk memulai dengan cepat dengan keadaan bersih ketika suatu insiden terjadi.
Strategi Penyebaran Kafka
Berikut ini adalah strategi utama yang kami gunakan untuk menggunakan kelompok Kafka:
- Mendukung beberapa kelompok kafka kecil yang bertentangan dengan satu cluster raksasa. Ini mengurangi dependensi dan meningkatkan stabilitas.
- Menerapkan mekanisme deteksi outlier untuk mengidentifikasi dan menangani broker yang bermasalah.
- Kembangkan langkah -langkah untuk segera pulih dari insiden dan mulai dengan keadaan bersih.
Menampilkan Apache Kafka di Netflix Studio and Finance World
Sebagian besar aplikasi di Netflix menggunakan Perpustakaan Klien Java kami untuk memproduksi ke Keystone Pipeline. Pada setiap contoh dari aplikasi tersebut, ada beberapa produsen kafka, dengan masing -masing memproduksi cluster kafka yang fronting untuk isolasi tingkat wastafel. Produsen memiliki routing topik yang fleksibel dan konfigurasi wastafel yang didorong melalui konfigurasi dinamis yang dapat diubah saat runtime tanpa harus memulai kembali proses aplikasi. Ini memungkinkan untuk hal -hal seperti mengarahkan kembali lalu lintas dan migrasi topik di seluruh kluster Kafka. Untuk aplikasi non-java, mereka dapat memilih untuk mengirim acara ke titik akhir istirahat Keystone yang menyampaikan pesan ke fronting kluster kafka.
Kafka di dalam pipa keystone
Kami memiliki dua set kluster Kafka di Keystone Pipeline: Fronting Kafka dan konsumen kafka. Fronting Kafka Clusters bertanggung jawab untuk mendapatkan pesan dari produsen yang hampir setiap contoh aplikasi di Netflix. Peran mereka adalah pengumpulan data dan buffering untuk sistem hilir. Konsumen Kafka Cluster berisi subset topik yang dialihkan oleh Samza untuk konsumen real-time.
Kami saat ini mengoperasikan 36 kluster kafka yang terdiri dari 4.000+ instance broker untuk fronting kafka dan konsumen kafka. Lebih dari 700 miliar pesan dicerna pada hari rata -rata. Kami saat ini sedang beralih dari Kafka Versi 0.8.2.1 hingga 0.9.0.1.
Prinsip desain
Mengingat arsitektur kafka saat ini dan volume data besar kami, untuk mencapai pengiriman lossless untuk pipa data kami adalah penghalang biaya di AWS EC2. Akuntansi untuk ini, kami’VE bekerja dengan tim yang bergantung pada infrastruktur kami untuk mencapai jumlah kehilangan data yang dapat diterima, sambil menyeimbangkan biaya. Kami’VE mencapai tingkat kehilangan data harian kurang dari 0.01%. Metrik dikumpulkan untuk pesan yang dijatuhkan sehingga kami dapat mengambil tindakan jika diperlukan.
Pipa Keystone menghasilkan pesan secara tidak sinkron tanpa memblokir aplikasi. Jika pesan tidak dapat dikirimkan setelah coba lagi, itu akan dijatuhkan oleh produser untuk memastikan ketersediaan aplikasi dan pengalaman pengguna yang baik. Inilah sebabnya kami telah memilih konfigurasi berikut untuk produser dan broker kami:
- ACKS = 1
- memblokir.pada.penyangga.full = false
- najis.pemimpin.pemilihan.aktifkan = true
Sebagian besar aplikasi di Netflix menggunakan Perpustakaan Klien Java kami untuk memproduksi ke Keystone Pipeline. Pada setiap contoh dari aplikasi tersebut, ada beberapa produsen kafka, dengan masing -masing memproduksi cluster kafka yang fronting untuk isolasi tingkat wastafel. Produsen memiliki routing topik yang fleksibel dan konfigurasi wastafel yang didorong melalui konfigurasi dinamis yang dapat diubah saat runtime tanpa harus memulai kembali proses aplikasi. Ini memungkinkan untuk hal -hal seperti mengarahkan kembali lalu lintas dan migrasi topik di seluruh kluster Kafka. Untuk aplikasi non-java, mereka dapat memilih untuk mengirim acara ke titik akhir istirahat Keystone yang menyampaikan pesan ke fronting kluster kafka.
Untuk fleksibilitas yang lebih besar, produsen tidak menggunakan pesan kunci. Perkiraan Pesan Pesan didirikan kembali di lapisan pemrosesan batch (Hive / Elasticsearch) atau lapisan perutean untuk streaming konsumen.
Kami menempatkan stabilitas kelompok kafka fronting kami pada prioritas tinggi karena mereka adalah gerbang untuk injeksi pesan. Oleh karena itu kami tidak mengizinkan aplikasi klien untuk secara langsung mengkonsumsi dari mereka untuk memastikan mereka memiliki beban yang dapat diprediksi.
Tantangan menjalankan kafka di cloud
Kafka dikembangkan dengan pusat data sebagai target penempatan di LinkedIn. Kami telah melakukan upaya penting untuk membuat kafka berjalan lebih baik di cloud.
Di cloud, contoh memiliki siklus hidup yang tidak terduga dan dapat diakhiri kapan saja karena masalah perangkat keras. Masalah jaringan sementara diharapkan. Ini bukan masalah untuk layanan tanpa kewarganegaraan tetapi menimbulkan tantangan besar bagi layanan stateful yang membutuhkan penjatahan dan pengontrol tunggal untuk koordinasi.
Sebagian besar masalah kami dimulai dengan broker outlier. Pencilan dapat disebabkan oleh beban kerja yang tidak rata, masalah perangkat keras atau lingkungan spesifiknya, misalnya, tetangga yang berisik karena multi-tenancy. Pialang outlier mungkin memiliki respons yang lambat terhadap permintaan atau sering kali tentangan/transmisi TCP. Produser yang mengirim acara ke broker seperti itu akan memiliki peluang bagus untuk menghabiskan buffer lokal mereka sambil menunggu tanggapan, setelah itu macet drop menjadi kepastian. Faktor Kontribusi Lainnya untuk Menyusun Kelelahan adalah bahwa Kafka 0.8.2 produser tidak’t mendukung waktu habis untuk pesan menunggu di buffer.
Kafka’S Replication meningkatkan ketersediaan. Namun, replikasi mengarah pada ketergantungan antar-ketergantungan di antara pialang di mana outlier dapat menyebabkan efek cascading. Jika outlier memperlambat replikasi, lag replikasi dapat menumpuk dan akhirnya menyebabkan para pemimpin partisi membaca dari disk untuk melayani permintaan replikasi. Ini memperlambat broker yang terkena dampak dan akhirnya mengakibatkan produsen menjatuhkan pesan karena buffer yang kelelahan seperti yang dijelaskan dalam kasus sebelumnya.
Selama hari -hari awal kami mengoperasikan kafka, kami mengalami insiden di mana produsen menjatuhkan sejumlah besar pesan ke gugus kafka dengan ratusan contoh karena masalah kebun binatang sementara ada sedikit yang bisa kami lakukan. Debugging masalah seperti ini di jendela waktu kecil dengan ratusan broker sama sekali tidak realistis.
Setelah insiden itu, upaya dilakukan untuk mengurangi keutamaan dan kompleksitas untuk kelompok Kafka kami, mendeteksi outlier, dan menemukan cara untuk memulai dengan cepat dengan keadaan bersih ketika suatu insiden terjadi.
Strategi Penyebaran Kafka
Berikut ini adalah strategi utama yang kami gunakan untuk menggunakan kluster Kafka
- Mendukung beberapa kelompok kafka kecil yang bertentangan dengan satu cluster raksasa. Ini mengurangi kompleksitas operasional untuk setiap cluster. Cluster terbesar kami memiliki kurang dari 200 broker.
- Batasi jumlah partisi di setiap cluster. Setiap cluster memiliki kurang dari 10.000 partisi. Ini meningkatkan ketersediaan dan mengurangi latensi untuk permintaan/tanggapan yang terikat pada jumlah partisi.
- Berusaha untuk bahkan distribusi replika untuk setiap topik. Bahkan beban kerja lebih mudah untuk perencanaan kapasitas dan deteksi outlier.
- Gunakan kluster zookeeper khusus untuk setiap cluster kafka untuk mengurangi dampak masalah zookeeper.
Tabel berikut menunjukkan konfigurasi penyebaran kami.
Kafka failover
Kami mengotomatiskan proses di mana kami dapat gagal dalam lalu lintas produsen dan konsumen (router) ke kluster Kafka baru ketika cluster utama dalam masalah. Untuk setiap cluster kafka fronting, ada cluster siaga dingin dengan konfigurasi peluncuran yang diinginkan tetapi kapasitas awal minimal. Untuk menjamin keadaan bersih untuk memulai, cluster failover tidak memiliki topik yang dibuat dan tidak berbagi kluster zookeeper dengan kluster kafka utama. Cluster failover juga dirancang untuk memiliki faktor replikasi 1 sehingga akan bebas dari masalah replikasi apa pun yang mungkin dimiliki cluster asli.
Ketika failover terjadi, langkah -langkah berikut diambil untuk mengalihkan lalu lintas produsen dan konsumen:
- Ubah Ubah Ukuran Cluster Failover ke ukuran yang diinginkan.
- Buat topik di dan luncurkan pekerjaan perutean untuk kluster failover secara paralel.
- (Secara opsional) Tunggu para pemimpin partisi ditetapkan oleh pengontrol untuk meminimalkan penurunan pesan awal saat memproduksinya.
- Ubah secara dinamis konfigurasi produsen untuk mengganti lalu lintas produsen ke kluster failover.
Skenario Failover dapat digambarkan oleh bagan berikut:
Dengan otomatisasi proses yang lengkap, kami dapat melakukan failover dalam waktu kurang dari 5 menit. Setelah failover berhasil selesai, kami dapat men -debug masalah dengan cluster asli menggunakan log dan metrik. Dimungkinkan juga untuk benar -benar menghancurkan cluster dan membangun kembali dengan gambar baru sebelum kami beralih kembali lalu lintas. Faktanya, kami sering menggunakan strategi failover untuk mengalihkan lalu lintas saat melakukan pemeliharaan offline. Beginilah cara kami meningkatkan kluster Kafka kami ke versi kafka baru tanpa harus melakukan peningkatan atau mengatur versi protokol komunikasi antar-broker.
Pengembangan untuk Kafka
Kami mengembangkan cukup banyak alat yang berguna untuk kafka. Berikut beberapa highlight:
Produser Sticky Partitioner
Ini adalah partisi khusus khusus yang telah kami kembangkan untuk Perpustakaan Produser Java kami. Seperti namanya, itu menempel pada partisi tertentu untuk memproduksi waktu yang dapat dikonfigurasi sebelum secara acak memilih partisi berikutnya. Kami menemukan bahwa menggunakan partisi yang lengket bersama -sama dengan Lingering membantu meningkatkan kumpulan pesan dan mengurangi beban untuk broker. Berikut adalah tabel untuk menunjukkan efek partisi yang lengket:
Rack Sadar Replica Tugas
Semua kluster Kafka kami membentang di tiga zona ketersediaan AWS. Zona ketersediaan AWS secara konseptual adalah rak. Untuk memastikan ketersediaan jika satu zona turun, kami mengembangkan penugasan replika rak (zona) sehingga replika untuk topik yang sama ditugaskan ke zona yang berbeda. Ini tidak hanya membantu mengurangi risiko pemadaman zona, tetapi juga meningkatkan ketersediaan kami ketika beberapa broker berlokasi bersama dalam inang fisik yang sama diakhiri karena masalah inang. Dalam hal ini, kami memiliki toleransi kesalahan yang lebih baik daripada Kafka’S n – 1 di mana n adalah faktor replikasi.
Pekerjaan ini berkontribusi pada komunitas Kafka di KIP-36 dan Apache Kafka Github Pull Request #132.
Kafka metadata visualizer
Kafka’S Metadata disimpan di Zookeeperer. Namun, tampilan pohon yang disediakan oleh peserta pameran sulit dinavigasi dan sudah memakan waktu untuk menemukan dan mengkorelasikan informasi.
Kami membuat UI kami sendiri untuk memvisualisasikan metadata. Ini menyediakan bagan dan tampilan tabel dan menggunakan skema warna yang kaya untuk menunjukkan keadaan ISR. Fitur utama adalah sebagai berikut:
- Tab individual untuk tampilan untuk broker, topik, dan cluster
- Sebagian besar informasi dapat diurutkan dan dicari
- Mencari topik di seluruh cluster
- Pemetaan Langsung dari ID Pialang ke ID Instance AWS
- Korelasi broker oleh hubungan pemimpin-pengikut
Berikut ini adalah tangkapan layar UI:
Pemantauan
Kami membuat layanan pemantauan khusus untuk kafka. Itu bertanggung jawab untuk melacak:
- Status broker (khususnya, jika offline dari Zookeeper)
- Makelar’S Kemampuan untuk menerima pesan dari produsen dan mengirimkan pesan kepada konsumen. Layanan pemantauan bertindak sebagai produsen dan konsumen untuk pesan detak jantung yang berkelanjutan dan mengukur latensi pesan -pesan ini.
- Untuk konsumen yang berbasis di zookeeper, ini memantau jumlah partisi untuk kelompok konsumen untuk memastikan setiap partisi dikonsumsi.
- Untuk router Keystone Samza, ini memantau offset yang diantisipasi dan dibandingkan dengan broker’S Offset log untuk memastikan mereka tidak macet dan tidak memiliki kelambatan yang signifikan.
Selain itu, kami memiliki dasbor yang luas untuk memantau arus lalu lintas ke tingkat topik dan sebagian besar broker’S metrik.
Rencana ke depan
Kami saat ini sedang dalam proses migrasi ke kafka 0.9, yang memiliki beberapa fitur yang ingin kami gunakan termasuk API konsumen baru, batas waktu pesan produsen dan kuota. Kami juga akan memindahkan kelompok Kafka kami ke AWS VPC dan percaya bahwa peningkatan jaringan (dibandingkan dengan EC2 Classic) akan memberi kami keunggulan untuk meningkatkan ketersediaan dan pemanfaatan sumber daya.
Kami akan memperkenalkan SLA berjenjang untuk topik. Untuk topik yang dapat menerima kerugian kecil, kami sedang mempertimbangkan untuk menggunakan satu replika. Tanpa replikasi, kami tidak hanya menghemat besar di bandwidth, tetapi juga meminimalkan perubahan keadaan yang harus bergantung pada pengontrol. Ini adalah langkah lain untuk membuat kafka kurang stateful di lingkungan yang mendukung layanan tanpa kewarganegaraan. Kelemahannya adalah potensi kehilangan pesan saat broker hilang. Namun, dengan memanfaatkan batas waktu pesan produser di 0.9 Rilis dan mungkin volume AWS EBS, kita dapat mengurangi kerugian.
Nantikan blog Keystone di masa depan di infrastruktur perutean kami, manajemen kontainer, pemrosesan aliran dan banyak lagi!
Menampilkan Apache Kafka di Netflix Studio and Finance World
Netflix menghabiskan sekitar $ 15 miliar untuk menghasilkan konten asli kelas dunia pada tahun 2019. Ketika taruhannya sangat tinggi, sangat penting untuk memungkinkan bisnis kami dengan wawasan kritis yang membantu merencanakan, menentukan pengeluaran, dan memperhitungkan semua konten Netflix. Wawasan ini dapat mencakup:
- Berapa banyak yang harus kita habiskan di tahun depan untuk film dan seri internasional?
- Apakah kita sedang tren untuk membahas anggaran produksi kita dan apakah ada yang perlu masuk untuk menjaga hal -hal di jalur?
- Bagaimana kami memprogram katalog bertahun -tahun sebelumnya dengan data, intuisi, dan analitik untuk membantu menciptakan batu tulis terbaik yang memungkinkan?
- Bagaimana kami menghasilkan keuangan untuk konten di seluruh dunia dan melapor ke Wall Street?
Mirip dengan bagaimana VC dengan ketat mengarahkan mata mereka untuk investasi yang baik, tim teknik keuangan konten’Piagam adalah membantu Netflix berinvestasi, melacak, dan belajar dari tindakan kami sehingga kami terus melakukan investasi yang lebih baik di masa depan.
Merangkul acara
Dari sudut pandang rekayasa, setiap aplikasi keuangan dimodelkan dan diimplementasikan sebagai layanan mikro. Netflix mencakup tata kelola terdistribusi dan mendorong pendekatan yang digerakkan oleh layanan mikro untuk aplikasi, yang membantu mencapai keseimbangan yang tepat antara abstraksi data dan kecepatan sebagai skala perusahaan. Di dunia yang sederhana, layanan dapat berinteraksi melalui HTTP dengan baik, tetapi saat kita berskala, mereka berevolusi menjadi grafik kompleks interaksi berbasis permintaan yang berpotensi mengarah pada otak split/state dan mengganggu ketersediaan.
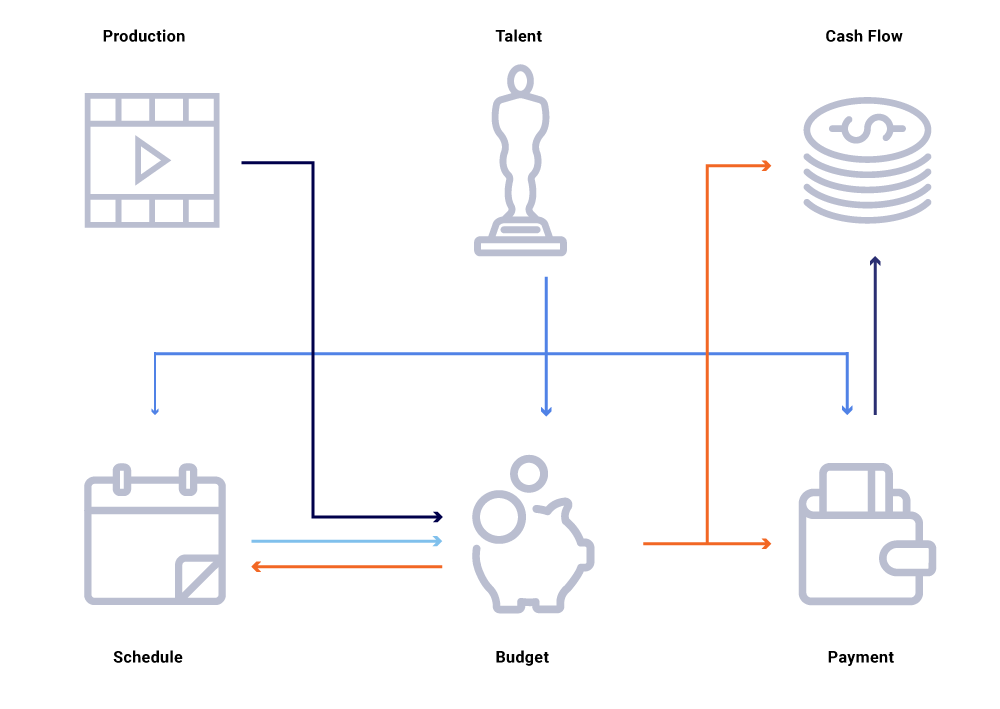
Pertimbangkan dalam grafik entitas terkait di atas, perubahan dalam tanggal produksi sebuah pertunjukan. Ini berdampak pada papan tulis pemrograman kami, yang pada gilirannya mempengaruhi proyek arus kas, pembayaran bakat, anggaran untuk tahun ini, dll. Seringkali dalam arsitektur layanan mikro, beberapa persentase kegagalan dapat diterima. Namun, kegagalan dalam salah satu panggilan layanan mikro untuk rekayasa keuangan konten akan menyebabkan sejumlah besar perhitungan tidak disinkronkan dan dapat mengakibatkan data dibatalkan dengan jutaan dolar. Ini juga akan menyebabkan masalah ketersediaan karena grafik panggilan membentang dan menyebabkan bintik -bintik buta saat mencoba melacak dan menjawab pertanyaan bisnis secara efektif, seperti: mengapa proyeksi arus kas menyimpang dari jadwal peluncuran kami? Mengapa ramalan untuk tahun berjalan tidak memperhitungkan pertunjukan yang sedang dalam pengembangan aktif? Kapan kita dapat mengharapkan laporan biaya kita secara akurat mencerminkan perubahan hulu?
Memikirkan kembali interaksi layanan sebagai aliran pertukaran acara – berbeda dengan urutan permintaan sinkron – marilah kita membangun infrastruktur yang secara inheren asinkron. Itu mempromosikan decoupling dan memberikan keterlacakan sebagai warga negara kelas satu dalam jaringan transaksi terdistribusi. Acara lebih dari sekadar pemicu dan pembaruan. Mereka menjadi aliran yang tidak dapat diubah dari mana kita dapat merekonstruksi seluruh status sistem.
Bergerak menuju model publikasi/berlangganan memungkinkan setiap layanan untuk mempublikasikan perubahannya sebagai peristiwa menjadi bus pesan, yang kemudian dapat dikonsumsi oleh layanan minat lain yang perlu menyesuaikan keadaan dunia. Model seperti itu memungkinkan kami untuk melacak apakah layanan selaras sehubungan dengan perubahan status dan, jika tidak, berapa lama sebelum mereka dapat disinkronkan. Wawasan ini sangat kuat saat mengoperasikan grafik besar layanan dependen. Komunikasi berbasis peristiwa dan konsumsi terdesentralisasi membantu kami mengatasi masalah yang biasanya kami lihat dalam grafik panggilan sinkron besar (seperti yang disebutkan di atas).
Netflix menganut Apache Kafka ® sebagai standar de-facto untuk kebutuhan acara, pesan, dan pemrosesan alirannya. Kafka bertindak sebagai jembatan untuk semua komunikasi luas point-to-point dan Netflix Studio. Ini memberi kita arsitektur multi-tenant yang tinggi dan linear yang diperlukan untuk sistem operasi di Netflix. Kafka in-house kami sebagai penawaran layanan memberikan toleransi kesalahan, kemampuan observasi, penyebaran multi-wilayah, dan swalayan. Hal ini memudahkan seluruh ekosistem layanan microsystem kami untuk dengan mudah memproduksi dan mengonsumsi peristiwa yang bermakna dan melepaskan kekuatan komunikasi yang tidak sinkron.
Pertukaran pesan khas dalam ekosistem Netflix Studio terlihat seperti ini:
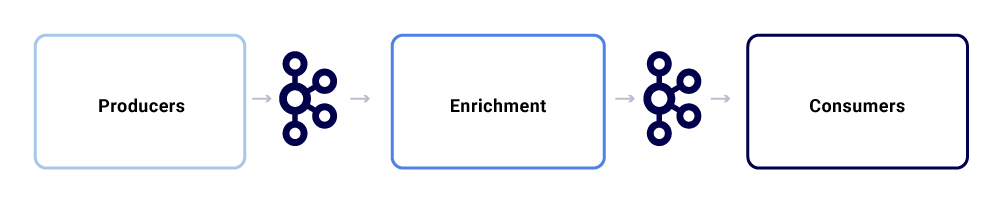
Kita dapat memecahnya sebagai tiga sub-komponen utama.
Produsen
Produser dapat berupa sistem apa pun yang ingin mempublikasikan seluruh status atau mengisyaratkan bahwa bagian penting dari keadaan internalnya telah berubah untuk entitas tertentu. Terlepas dari muatan, suatu peristiwa perlu mematuhi format yang dinormalisasi, yang membuatnya lebih mudah untuk dilacak dan dipahami. Format ini meliputi:
- UUID: Pengidentifikasi unik secara universal
- Jenis: Salah satu jenis Buat, Baca, Perbarui, atau Hapus (CRUD)
- TS: Cap waktu acara
Ubah Alat Pengambilan Data (CDC) adalah kategori lain dari produsen acara yang memperoleh acara dari perubahan database. Ini bisa berguna saat Anda ingin membuat perubahan database tersedia untuk banyak konsumen. Kami juga menggunakan pola ini untuk mereplikasi data yang sama di seluruh pusat data (untuk database master tunggal). Contohnya adalah ketika kami memiliki data di MySQL yang perlu diindeks di Elasticsearch atau Apache Solr ™. Manfaat menggunakan CDC adalah tidak memaksakan beban tambahan pada aplikasi sumber.
Untuk acara CDC, bidang tipe dalam format acara membuatnya mudah untuk beradaptasi dan mengubah peristiwa seperti yang diperlukan oleh wastafel masing -masing.
Pengayaan
Setelah data ada di kafka, berbagai pola konsumsi dapat diterapkan padanya. Acara digunakan dalam banyak hal, termasuk sebagai pemicu untuk perhitungan sistem, transfer payload untuk komunikasi hampir-real-time, dan isyarat untuk memperkaya dan mewujudkan pandangan dalam memori data.
Pengayaan data menjadi semakin umum di mana layanan mikro membutuhkan tampilan penuh dari dataset tetapi bagian dari data berasal dari layanan lain’S Dataset. Dataset yang bergabung dapat berguna untuk meningkatkan kinerja kueri atau memberikan tampilan waktu yang hampir real-waktu dari data agregat. Untuk memperkaya data acara, konsumen membaca data dari kafka dan hubungi layanan lain (menggunakan metode yang mencakup GRPC dan GraphQL) untuk membangun dataset yang bergabung, yang kemudian diumpankan ke topik kafka lainnya.
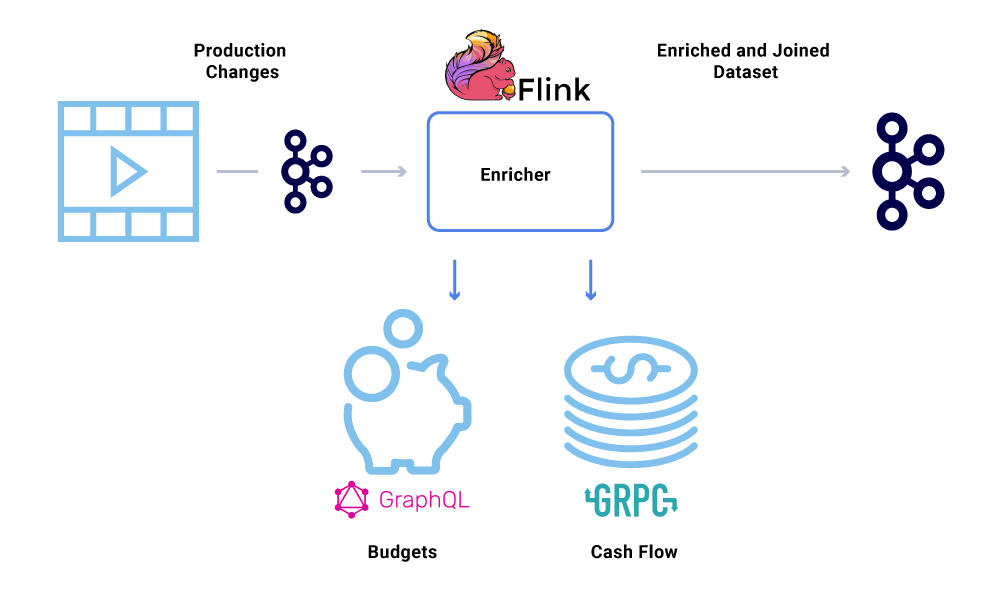
Pengayaan dapat dijalankan sebagai layanan mikro terpisah di dalamnya sendiri yang bertanggung jawab untuk melakukan fan-out dan untuk mewujudkan set data. Ada kasus di mana kami ingin melakukan pemrosesan yang lebih kompleks seperti windowing, sessionisasi, dan manajemen negara. Untuk kasus seperti itu, disarankan untuk menggunakan mesin pemrosesan aliran yang matang di atas kafka untuk membangun logika bisnis. Di Netflix, kami menggunakan Apache Flink ® dan RockSDB untuk melakukan pemrosesan aliran. Kami’juga mempertimbangkan ksqldb untuk tujuan yang sama.
Memesan acara
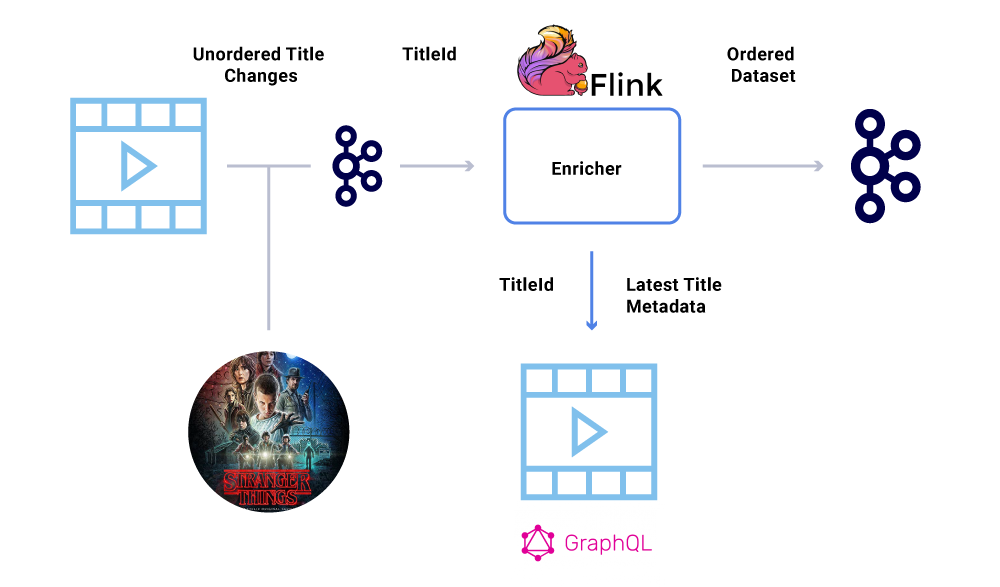
Salah satu persyaratan utama dalam dataset keuangan adalah pemesanan peristiwa yang ketat. Kafka membantu kita mencapai ini adalah dengan mengirim pesan kunci. Acara atau pesan apa pun yang dikirim dengan kunci yang sama, akan dijamin pemesanan karena dikirim ke partisi yang sama. Namun, produsen masih bisa mengacaukan pemesanan acara.
Misalnya, tanggal peluncuran “Hal -hal asing” Awalnya dipindahkan dari Juli hingga Juni tetapi kemudian kembali dari Juni hingga Juli. Karena berbagai alasan, peristiwa ini dapat ditulis dalam urutan yang salah untuk Kafka (batas waktu jaringan ketika produser mencoba mencapai Kafka, bug konkurensi dalam kode produser, dll). Cegukan pemesanan bisa sangat memengaruhi berbagai perhitungan keuangan.
Untuk menghindari skenario ini, produsen didorong untuk mengirim ID utama entitas yang telah berubah dan bukan muatan penuh dalam pesan kafka. Proses pengayaan (dijelaskan di bagian di atas) menanyakan layanan sumber dengan ID entitas untuk mendapatkan status/muatan terkini, sehingga memberikan cara yang elegan untuk menghindari masalah di luar pesanan. Kami merujuk ini sebagai materialisasi tertunda, dan itu menjamin kumpulan data yang dipesan.
Konsumen
Kami menggunakan boot musim semi untuk mengimplementasikan banyak layanan mikro yang dikonsumsi yang dibaca dari topik kafka. Spring Boot menawarkan konsumen kafka bawaan yang disebut konektor kafka musim semi, yang membuat konsumsi mulus, memberikan cara mudah untuk memasang anotasi untuk konsumsi dan deserialisasi data.
Salah satu aspek dari data yang kami miliki’t didiskusikan adalah kontrak. Saat kami mengurangi penggunaan aliran acara, kami berakhir dengan berbagai kelompok dataset, beberapa di antaranya dikonsumsi oleh sejumlah besar aplikasi. Dalam kasus ini, mendefinisikan skema pada output sangat ideal dan membantu memastikan kompatibilitas mundur. Untuk melakukan ini, kami memanfaatkan registri skema konfluen dan Apache Avro ™ untuk membangun aliran skema kami untuk melakukan aliran data versi aliran data.
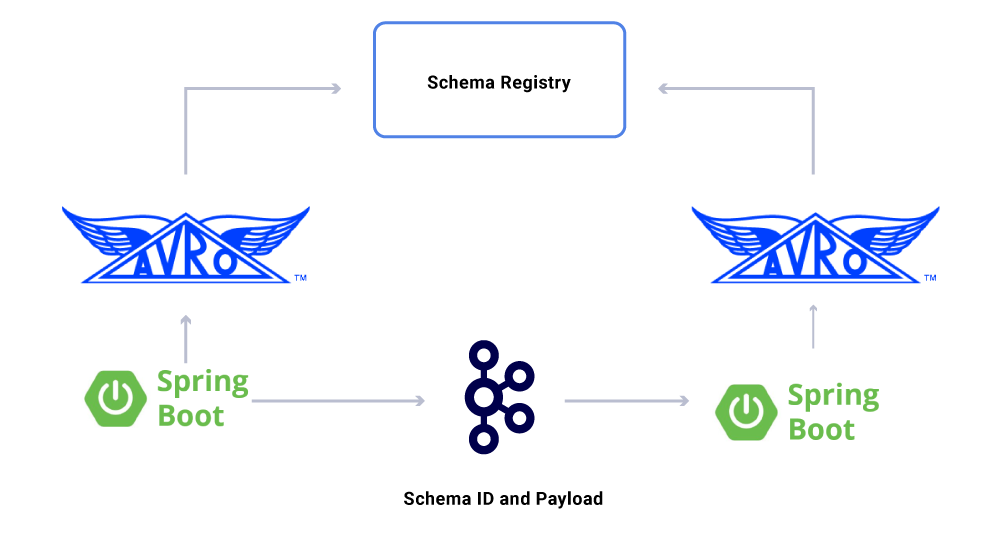
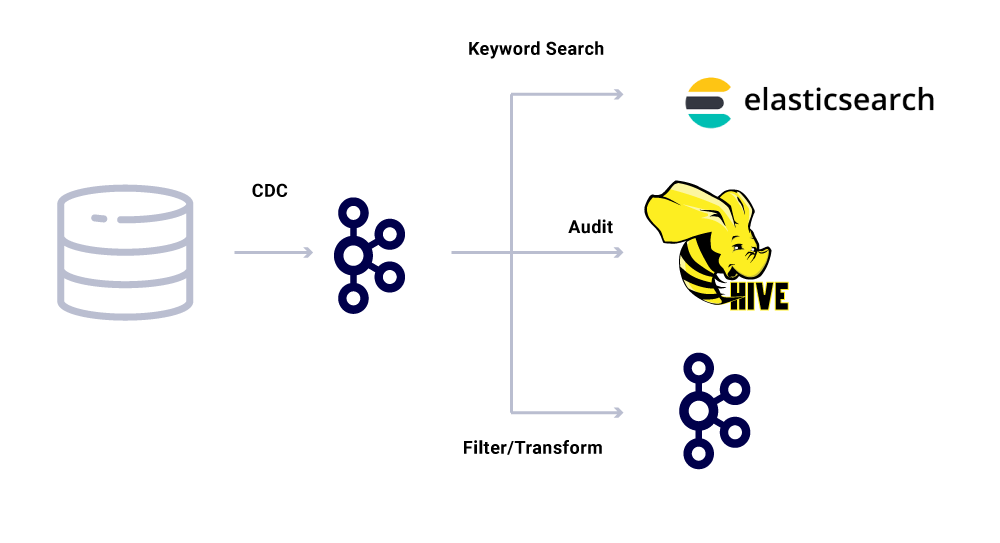
Selain konsumen layanan mikro yang berdedikasi, kami juga memiliki wastafel CDC yang mengindeks data ke dalam berbagai toko untuk analisis lebih lanjut. Ini termasuk Elasticsearch untuk pencarian kata kunci, Apache Hive ™ untuk audit, dan kafka sendiri untuk pemrosesan hilir lebih lanjut. Payload untuk wastafel tersebut secara langsung berasal dari pesan kafka dengan menggunakan bidang ID sebagai kunci dan jenis utama untuk mengidentifikasi operasi CRUD.
Jaminan pengiriman pesan
Menjamin persis setelah pengiriman dalam sistem terdistribusi tidak trivial karena kompleksitas yang terlibat dan sejumlah besar bagian yang bergerak. Konsumen harus memiliki perilaku idempoten untuk menjelaskan potensi infrastruktur dan kecelakaan produsen.
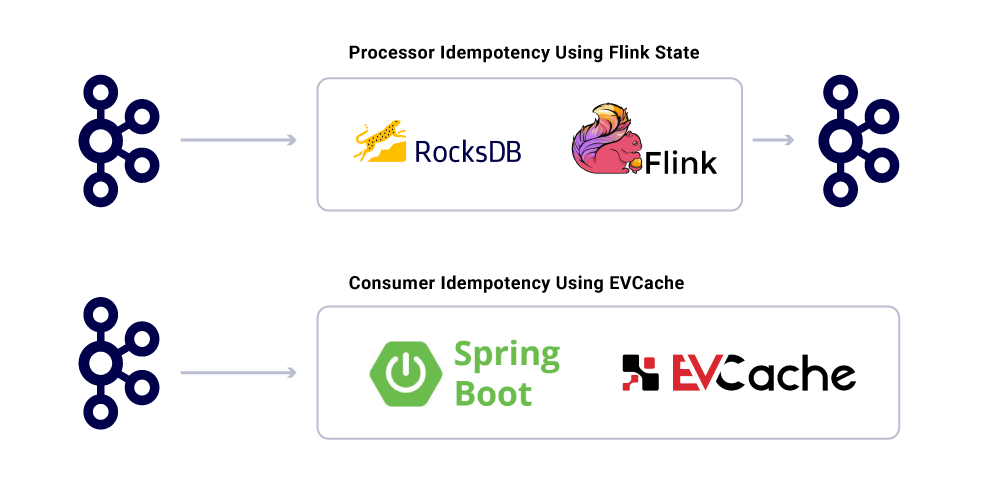
Terlepas dari kenyataan bahwa aplikasi itu idempoten, mereka tidak boleh mengulangi operasi berat untuk pesan yang sudah diproses. Cara populer untuk memastikan ini adalah untuk melacak uuid pesan yang dikonsumsi oleh layanan dalam cache terdistribusi dengan kedaluwarsa yang wajar (didefinisikan berdasarkan Perjanjian Level Layanan (SLA). Kapan saja UUID yang sama ditemui dalam interval kedaluwarsa, pemrosesan dilewati.
Pemrosesan dalam Flink memberikan jaminan ini dengan menggunakan manajemen negara bagian berbasis rocksdb internal, dengan kunci menjadi UUID dari pesan tersebut. Jika Anda ingin melakukan ini murni menggunakan kafka, kafka streams menawarkan cara untuk melakukannya juga. Mengkonsumsi aplikasi berdasarkan EVCACH Penggunaan Spring Boot untuk mencapai ini.
Memantau Tingkat Layanan Infrastruktur
Dia’sangat penting bagi Netflix untuk memiliki pandangan real-time tentang tingkat layanan dalam infrastrukturnya. Netflix menulis Atlas untuk mengelola data seri waktu dimensi, dari mana kami menerbitkan dan memvisualisasikan metrik. Kami menggunakan berbagai metrik yang diterbitkan oleh produsen, prosesor, dan konsumen untuk membantu kami membangun gambaran yang hampir menyenangkan dari seluruh infrastruktur.
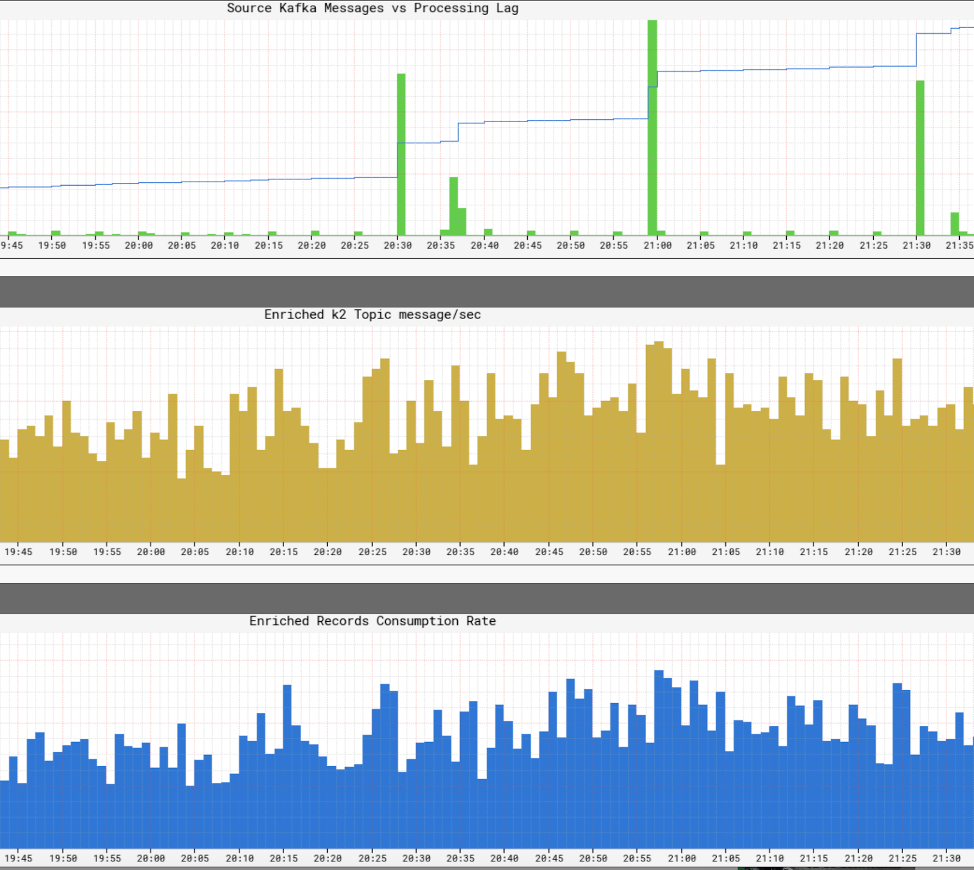
Beberapa aspek utama yang kami pantau adalah:
- Kesegaran SLA
- Berapa akhir dari akhir dari produksi suatu acara sampai mencapai semua wastafel?
- Apa kelambatan pemrosesan untuk setiap konsumen?
- Seberapa besar muatan yang dapat kami kirim?
- Haruskah kita mengompres data?
- Apakah kita secara efisien memanfaatkan sumber daya kita?
- Bisakah kita mengkonsumsi lebih cepat?
- Apakah kami dapat membuat pos pemeriksaan untuk negara bagian kami dan melanjutkan dalam hal kegagalan?
- Jika kami tidak dapat mengikuti acara Firehose, dapatkah kami menerapkan tekanan balik ke sumber yang sesuai tanpa menabrak aplikasi kami?
- Bagaimana kita menangani semburan acara?
- Apakah kita cukup disediakan untuk memenuhi SLA?
Ringkasan
Tim Produksi dan Keuangan Netflix Studio merangkul tata kelola yang didistribusikan sebagai cara arsitektur sistem. Kami menggunakan kafka sebagai platform pilihan kami untuk bekerja dengan acara, yang merupakan cara abadi untuk merekam dan mendapatkan status sistem. Kafka telah membantu kami mencapai tingkat visibilitas dan decoupling yang lebih besar dalam infrastruktur kami sambil membantu kami secara organik mengurangi operasi. Ini adalah jantung dari merevolusi infrastruktur Netflix Studio dan dengan itu, industri film.
Tertarik lebih banyak?
Jika kamu’D ingin tahu lebih banyak, Anda dapat melihat perekaman dan slide Kafka Summit Summit San Francisco Presentation My Eventation Things – A Netflix Asli!
Netflix: Bagaimana Apache Kafka mengubah data dari jutaan orang menjadi kecerdasan
Netflix menghabiskan $ 16 miliar untuk produksi konten pada tahun 2020. Pada Januari 2021, aplikasi seluler Netflix (iOS dan Android) diunduh 19 juta kali dan sebulan kemudian, perusahaan mengumumkan bahwa mereka telah mencapai 203.66 juta pelanggan di seluruh dunia. Dia’aman untuk mengasumsikan bahwa skala data yang dikumpulkan dan diproses perusahaan. Pertanyaannya adalah –
Bagaimana Netflix memproses miliaran catatan data dan peristiwa untuk membuat keputusan bisnis yang kritis?
Dengan anggaran konten tahunan senilai $ 16 miliar, pembuat keputusan di Netflix Aren’T akan membuat keputusan terkait konten berdasarkan intuisi. Sebaliknya, kurator konten mereka menggunakan teknologi mutakhir untuk memahami sejumlah besar data tentang perilaku pelanggan, preferensi konten pengguna, biaya produksi konten, jenis konten yang berfungsi, dll. Daftar ini terus berlanjut.
Pengguna Netflix menghabiskan rata -rata 3.2 jam sehari di platform mereka dan terus diberi makan dengan rekomendasi terbaru oleh Netflix’S Demoki mesin rekomendasi. Ini memastikan bahwa churn pelanggan rendah dan menarik pelanggan baru untuk mendaftar. Pengiriman konten berbasis data ada di depan dan tengah ini.
Jadi, apa yang ada di bawah kap dari perspektif pemrosesan data?
Dengan kata lain, bagaimana Netflix membangun tulang punggung teknologi yang memungkinkan pengambilan keputusan berbasis data pada skala besar seperti itu? Bagaimana seseorang memahami perilaku pengguna 203 juta pelanggan?
Netflix menggunakan apa yang disebut pipa data Keystone. Pada tahun 2016, pipa ini memproses 500 miliar acara per hari. Acara ini termasuk log kesalahan, aktivitas menonton pengguna, aktivitas UI, acara pemecahan masalah dan banyak set data berharga lainnya.
Menurut Netflix, seperti yang diterbitkan di blog teknologinya:
Pipa Keystone adalah infrastruktur penerbitan, pengumpulan, dan perutean acara terpadu untuk pemrosesan batch dan stream.
Cluster Kafka adalah bagian inti dari pipa data Keystone di Netflix. Pada tahun 2016, pipa Netflix menggunakan 36 kelompok kafka untuk memproses miliaran pesan per hari.
Jadi, apa itu Apache Kafka? Dan, mengapa itu menjadi begitu populer?
Apache Kafka adalah platform streaming sumber terbuka yang memungkinkan pengembangan aplikasi yang menelan volume data waktu nyata yang tinggi. Awalnya dibangun oleh para jenius di LinkedIn dan sekarang digunakan di Netflix, Pinterest dan Airbnb untuk beberapa nama.
Kafka secara khusus melakukan empat hal:
- Ini memungkinkan aplikasi untuk mempublikasikan atau berlangganan aliran data atau acara
- Ini menyimpan catatan data secara akurat dan sangat toleran terhadap kesalahan
- Ini mampu pemrosesan data volume tinggi real-time.
- Itu dapat mengambil dan memproses triliunan catatan data per hari, tanpa masalah kinerja
Tim pengembangan perangkat lunak dapat memanfaatkan kafka’Kemampuan S dengan API berikut:
- Produser API: API ini memungkinkan layanan mikro atau aplikasi untuk mempublikasikan aliran data ke topik kafka tertentu. Topik Kafka adalah log yang menyimpan data dan catatan acara dalam urutan yang terjadi.
- API Konsumen: API ini memungkinkan aplikasi untuk berlangganan aliran data dari topik kafka. Menggunakan API konsumen, aplikasi dapat menelan dan memproses aliran data, yang akan berfungsi sebagai input ke aplikasi yang ditentukan.
- Streams API: API ini sangat penting untuk data streaming data dan acara yang canggih. Pada dasarnya, ia mengkonsumsi aliran data dari berbagai topik kafka dan dapat memproses atau mengubahnya sesuai kebutuhan. Post-Processing, aliran data ini diterbitkan ke topik kafka lain yang akan digunakan hilir dan/atau mengubah topik yang ada.
- Connector API: Dalam aplikasi modern, ada kebutuhan konstan untuk menggunakan kembali produsen atau konsumen dan secara otomatis mengintegrasikan sumber data ke dalam cluster kafka. Kafka connect membuat ini tidak perlu menghubungkan kafka ke sistem eksternal.
Manfaat Utama Kafka
Menurut situs web Kafka, 80% dari semua perusahaan Fortune 100 menggunakan kafka. Salah satu alasan terbesar untuk ini adalah cocok dengan aplikasi yang sangat penting.
Perusahaan besar menggunakan kafka karena alasan berikut:
- Ini memungkinkan decoupling aliran data dan sistem dengan mudah
- Ini dirancang untuk didistribusikan, tangguh dan toleran terhadap kesalahan
- Skalabilitas horizontal kafka adalah salah satu keunggulan terbesarnya. Itu dapat skala hingga 100 -an cluster dan jutaan pesan per detik
- Ini memungkinkan streaming data real-time berkinerja tinggi, kebutuhan kritis dalam skala besar, aplikasi berbasis data
Cara kafka digunakan untuk mengoptimalkan pemrosesan data
Kafka sedang digunakan di seluruh industri untuk berbagai tujuan, termasuk tetapi tidak terbatas pada yang berikut ini
- Pemrosesan data real-time: Selain penggunaannya di perusahaan teknologi, Kafka adalah bagian integral dari pemrosesan data real-time di industri manufaktur, di mana data volume tinggi berasal dari sejumlah besar perangkat IoT dan sensor
- Pemantauan situs web pada skala: Kafka digunakan untuk melacak perilaku pengguna dan aktivitas situs di situs web dengan lalu lintas tinggi. Ini membantu dengan pemantauan waktu nyata, pemrosesan, menghubungkan dengan Hadoop, dan pergudangan data offline
- Melacak metrik kunci: Karena kafka dapat digunakan untuk menggabungkan data dari berbagai aplikasi ke pakan terpusat, ia memfasilitasi pemantauan data operasional volume tinggi
- Agregasi log: Ini memungkinkan data dari berbagai sumber dikumpulkan menjadi log untuk mendapatkan kejelasan tentang konsumsi terdistribusi
- Sistem Pesan: Ini mengotomatiskan aplikasi pemrosesan pesan skala besar
- Pemrosesan Stream: Setelah topik kafka dikonsumsi sebagai data mentah dalam memproses saluran pipa pada berbagai tahap, itu dikumpulkan, diperkaya, atau diubah menjadi topik baru untuk konsumsi atau pemrosesan lebih lanjut
- Ketergantungan sistem de-coupling
- Integrasi Dengan Spark, Flink, Storm, Hadoop, dan teknologi data besar lainnya
Perusahaan yang menggunakan kafka untuk memproses data
Sebagai hasil dari keserbagunaan dan fungsinya, kafka digunakan oleh beberapa dunia’Perusahaan teknologi dengan pertumbuhan tercepat untuk berbagai tujuan:
- Uber-Kumpulkan data pengguna, taksi, dan perjalanan secara real-time untuk menghitung dan memperkirakan permintaan dan menghitung harga lonjakan secara real-time
- LinkedIn-Mencegah spam dan mengumpulkan interaksi pengguna untuk membuat rekomendasi koneksi yang lebih baik secara real-time
- Twitter – bagian dari infrastruktur pemrosesan aliran badai
- Spotify – bagian dari sistem pengiriman log
- Pinterest – bagian dari pipa koleksi lognya
- Airbnb – Pipa acara, pelacakan pengecualian, dll.
- Cisco – untuk OpenSoc (Pusat Operasi Keamanan)
Grup prestasi’keahlian di kafka
Di Merit Group, kami bekerja dengan beberapa dunia’Perusahaan intelijen B2B terkemuka seperti Wilmington, Dow Jones, Glenigan, dan Haymarket. Tim data dan teknik kami bekerja sama dengan klien kami untuk membangun produk data dan alat intelijen bisnis. Pekerjaan kami secara langsung berdampak pada pertumbuhan bisnis dengan membantu klien kami mengidentifikasi peluang pertumbuhan tinggi.
Layanan spesifik kami termasuk pengumpulan data volume tinggi, transformasi data menggunakan AI dan ML, menonton web, dan pengembangan aplikasi yang disesuaikan.
Tim kami juga membawa keahlian ke dalam keahlian mendalam dalam membangun streaming data real-time dan aplikasi pemrosesan data. Keahlian kami di Kafka sangat berguna dalam konteks ini.
Публикацram частника konfluen
Untuk sistem arsitek yang merekam dan mendapatkan status sistem, Netflix memanfaatkan Apache Kafka dan tata kelola terdistribusi. Nitin s. Berbagi bagaimana ini membantu mereka mencapai visibilitas dan decoupling dalam infrastruktur mereka saat secara organik meningkatkan operasi: https: // lnkd.di/gfxaa6g
Bagaimana Netflix Menggunakan Kafka untuk Streaming Terdistribusi
anak sungai.io
- Копировать
Orang percaya, suami, ayah dari 5, manajer infrastruktur dan layanan TI, pemimpin tim, pengembang.
Netflix membangun platform yang andal dan dapat diskalakan dengan sumber acara, MQTT dan Alpakka-kafka
Netflix baru-baru ini menerbitkan posting blog yang merinci cara membangun platform manajemen perangkat yang andal menggunakan implementasi sumber acara berbasis MQTT. Untuk mengukur solusinya, Netflix menggunakan Apache Kafka, Alpakka-Kafka dan Cockroachdb.
Platform manajemen perangkat Netflix adalah sistem yang mengelola perangkat perangkat keras yang digunakan untuk pengujian otomatis aplikasinya. Insinyur Netflix Benson Ma dan Alok Ahuja menggambarkan perjalanan yang dilalui platform:
Pemrosesan aliran kafka bisa sulit untuk diperbaiki. (. ) Untungnya, primitif yang disediakan oleh Akka Streams dan Alpakka-Kafka memberdayakan kami untuk mencapai hal ini dengan memungkinkan kami membangun solusi streaming yang sesuai dengan alur kerja bisnis yang kami miliki saat meningkatkan produktivitas pengembang dalam membangun dan mempertahankan solusi ini. Dengan prosesor berbasis alpakka-kafka di tempat (. ), kami telah memastikan toleransi kesalahan di sisi konsumen bidang kontrol, yang merupakan kunci untuk memungkinkan agregasi status perangkat perangkat yang akurat dan andal dalam platform manajemen perangkat.
(. ) Keandalan platform dan pesawat kontrolnya bertumpu pada pekerjaan signifikan yang dibuat di beberapa bidang, termasuk transportasi MQTT, otentikasi dan otorisasi, dan pemantauan sistem. (. ) Sebagai hasil dari pekerjaan ini, kami dapat mengharapkan platform manajemen perangkat untuk terus meningkatkan peningkatan beban kerja dari waktu ke waktu saat kami berada di atas lebih banyak perangkat ke dalam sistem kami.
Diagram berikut menggambarkan arsitektur.

Sumber: https: // netflixtechblog.com/menuju-A-BANTUAN-Device-Management-Platform-4F86230CA623
Komputer tertanam Lingkungan Referensi Lokal (RAE) terhubung ke beberapa perangkat yang diuji (DUT). Layanan Registri Lokal bertanggung jawab untuk mendeteksi, onboarding, dan mempertahankan informasi tentang semua perangkat yang terhubung di RAE. Saat atribut dan properti perangkat berubah dari waktu ke waktu, ia menyimpan perubahan ini pada registri lokal dan secara bersamaan diterbitkan hulu ke bidang kontrol berbasis cloud. Selain perubahan atribut, registri lokal menerbitkan snapshot lengkap dari catatan perangkat secara berkala. Peristiwa pos pemeriksaan ini memungkinkan rekonstruksi keadaan yang lebih cepat oleh konsumen umpan data sambil menjaga agar tidak ada pembaruan yang terlewat.
Pembaruan diterbitkan ke cloud menggunakan MQTT. MQTT adalah protokol pesan standar oasis untuk Internet of Things (IoT). Ini adalah publikasi/berlangganan pengiriman pesan transportasi yang ringan namun andal untuk menghubungkan perangkat jarak jauh dengan jejak kode kecil dan bandwidth jaringan minimal. Pialang MQTT bertanggung jawab untuk menerima semua pesan, menyaringnya, dan mengirimkannya ke klien yang berlangganan sesuai.
Netflix menggunakan Apache Kafka di seluruh organisasi. Akibatnya, sebuah jembatan mengubah pesan MQTT ke catatan kafka. Ini menetapkan kunci rekaman ke topik MQTT bahwa pesan tersebut ditetapkan. Ma dan Ahuja menjelaskan bahwa “karena pembaruan perangkat yang diterbitkan di MQTT berisi device_session_id Dalam topik, semua pembaruan informasi perangkat untuk sesi perangkat yang diberikan akan secara efektif muncul pada partisi kafka yang sama, sehingga memberi kami pesanan pesan yang jelas untuk dikonsumsi.”
Registri cloud mencerna pesan yang dipublikasikan, memprosesnya, dan mendorong data yang terwujud ke dalam datastore yang didukung oleh CokroachDB. Cokroachdb adalah implementasi dari kelas sistem RDBMS yang disebut newsql. Ma dan Ahuja menjelaskan pilihan Netflix:
CokroachDB dipilih sebagai penyimpanan data dukungan karena menawarkan kemampuan SQL, dan model data kami untuk catatan perangkat dinormalisasi. Selain itu, tidak seperti toko SQL lainnya, CokroachDB dirancang dari bawah ke atas untuk dapat diukur secara horizontal, yang membahas kekhawatiran kami tentang kemampuan Cloud Registry untuk meningkatkan jumlah perangkat yang ada di platform manajemen perangkat perangkat.
Diagram berikut menunjukkan pipa pemrosesan kafka yang terdiri dari registri cloud.
Sumber: https: // netflixtechblog.com/menuju-A-BANTUAN-Device-Management-Platform-4F86230CA623
Netflix mempertimbangkan banyak kerangka kerja untuk mengimplementasikan pipa pemrosesan aliran yang digambarkan di atas. Kerangka kerja ini termasuk aliran kafka, kafkalisterer musim semi, reaktor proyek, dan flink. Akhirnya memilih alpakka-kafka. Alasan untuk pilihan ini adalah bahwa alpakka-kafka menyediakan integrasi boot musim semi bersama dengan “kontrol berbutir halus atas pemrosesan aliran, termasuk dukungan tekanan balik otomatis dan pengawasan aliran.”Selanjutnya, menurut Ma dan Ahuja, Akka dan Alpakka-kafka lebih ringan daripada alternatif, dan karena mereka lebih matang, biaya pemeliharaan dari waktu ke waktu akan lebih rendah.
Implementasi Berbasis Alpakka-Kafka menggantikan implemntation berbasis Kafkalistener Spring sebelumnya. Metrik diukur pada implementasi produksi baru mengungkapkan bahwa dukungan tekanan balik asli Alpakka-Kafka dapat secara dinamis mengukur konsumsi kafka-nya. Tidak seperti Kafkalistener, alpakka-kafka tidak kurang memakan atau menghabiskan terlalu banyak pesan kafka. Juga, penurunan nilai lag konsumen maksimum setelah rilis mengungkapkan bahwa alpakka-kafka dan kemampuan streaming Akka berkinerja baik pada skala, bahkan dalam menghadapi beban pesan mendadak.

