


F # a-t-il un avenir
F # 5: Une nouvelle ère de programmation fonctionnelle avec .FILET
Résumé:
1. F # 5 est la prochaine version majeure de la langue F #.
2. F # 5 marque la fin de l’ère actuelle et le début d’un nouveau.
3. F # 5 se concentre sur la programmation interactive, la programmation orientée analytique et la programmation fonctionnelle.
4. F # Interactive (FSI) est un outil développé pour le développement itératif et interactif.
5. F # 5 maintient les expériences fondamentales du FSI, y compris les assemblages de référence et d’appel.
6. La prise en charge de la gestion des packages est introduite dans FSI, permettant une référence plus facile des packages NuGet.
7. F # 5 prend désormais en charge la référence à tout package NuGet dans un script F #.
8. FSI restaure et fait référence automatiquement tous les assemblages dans le package.
9. F # 5 présente DOTNET FSI, rendant FSI disponible sur macOS et Linux.
dix. F # La prise en charge est ajoutée dans Jupyter Notebooks pour la programmation interactive.
Questions uniques:
1. Qu’est-ce que F # 5?
Répondre: F # 5 est la prochaine version majeure de la langue F #.
2. Qu’est-ce que F # 5 marque la fin de?
Répondre: F # 5 marque la fin de l’ère actuelle.
3. Quels sont les trois principaux domaines d’intérêt pour F # 5?
Répondre: Les trois principaux domaines d’intérêt pour F # 5 sont la programmation interactive, la programmation orientée analytique et la programmation fonctionnelle.
4. Qu’est-ce que F # Interactive (FSI)?
Répondre: FSI est un outil développé pour le développement itératif et interactif à l’aide de F #.
5. Quelles expériences F # 5 maintient à partir de FSI?
Répondre: F # 5 maintient les expériences fondamentales du FSI, y compris les assemblages de référence et d’appel.
6. Que permet le support de gestion des packages dans FSI?
Répondre: La prise en charge de la gestion des packages dans FSI permet un référencement plus facile des packages NuGet dans les scripts F #.
7. Comment F # 5 prend-il en charge les packages NuGet référencés?
Répondre: F # 5 permet de référence à n’importe quel package NuGet dans un script F #, et FSI restaure et fait référence automatiquement tous les assemblages dans le package.
8. Qu’est-ce que Dotnet FSI?
Répondre: Dotnet FSI est une commande qui rend FSI disponible sur macOS et Linux.
9. Quel support supplémentaire F # 5 introduit-t-il pour la programmation interactive?
Répondre: F # 5 introduit la prise en charge F # dans Jupyter Notebooks pour la programmation interactive.
dix. Comment la programmation interactive dans F # a-t-elle récemment changé?
Répondre: La programmation interactive dans F # s’est étendue avec l’introduction de la gestion des packages, du DotNet FSI et de la prise en charge F # dans Jupyter Notebooks.
11. Quelle est la signification de F # 1.0 et FSI?
Répondre: F # 1.0 était la version initiale de la langue F #, et FSI (F # Interactive) a été développé à côté pour un développement interactif.
12. Quelles plates-formes sont maintenant disponibles sur?
Répondre: FSI est maintenant disponible sur macOS et Linux, en plus de Windows.
13. Comment F # 5 facilite-t-il la gestion des packages?
Répondre: F # 5 simplifie la gestion des packages en permettant une référence facile des packages NuGet et en manipulant automatiquement leurs assemblages.
14. Quel est le but de Dotnet FSI?
Répondre: DOTNET FSI permet l’utilisation de FSI pour toutes les mêmes tâches sur macOS et Linux comme sur Windows.
15. Comment F # 5 reconnaît-il et gère les différents types de packages?
Répondre: F # 5 peut gérer les packages avec des dépendances et des packages natifs qui nécessitent un ordre de référence d’assemblage spécifique dans FSI.
F # Langage de programmation: histoire, avantages et possibilités futures
Multiples
Type Exception =
Nouveau: unité -> Exception + 2 surcharges
Données des membres: idictionnaire
Membre GetBaseException: unité -> Exception
membre getObjectData: info: SerializationInfo * Contexte: StreamingContext -> Unité
Membre GetType: Unité -> Type
Membre HELLPLINK: String with Get, définissez
membre inserexception: exception
Message du membre: chaîne
Source du membre: chaîne avec get, définir
membre stackTrace: chaîne
.
F # 5: Une nouvelle ère de programmation fonctionnelle avec .FILET
Dans l’équipe F # de Microsoft, nous améliorons constamment le langage F # pour permettre aux développeurs de faire des programmes fonctionnels .FILET. Au cours des quatre sorties précédentes, de 2017 jusqu’à présent, nous avons fait un long voyage pour faire de F # génial sur .Noyau net. Nous avons réorganisé le compilateur F # et la bibliothèque de base pour exécuter la plate-forme multiplateuse, ajouté une prise en charge de la programmation de span et de bas niveau et multiplateforme, et ajouté la possibilité de prévisualiser les fonctionnalités linguistiques qui peuvent expédier avec .Versions de prévisualisation net.
Avec le .Net 5 Release, nous sortons F # 5, la prochaine version principale de la langue F #. Mais F # 5 n’est pas seulement un paquet de fonctionnalités qui se présente pour la balade avec .Net 5. F # 5 marque la fin de l’ère actuelle ? soutenir le soutien de .Noyau net ? Et le début d’un nouveau. Avec F # 5, nous envisageons notre voyage pour apporter f # à .Net Core principalement complet. Avec F # 5, notre concentration passe de .Net Core vers trois grands domaines:
- Programmation interactive
- Rendre la programmation orientée analytique pratique et amusante
- Grands fondamentaux et performances pour la programmation fonctionnelle sur .FILET
Dans cet article, je vais passer par les fonctionnalités de langue F # et d’outillage que nous avons implémentées pour F # 5 et expliquer comment ils s’alignent sur nos objectifs.
F # 5 fait de la programmation interactive une joie
F # a une longue histoire d’être interactive. En fait, lorsque F # 1.0 a été développé, un outil appelé F # Interactive (FSI) a été développé pour la version éventuelle de F # 1.0 en 2006. Cela a coïncidé avec la première intégration d’outillage dans Visual Studio. FSI a été utilisé assez fortement dans la commercialisation initiale de F # (comme indiqué dans Figure 1) pour démontrer le développement itératif et interactif des applications Windows Forms, des scènes graphiques et des jeux sur Windows.
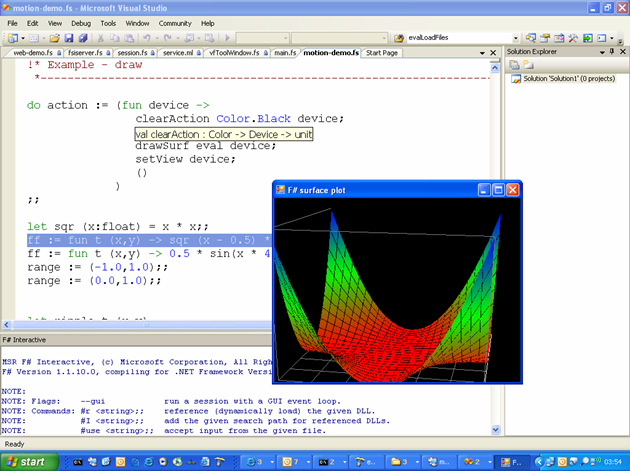
Les expériences fondamentales de FSI sont restées en grande partie les mêmes dans F # 5. Ceux-ci inclus:
- La possibilité de référencer et d’appeler dans des assemblages sur votre ordinateur
- La possibilité de charger d’autres scripts F # à exécuter en tant que collection de scripts
- Intégration avec Visual Studio
- La possibilité de personnaliser la sortie
Cependant, comme F # et le .L’écosystème net est passé des assemblages sur un ordinateur vers des packages installés via un gestionnaire de packages, de nombreux développeurs F # utilisant FSI pour diverses tâches se sont retrouvés ennuyés en ayant à télécharger manuellement un package et à référencer ses assemblages manuellement. De plus, comme .La portée de Net s’étendait au-delà.
Présentation du support de gestion des packages dans FSI
L’utilisation d’un package dans un script F # est depuis longtemps une source de frustration pour les programmeurs F #. Ils ont généralement téléchargé des packages eux-mêmes et des assemblages référencés sur le chemin du package manuellement. Un plus petit ensemble de programmeurs F # a utilisé le Paket Gestionnaire de packages et généré un “Charger le script” ? Une fonctionnalité de Paket qui génère un fichier de script F # avec des références à tous les assemblages dans les packages que vous souhaitez référencer ? et charge ce script dans leurs scripts F # fonctionnels. Cependant, parce que Paket est une alternative à Nuget au lieu d’un outil par défaut, la plupart des programmeurs F # ne l’utilisent pas.
Maintenant, avec F # 5, vous pouvez simplement référencer n’importe quel package NuGet dans un script F #. FSI restaure ce package avec Nuget et fait automatiquement référence à tous les assemblages du package. Voici un exemple:
#R "Nuget: Newtonsoft.JSON "Open NewTonsoft.JSON LET O = <| X = 2; Y = "Hello" |>printfn "% s" (jsonconvert.SerializeObject o) Lorsque vous exécutez le code dans cet extrait, vous verrez la sortie suivante:
Val O: <| X: int; Y: string |>= < X = 2 Y = "Hello" >Val it: unité = () La fonction de gestion des packages peut gérer à peu près tout ce que vous souhaitez y jeter. Il prend en charge les packages avec des dépendances natives comme ML.Net ou flips. Il prend également en charge des packages comme FPARSEC, qui exigeait auparavant que chaque assemblage du package soit référencé dans un ordre spécifique dans FSI.
Présentation de DotNet FSI
La deuxième frustration majeure pour les programmeurs F # utilisant FSI est qu’il manquait .Net Core pendant longtemps. Microsoft a publié une version initiale de FSI pour .Noyau net avec .Net Core 3.0, mais il n’a été utile que pour les scripts F # qui n’incorporent aucune dépendance. Maintenant, en conjonction avec la gestion des packages, vous pouvez utiliser FSI pour toutes les mêmes tâches sur macOS ou Linux comme vous le feriez sur Windows (sauf pour le lancement de WinForms et des applications WPF, pour des raisons évidentes). Cela se fait avec une seule commande: dotnet fsi .
Présentation du support F # dans Jupyter Notebooks
Il ne fait aucun doute que la gestion des packages et la mise à disposition de FSI partout rendent F # meilleur pour la programmation interactive. Mais Microsoft a estimé que nous pouvions faire plus que ça. La programmation interactive a explosé ces dernières années dans la communauté Python, grâce en grande partie aux cahiers Jupyter. La communauté F # avait construit un soutien initial pour F # dans Jupyter il y a de nombreuses années, nous avons donc travaillé avec son mainteneur actuel pour savoir ce qu’une bonne expérience pour Jupyter a signifié et construit.
Maintenant, avec F # 5, vous pouvez tirer des packages, inspecter les données et tracer les résultats de votre expérimentation dans un cahier partageable et multiplateforme que tout le monde peut lire et ajuster, comme indiqué dans Figure 2.
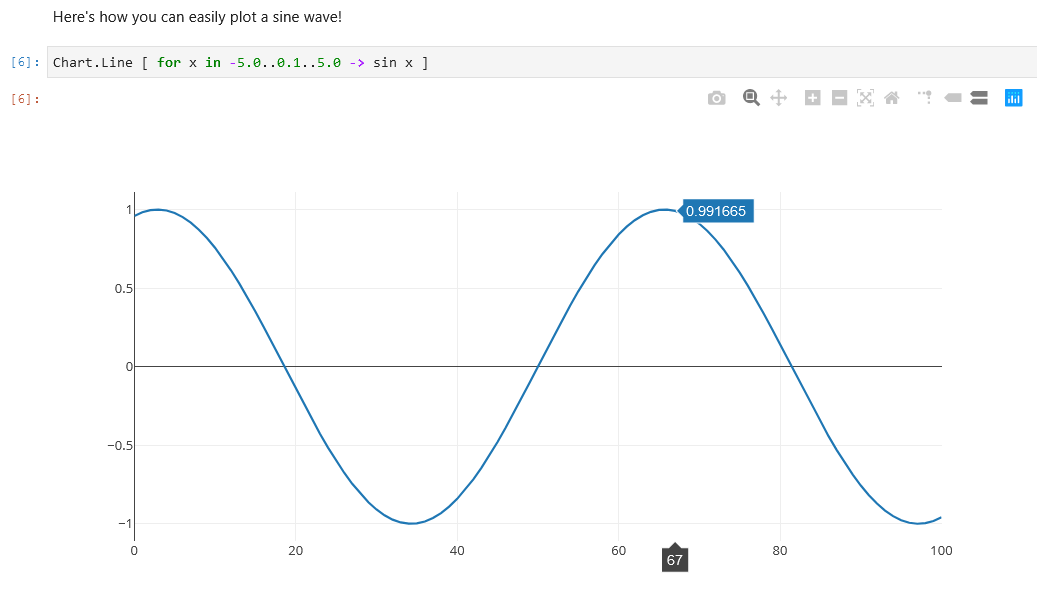
Une autre raison pour laquelle nous sommes très enthousiasmés par le support F # dans Jupyter Notebooks est que les cahiers sont faciles à partager avec d’autres personnes. Les cahiers Juputer rendent les documents de démarque dans GitHub et d’autres environnements. Non seulement ils sont un outil de programmation, mais ils produisent un document qui peut être utilisé pour instruire les autres comment effectuer des tâches, partager des résultats, apprendre une bibliothèque ou même apprendre F # lui-même!
Présentation de la prise en charge F # dans Visual Studio Code Notebooks
F # Le support dans Jupyter Notebooks apporte l’interactivité à un tout nouveau niveau. Mais Jupyter n’est pas le seul moyen de programmer pour un cahier. Visual Studio Code apporte également une programmation de carnet dans le pli, avec toute la puissance d’un service linguistique que vous vous attendez à trouver lors de la modification du code dans un fichier normal. Avec F # Prise en charge des cahiers de code Visual Studio, vous pouvez profiter de l’intégration du service linguistique lors de la création d’un ordinateur portable, comme indiqué dans figure 3.
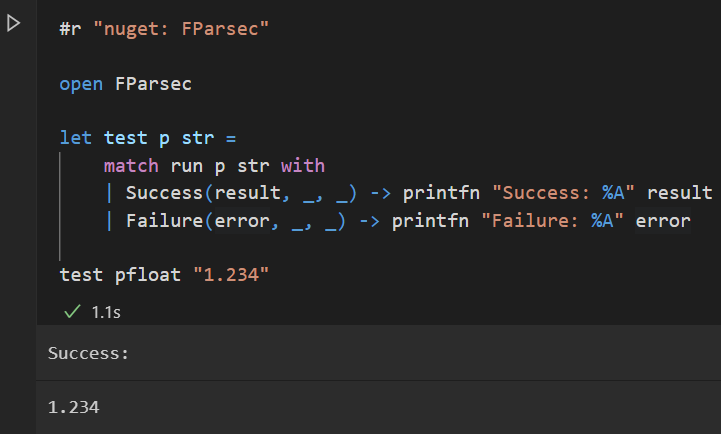
Un autre avantage des cahiers de code Visual Studio est son format de fichier, qui est conçu pour être lisible par l’homme et facile à diffuser dans le contrôle de la source. Il prend en charge l’importation de cahiers de jupyter et l’exportation de cahiers de code Visual Studio en tant que cahiers Jupyter, comme vous pouvez le voir dans Figure 4.
Vous pouvez faire beaucoup de choses avec F # dans Visual Studio Code et Jupyter Notebooks, et nous cherchons à étendre les capacités au-delà de ce qui a été décrit jusqu’à présent. Notre feuille de route comprend l’intégration avec divers autres outils, une visualisation plus cohésive des données et les données interopsonnent avec Python.
F # 5 pose plus de fondations pour la programmation analytique
Un paradigme d’importance croissante à l’ère de l’apprentissage automatique et de la science des données est ce que j’aime appeler “programmation analytique.” Ce paradigme n’est pas exactement nouveau, bien qu’il existe de nouvelles techniques, bibliothèques et cadres qui sortent chaque jour pour faire avancer l’espace. La programmation analytique consiste à analyser et à manipuler des données, en appliquant généralement des techniques numériques pour fournir des informations. Cela va de l’importation d’un CSV et de l’informatique une régression linéaire sur les données aux réseaux de neurones les plus avancés et les plus à forte intensité.
F # 5 représente le début de notre incursion dans cet espace. L’équipe de Microsoft pense que F # est déjà idéal pour manipuler les données, comme d’innombrables utilisateurs F # l’ont démontré en utilisant F # à cet effet exactement. F # a également un excellent support pour la programmation numérique avec certains types et fonctions intégrés et une syntaxe accessible et succincte. Nous avons donc gardé cela à l’esprit et identifié d’autres domaines pour améliorer.
Comportement cohérent avec les tranches
Une opération très courante effectuée dans la programmation analytique prend une tranche d’une structure de données, en particulier les tableaux. F # tranches utilisées pour se comporter de manière incohérente, avec certains comportements hors limites, ce qui entraîne une exception d’exécution et d’autres entraînant une tranche vide. Nous avons changé toutes les tranches de types intrinsèques F # – tableaux, listes, chaînes, tableaux 3D et tableaux 4D – pour retourner une tranche vide pour toute tranche que vous pourriez spécifier qui ne pourrait pas exister:
Soit l = [1..10] Soit a = [| 1..10 |] Soit S = "Bonjour!"// Avant: Liste vide // F # 5: Même LET EDADLIST = L.[-2..(-1)] // Avant: Je mettrait l'exception // f # 5: le tableau vide Laisse videArray = A.[-2..(-1)] // Avant: Je mettrait l'exception // f # 5: String vide LET VIDESTRING = S.[-2..(-1)] Le raisonnement en est en grande partie parce que dans F #, les tranches vides se composent avec des tranches non vides. Une chaîne vide peut être ajoutée à une chaîne non vide, les tableaux vides peuvent être ajoutés à des tableaux non vides, etc. Ce changement n’est pas révolutionnaire et permet une prévisibilité dans le comportement.
Découpe d’index fixe pour les tableaux 3D et 4D
F # a une prise en charge intégrée pour les tableaux 3D et 4D. Ces types de tableaux ont toujours pris en charge le tranchage et l’indexation, mais ne découpant jamais sur une index fixe. Avec F # 5, cela est maintenant possible:
// Tout d'abord, créez un tableau 3D avec des valeurs de 0 à 7 let dim = 2 let m = array3d.zérocereate dim dim sait mutable cnt = 0 pour z dans 0..dim-1 faire pour y en 0..dim-1 do pour x dans 0..dim-1 do m.[x, y, z] Cela aide à compléter l'image pour trancher les scénarios avec des tableaux 3D et 4D.
Aperçu: index inversés
Microsoft introduit également la possibilité d'utiliser des index inversés, qui peuvent être utilisés avec des tranches, comme aperçu dans F # 5. Pour l'utiliser, placez simplement
Soit xs = [1..10] // Obtenez l'élément 1 de la fin: xs.[^ 1] // Old Way d'obtenir les deux derniers éléments que LastTwooldStyle = XS.[(XS.Longueur-2)..] // Nouvelle façon d'obtenir les deux derniers éléments Let LastTwoneWstyle = XS.[^ 1..] LastTwooldStyle = LastTwoneWstyle // Vrai Vous pouvez également définir vos propres membres via une extension de type F # pour augmenter ces types pour prendre en charge les index de tranchage F #. L'exemple suivant le fait avec le type de portée:
Ouvrez System Type Span avec membre SP.GetSlice (stardidx, endIDX) = Soit S = defaultarg stardidx 0 Soit E = defaultarg EndIDX SP.Longueur sp.Slice (S, E - S) membre SP.GetReverseIndex (_, offset: int) = sp.Longueur - Offset LET SP = [| 1; 2; 3; 4; 5 |].Asspan () sp.[..^ 2] // [| 1; 2; 3 |] F # Les types intrinsèques ont des index inversés intégrés. Dans une future version de F #, nous prendrons également en charge l'interopération complète avec le système.Index et système.Gamme, à quel moment, la fonctionnalité ne sera plus en avant-première.
Citations de code améliorées
Les citations de code F # sont une fonction de métaprogrammation qui vous permet de manipuler la structure du code F # et de l'évaluer dans un environnement de votre choix. Cette capacité est essentielle pour utiliser F # comme langage de construction de modèle pour les tâches d'apprentissage automatique, où le modèle d'IA peut fonctionner sur différents matériels, comme un GPU. Une pièce critique manquante dans ce puzzle a été la capacité de représenter fidèlement les informations de contrainte de type F #, telles que celles utilisées dans l'arithmétique générique, dans la citation F # afin qu'un évaluateur puisse savoir pour appliquer ces contraintes dans l'environnement dans lequel il évalue dans.
En commençant par F # 5, les contraintes sont désormais conservées dans les citations de code, déverrouillant la capacité de certaines bibliothèques telles que DiffSharp pour utiliser cette partie du système de type F # à son avantage. Un moyen simple de démontrer ce code suivant:
fsharp ouvert.Linq.RunTimeHelpers Let Eval Q = LeafexpressionConverter .Évaluerquotation q Let inline nier x = -x // crucialement, 'négate' a // la signature suivante: // // val inline ne regate: // x: ^ a -> ^ a // lorsque ^ a: // (membre statique (~ -): ^ a -> ^ a) // // cette contrainte est essentielle à la sécurité du type f # // et est maintenant conservé dans des citations . |> eval L'utilisation d'un opérateur arithmétique implique une contrainte de type telle que tous les types passés pour annuler doivent supporter le ? opérateur. Ce code échoue lors de l'exécution car le devis du code ne conserve pas ces informations de contrainte, donc l'évaluer lance une exception.
Les citations de codes sont le fondement de certains travaux de R&D réalisés pour utiliser F # comme langage pour créer des modèles d'IA, et donc la capacité de conserver les informations de contrainte de type aide à faire de F # un langage convaincant pour les programmeurs dans cet espace qui recherchent un peu plus de sécurité dans leur vie dans leur vie dans leur vie dans leur vie dans leur vie.
F # 5 a de grands principes fondamentaux
F # 5 peut être mieux consacré à l'interactivité et à la programmation analytique, mais à la base, F # 5 consiste toujours à faire du codage quotidien dans F # une joie. F # 5 comprend plusieurs nouvelles fonctionnalités que les développeurs d'applications et les auteurs de bibliothèques peuvent profiter.
Prise en charge du nom de
Le premier est une fonctionnalité que les développeurs C # ont appris à aimer: Nomof . Le nom de l'opérateur prend un symbole F # en entrée et produit une chaîne au moment de la compilation qui représente ce symbole. Il prend en charge à peu près toutes les constructions F #. Le nom de l'opérateur est souvent utilisé pour la journalisation des diagnostics dans une application en cours d'exécution.
#R "Nuget: fsharp.SystemTextjson "Système ouvert.Texte.Système ouvert JSON.Texte.Json.Système ouvert de sérialisation.Durée.Module de service de compilor.f 12) printfn "% s" (nom de m) printfn "% s" (nom de m.f) /// Version simplifiée du type API de EventStore RecredeDevent = < EventType: string Data: byte[] >/// mon type de béton: Type MyEvent = | Adata d'int | Bdata de String // Utilisez 'Nameof' au lieu du littéral de la chaîne dans l'expression de correspondance, laissez désérialiser (e: enregistredEvent): myEvent = correspond à E.EventType avec | Nomof Adata -> JSONSerializer.Désérialiser e.Données |> Adata | Nomof Bdata -> JSONSerializer.Désérialiser e.Données |> BDATA | t -> failwithf "invalid EventType:% s" t Chaînes interpolées
Vient ensuite une fonctionnalité vue dans des langues telles que C # et JavaScript: chaînes interpolées. Les chaînes interpolées vous permettent de créer des interpolations ou des trous dans une chaîne que vous pouvez remplir avec toute expression F #. F # chaînes interpolées prennent en charge les interpolations typées synonymes avec le même format Spécifie dans les formats Sprintf et Printf Strings. F # Les chaînes interpolées prennent également en charge les cordes à triple triple. Tout comme en C #, tous les symboles d'une interpolation F # sont navigables, capables d'être renommés, et ainsi de suite.
// chaîne interpolée de base let name = "phillip" let âge = 29 let messuaire = $ "name:, Âge:" // interpolation typée // '% s' exige que l'interpolation soit une chaîne // '% d' nécessite que l'interpolation soit un int let message2 = $ "name:% s, Âge:% d" // verbatimated Strings interpolé "" "Nom": "", "Age": "" " De plus, vous pouvez écrire plusieurs expressions à l'intérieur des chaînes interpolées, produisant une valeur différente pour l'expression interpolée basée sur une entrée de la fonction. Il s'agit d'une utilisation plus de créneau de la fonctionnalité, mais comme toute interpolation peut être une expression F # valide, elle permet une grande flexibilité.
Déclarations de type ouverte
F # vous a toujours permis d'ouvrir un espace de noms ou un module pour exposer ses constructions publiques. Maintenant, avec F # 5, vous pouvez ouvrir n'importe quel type pour exposer des constructions statiques comme des méthodes statiques, des champs statiques, des propriétés statiques, etc. F # L'union et les enregistrements peuvent également être ouverts. Vous pouvez également ouvrir un type générique à une instanciation de type spécifique.
Système de type ouvert.Math Soit x = min (1.0, 2.0) Module m = type du = a | B | C Laissez une autre fonctionnalité x = x + 1 // Ouvrez uniquement le type à l'intérieur du module Open Type M.Du printfn "% a" a Expressions de calcul améliorées
Les expressions de calcul sont un ensemble bien-aimé de fonctionnalités qui permettent aux auteurs de la bibliothèque d'écrire du code expressif. Pour ceux qui sont versés dans la théorie des catégories, ils sont également la façon formelle d'écrire des calculs monadiques et monoïdaux. F # 5 étend les expressions de calcul avec deux nouvelles fonctionnalités:
- Formulaires applicatifs pour les expressions de calcul via LET. et! mots clés
- Support approprié pour la surcharge des opérations personnalisées
“Formulaires applicatifs pour les expressions de calcul” est un peu une bouchée. J'éviterai de plonger dans la théorie des catégories et de travailler à la place un exemple:
// Tout d'abord, définissez un résultat du module de fonction «zip» = Soit zip x1 x2 = correspondant x1, x2 avec | OK X1RES, OK X2RES -> OK (X1RES, X2RES) | Erreur E, _ -> Erreur E | _, Erreur e -> erreur e // suivant, définissez un constructeur avec `` Mergesources '' et «bindReturn» type resultBuilder () = membre _.Mergesources (T1: Résultat, T2: Résultat) = Résultat.membre zip t1 t2 _.BindReturn (x: résultat, f) = résultat.map f x let résultat = resultBuilder () LET Run r1 r2 r3 = // et voici notre applicatif! Soit Res1: résultat = résultat < let! a = r1 and! b = r2 and! c = r3 return a + b - c >Match Res1 avec | Ok x -> printfn "% s est:% d" (nameof res1) x | Erreur e -> printfn "% s est:% s" (nom de res1) e Avant F # 5, chacun d'eux et! Les mots clés auraient été laissés! mots clés. Le et! Le mot-clé diffère en ce que l'expression qui suit doit être 100% indépendante. Il ne peut pas dépendre du résultat d'un LET précédent! -valeur liée. Cela signifie que le code comme le suivant ne compile pas:
Soit Res1: résultat = résultat < let! a = r1 and! b = r2 a // try to pass 'a' and! c = r3 b // try to pass 'b' return a + b - c >Alors, pourquoi ferions-nous ce que le code ne compile pas? Quelques raisons. Tout d'abord, il applique l'indépendance informatique à la compilation du temps. Deuxièmement, il achète un peu de performances lors de l'exécution car il permet au compilateur de construire le graphique d'appel statiquement. Troisièmement, comme chaque calcul est indépendant, ils peuvent être exécutés en parallèle par n'importe quel environnement dans lequel ils exécutent. Enfin, si un calcul échoue, comme dans l'exemple précédent où l'on peut renvoyer une valeur d'erreur au lieu d'une valeur OK, le tout ne court pas sur cette panne. Formulaires applicatifs “rassembler” Toutes les valeurs résultantes et permettent à chaque calcul d'exécuter avant de terminer. Si vous deviez remplacer chacun et! avec un let! , Celui qui a renvoyé une erreur court-circuites hors de la fonction. Ce comportement différent permet aux auteurs de la bibliothèque et aux utilisateurs de choisir le bon comportement en fonction de leur scénario.
Si cela ressemble à un peu de concept, c'est bien! Les calculs applicatifs sont un peu un concept avancé du point de vue d'un auteur de bibliothèque, mais ils sont un outil puissant pour l'abstraction. En tant qu'utilisateur d'entre eux, vous n'avez pas besoin de connaître tous les tenants et aboutissants de leur fonctionnement; Vous pouvez simplement savoir que chaque calcul dans une expression de calcul est garanti d'être exécuté indépendamment des autres.
Une autre amélioration des expressions de calcul est la possibilité de prendre en charge correctement la surcharge pour les opérations personnalisées avec le même nom de mot-clé, la prise en charge des arguments facultatifs et la prise en charge du système.Arguments Paramarray. Une opération personnalisée est un moyen pour un auteur de bibliothèque de spécifier un mot-clé spécial qui représente son propre type d'opération qui peut se produire dans une expression de calcul. Cette fonctionnalité est beaucoup utilisée dans des cadres comme Saturne pour définir un DSL expressif pour créer des applications Web. En commençant par F # 5, les auteurs de composants comme Saturn peuvent surcharger leurs opérations personnalisées sans aucune mise en garde, comme indiqué dans Listing 1.
Listing 1: les expressions de calcul peuvent surcharger des opérations personnalisées
Type InputKind = | Texte de placement: option de chaîne | Mot de passe d'espace: Type d'option String Type InputOptions = < Label: string option Kind: InputKind Validators: (string ->bool) Array> Type inputBuilder () = membre t.Rendement (_) = < Label = None Kind = Text None Validators = [||] >[] Membre ceci.Texte (IO,?place de l'espace) = < io with Kind = Text placeholder >[] Membre ceci.Mot de passe (IO,?place de l'espace) = < io with Kind = Password placeholder >[] Membre ceci.Étiquette (io, étiquette) = < io with Label = Some label >[] Membre ceci.Validateurs (io, [] validateurs) = < io with Validators = validators >LET INPUT = InputBuilder () Selt Name = Input < label "Name" text with_validators (String.IsNullOrWhiteSpace >> non)> Laissez Email = entrée < label "Email" text "Your email" with_validators (String.IsNullOrWhiteSpace >> pas) (Fun s -> s.Contient "@")> Let Password = Input < label "Password" password "Must contains at least 6 characters, one number and one uppercase" with_validators (String.exists Char.IsUpper) (String.exists Char.IsDigit) (fun s ->s.Longueur> = 6)> La prise en charge appropriée pour les surcharges dans les opérations personnalisées est entièrement développée par deux contributeurs open source F # Diego Esmerio et Ryan Riley.
Avec des formulaires applicatifs pour les expressions de calcul et la possibilité de surcharger des opérations personnalisées, nous sommes ravis de voir ce que F # Library auteurs peut faire ensuite.
Implémentations d'interface à différentes instanciations génériques
En commençant par F # 5, vous pouvez désormais implémenter la même interface à différentes instanciations génériques. Cette fonctionnalité a été développée en partenariat avec Lukas Rieger, un contributeur Open Source F #.
Type IA = membre abstrait Get: Unit -> ?T type myclass () = interface ia avec membre x.Get () = 1 interface ia avec le membre x.Get () = "bonjour" let mc = myclass () let asInt = mc:> ia let asstring = mc:> ia asint.Get () // 1 asstring.Get () // "bonjour" Plus .Améliorations nettes d'interopr
.Net est une plate-forme en évolution, avec de nouveaux concepts introduits chaque version et donc plus d'opportunités d'interopérer. Interfaces dans .Net peut désormais spécifier des implémentations par défaut pour les méthodes et les propriétés. F # 5 vous permet de consommer ces interfaces directement. Considérez le code C # suivant:
Utilisation du système; Espace de noms CSharplibrary < public interface MyDim < public int Z =>0; >> Cette interface peut être consommée directement dans F #:
Ouvrir cSharp // Créer une expression d'objet pour implémenter l'interface Sous MD = < new MyDim >printfn $ "Dim from c #:" Un autre concept dans .Net qui attire plus d'attention est des types de valeur nullables (anciennement appelés types nullables). Initialement créés pour mieux représenter les types de données SQL, ils sont également fondamentaux pour les bibliothèques de manipulation de données de base comme l'abstraction du cadre de données dans Microsoft.Données.Analyse . Pour rendre un peu plus facile à intervenir avec ces bibliothèques, vous appliquez une nouvelle règle dirigée pour l'appel et l'attribution de valeurs aux propriétés qui sont un type de valeur nullable. Considérez l'échantillon suivant en utilisant ce package avec une directive de référence du package:
#R "Nuget: Microsoft.Données.Analyse "Open System Open Microsoft.Données.Analyse Let DateTimes = "DateTimes" |> PrimitedataframeColumn // Ce qui suit utilisé pour ne pas compiler let Date = DateTime.Parse ("2019/01/01") DateTimes.Ajouter (date) // Le précédent est désormais équivalent à: LET DATE = DateTime.Parse ("2019/01/01") LET DATA = Nullable (Date) DateTimes.Ajouter (données) Ces exemples utilisés pour exiger que vous construisez explicitement un type de valeur nullable avec le constructeur de type nullable comme le montre l'exemple.
Meilleure performance
L'équipe Microsoft a passé l'année dernière à améliorer les performances du compilateur F # à la fois en termes de débit et de performances d'outillage dans des ides comme Visual Studio. Ces améliorations des performances ont été déployées progressivement plutôt que dans le cadre d'une grande version. La somme de ce travail qui culmine dans F # 5 peut faire une différence pour la programmation F # quotidienne. Par exemple, j'ai compilé la même base de code ? Le projet de base de Fsharplus, un projet qui souligne notoirement le compilateur F # ? trois fois. Une fois pour F # 5, une fois pour le dernier F # 4.7 avec .Net Core, et une fois pour le dernier F # 4.5 dans .Noyau net, comme indiqué dans Tableau 1.
Les résultats dans Tableau 1 Viennent de l'exécution de Dotnet Build / CLP: PerformancesNary de la ligne de commande et en regardant le temps total passé dans la tâche FSC, qui est le compilateur F #. Les résultats peuvent varier sur votre ordinateur en fonction des choses comme la priorité du processus ou le travail de fond, mais vous devriez voir à peu près les mêmes diminutions des temps de compilation.
Les performances IDE sont généralement influencées par l'utilisation de la mémoire car les ides, comme Visual Studio, hébergent un compilateur au sein d'un service de langue en tant que processus à longue durée de vie. Comme pour les autres processus de serveur, moins vous utilisez de mémoire, moins le temps GC est consacré à nettoyer la vieille mémoire et plus le temps peut être consacré au traitement des informations utiles. Nous nous sommes concentrés sur deux domaines principaux:
- Utilisation de fichiers mappés de mémoire pour soutenir les métadonnées à lire dans le compilateur
- Les opérations réarchitectives qui trouvent des symboles à travers une solution, comme trouver toutes les références et renommer
Le résultat est nettement moins d'utilisation de la mémoire pour des solutions plus grandes lors de l'utilisation des fonctionnalités IDE. Figure 5 montre un exemple d'utilisation de la mémoire lors de l'exécution de trouver des références sur le type de chaîne en faux, une très grande base de code open source, avant les modifications que nous avons apportées.

Cette opération prend également une minute et 11 secondes à terminer lors de l'exécution pour la première fois.
Avec F # 5 et les outils F # mis à jour pour Visual Studio, la même opération prend 43 secondes pour terminer et utilise plus de 500 Mo de mémoire en moins, comme indiqué dans Figure 6.

L'exemple avec les résultats montrés dans Figure 5 et Figure 6 est extrême, car la plupart des développeurs ne recherchent pas les usages d'un type de base comme une chaîne dans une très grande base de code, mais cela montre à quel point les performances sont meilleures lorsque vous utilisez F # 5 et le dernier outillage pour F # par rapport à il y a seulement un an.
La performance est quelque chose qui est constamment travaillé et les améliorations proviennent souvent de nos contributeurs open source. Certains d'entre eux incluent Steffen Forkmann, Eugene Auduchinok, Chet Hust, Saul Rennison, Abel Braaksma, Isaac Abraham et plus. Chaque version propose un travail incroyable par des contributeurs open source; Nous sommes éternellement reconnaissants pour leur travail.
Le voyage F # continu et comment s'impliquer
L'équipe Microsoft F # est très ravie de sortir F # 5 cette année et nous espérons que vous l'aimerez autant que nous. F # 5 représente le début d'un nouveau voyage pour nous. Dans l'attente, nous allons continuellement améliorer les expériences interactives pour faire de F # le meilleur choix pour les cahiers et autres outils interactifs. Nous allons aller plus profondément dans la conception des langues et continuer à soutenir les bibliothèques comme Diffsharp pour faire de F # un choix convaincant pour l'apprentissage automatique. Et comme toujours, nous allons améliorer les fondamentaux du compilateur F # et de l'outillage et intégrer les fonctionnalités linguistiques que tout le monde peut apprécier.
Nous serions ravis de vous voir venir pour la balade aussi. F # est entièrement open source, avec des suggestions de langage, une conception du langage et un développement de base qui se déroule sur github. Il y a d'excellents contributeurs aujourd'hui et nous recherchons plus de contributeurs qui veulent avoir une participation dans la façon dont le langage F # et les outils évoluent à l'avenir.
Pour vous impliquer au niveau technique, consultez les liens suivants:
- F # Suggestions de langage: https: // github.com / fsharp / fslang-sugressions
- F # conception de la langue: https: // github.com / fsharp / fslang-conception
- F # Développement: https: // github.com / dotnet / fsharp
- F # Exécution sur javascript: https: // fable.io /
- F # Outillage pour Visual Studio Code: http: // ionide.io /
- F # Exécution sur l'assemblage Web: https: // fsbolero.io /
Le F # Software Foundation héberge également une grande communauté Slack, en plus d'être un point central pour diverses sous-communautés pour partager les informations les unes avec les autres. Il est gratuit de rejoindre, alors rendez-vous sur le site Web ici pour en savoir plus: http: // fondation.fsharp.org / join
Veux avoir un mot à dire sur où F # va ensuite et comment il fait? Venez nous rejoindre. Nous serions ravis de travailler ensemble.
Cahiers de jupyter
Les cahiers Jupyter sont un outil de programmation interactif qui vous permet de mélanger la marque et le code dans un document. Le code peut être exécuté dans le cahier, souvent pour produire des données ou des graphiques structurés qui vont de pair avec une explication.
Les cahiers Jupyter ont commencé comme Ipython, un outil de programmation interactif pour les programmes Python. Il a grandi pour soutenir de nombreuses langues différentes et est maintenant l'un des principaux outils utilisés par les scientifiques des données dans leur travail. Il est également utilisé comme un outil éducatif.
Tableau 1: Compiler les temps pour fsharpplus.DLL à travers les versions F # récentes
| F # et .Version SDK NET | Temps pour compiler (en quelques secondes) |
| F # 5 et .SDK net 5 | 49.23 secondes |
| F # 4.7 et .Net Core 3.1 SDK | 68.2 secondes |
| F # 4.5 et .Net Core 2.1 SDK | 100.7 secondes |
F # Langage de programmation: histoire, avantages et possibilités futures

Les développeurs Nescients pourraient faire l'erreur de prononcer le nom comme f ‘Hacher’ Mais cela gagnera quelques yeux méprisants des adeptes du développeur’communauté. F Sharp (parce que le # est prononcé comme Sharp) est un langage de programmation à plusieurs paradigmes, fortement dactylographiée,. Le langage de programmation multi-paradigme inclut la programmation fonctionnelle, impérative et orientée objet
Chaque langage de programmation peut tomber dans l'une des deux catégories; fortement dactylographié et faiblement dactylographié.
Les langues fortement dactylographiées ont des réglementations hautement obstinées au moment de la compilation, ce qui implique que les erreurs et les exceptions sont plus susceptibles de se produire. La majorité de ces réglementations affectent les valeurs de retour, les affectations variables et les appels de fonction.
Alors que le langage faiblement dactylographié est le contraire et a des règles de frappe lâche qui peuvent grêler les résultats imprévisibles ou peuvent provoquer une conversion de type implicite lors de l'exécution.
Le multi-paradigme fait référence au support de plus d'un paradigme de programmation pour permettre aux programmeurs de sélectionner le style de programmation le plus approprié et les constructions de langage associées pour un projet donné.
Il est souvent utilisé comme CLI multiplateforme (infrastructure linguistique commune) et peut également générer du code JavaScript et GPU (Graphics Processing Unit).
Il est développé par F # Software Foundation et Microsoft ainsi que d'autres contributeurs ouverts.
Bref historique

F # a vu le jour en 2005 lorsqu'il a été développé par Microsoft Research. Au départ, c'était un .Implémentation net (prononcée sous forme de net) de l'OCAML car elle a combiné la puissance et la syntaxe du langage fonctionnel avec des milliers de fonctions de bibliothèque disponibles avec .Langues nettes.
Depuis 2005, F # a subi de nombreux changements nécessaires et les développeurs ont fait diverses versions qui l'ont rendu meilleur que le premier. Lancement sous la licence Apache, a fait de la langue de programmation un ouverture d'origine, ce qui signifiait qu'il peut être modifié, distribué et utilisé sans payer aux développeurs d'origine.
La première version lancée en 2005 n'était compatible qu'avec Windows et déployé un .Net 1.0 à 3.5 Runnitime. La base de plate-forme étroite était la plus grande faiblesse de cette version. Le problème a été résolu dans la version suivante qui a été développée avec l'ajout de OS X et Linux aux plates-formes prises en charge de la version 2.0 qui a été lancé en 2010.
En 2012, F # a vu l'ajout de JavaScript et GPU dans les plateformes prises en charge. La dernière version a été lancée en 2015 qui était de 4.0.
Avenir de f #

Beaucoup de gens affirment que F # est l'un des langages de programmation les plus impopulaires, sous-estimés et sous-représentés. Mais il y a un autre côté à l'histoire. Selon Stackoverflow. F # a été élu la langue associée au salaire le plus rémunéré dans le monde entier.
La même enquête montre que F # ne fait pas’t apparaissent dans les 25 meilleurs langages de programmation utilisés à travers le monde. La langue reste en marge malgré une communauté vraiment active.
Mais pourquoi les développeurs aiment-ils travailler avec f # si ça’est tellement impopulaire? Créée et maintenue par Don Syme, F # a été relativement résilient à certaines des complications excessives supposées que des langues FP similaires ont adoptée comme Scala. Cette résistance maintient l'accessibilité pour les développeurs du monde extérieur qui pourraient être intéressés à se taire dans la programmation fonctionnelle.
F # a été d'une excellente utilité en ce qui concerne le développement basé sur les données et le domaine. Maintenant, il peut également être compilé en javascript qui est le monde’s langues les plus populaires. Avec ce lien sécurisé, il a également accès à JavaScript’s bibliothèques et base d'appareils.
F # a fait sa marque en ce qui concerne l'intelligence artificielle, l'apprentissage automatique et l'analyse des données associées. C'était le but même de la création de F #. En raison de l'immense échelle et de l'influence attendue, l'intelligence artificielle aura sur les écosystèmes de langue et la technologie en général, ayant une langue si bien adaptée aux lieux de développement d'une position forte pour croître rapidement et même défier les langues populaires comme JavaScript et Python à l'avenir.
Qu'est-ce qui arrête F #’Sprocession?

Bien que cela semble être un fait dur à digérer, le blâme pour cela est principalement attribué à ses créateurs, qui est Microsoft. Ils ont limité la popularité de F # Laissant C # Florish là-bas. Microsoft a rendu F # inférieur à C #.
Il y a un mouvement cyclique. Peu d'emplois existent pour F # car il y a peu de développeurs F # et il y a moins de développeurs F # parce qu'il y a moins d'emplois F # existent là-bas. Mais lentement mais sûrement, cette tendance change.
Jet.com a été la première grande entreprise à adopter l'utilisation de F #. Plus tard, Kaggle et de nombreuses compagnies financières et d'assurance ont également suivi.
Les développeurs de F # manquent de le rendre plus populaire et avec des fonctionnalités en tant que langue multi-paradigme qui est grandement utilisée dans l'IA, la meilleure chose à faire est de se concentrer sur les avantages principaux de F # qui sont des temps d'exécution plus courts, moins de bugs et de productivité plus élevée. S'il est promu en mettant en évidence ces fonctionnalités, cela pourrait aider F # gravir l'échelle de la popularité plus rapidement qu'avant.
F # détient-il vraiment tout avantage sur C #?

Déjà familier avec C #? Puis apprenez à programmer votre propre jeu d'évasion en utilisant C #.
- F # rend de nombreuses tâches de programmation courantes plus simples. Cela implique des choses comme la création et l'utilisation de définitions de types complexes, le traitement de la liste, les machines d'État, l'égalité et la comparaison, et bien plus encore.
- Dépourvu de demi-colons, de supports bouclés et autres, dans F #, vous n'avez presque jamais à spécifier le type d'un objet en raison de la présence d'un système d'inférence de type puissant. Il faut également moins de lignes de codes pour résoudre ce problème également
- F # est un langage fonctionnel, mais il prend en charge d'autres styles qui’t complètement pur, ce qui rend beaucoup plus facile d'interagir avec le domaine non pure des bases de données, des sites Web, etc. En particulier, F # est conçu comme un langage hybride / OO fonctionnel, il est donc capable de tout faire comme C #. Même si F # s'intègre parfaitement à .Écosystème net qui vous permet d'accéder à toutes les tiers .Outils et bibliothèques nettes.
- F # fait partie de Visual Studio qui vous permet d'obtenir un bon éditeur avec un support Intellisense, un débogueur et de nombreux plugins pour les tests unitaires, le contrôle des sources et d'autres tâches de développement.
F # futur
Semblable à un async < >bloquer mais capture le résultat pour une consommation future. Cette structure peut être très utile pour effectuer plusieurs opérations de rendement des résultats en parallèle lorsque les résultats ne sont pas nécessaires immédiatement. Par exemple, effectuer plusieurs opérations de lecture / transformation ou pré-populant un cache avec des valeurs calculées encore à être. Bibliothèque parallèle de la tâche de Microsoft en .Net 4.0 comprend une future implémentation, cette version est donc nécessaire que sur précédemment .Versions nettes. Les commentaires, les suggestions et les améliorations sont toujours les bienvenus.
1: 2: 3: 4: 5: 6: 7: 8: 9: dix: 11: 12: 13: 14: 15: 16: 17: 18: 19: 20: 21: 22: 23: 24: 25: 26: 27: 28: 29: 30: 31: 32: 33: 34: 35: 36: 37: 38: 39: 40: 41: 42: 43: 44: 45: 46: 47: 48: 49: 50: 51: 52: 53: 54: 55: 56: 57: 58: 59: 60: 61: 62: 63: 64: 65: 66: 67: 68: 69: 70: 71: 72: 73: 74:
ouvrir Système ouvrir Système.Modèle de composant ouvrir Système.Filetage /// Exécute un calcul dans un travailleur en arrière-plan et se synchronise sur le rendement du résultat. Le /// Le calcul est démarré immédiatement et appeler les blocs de «valeur» jusqu'à ce que le résultat soit prêt. taper Avenir't>(F : unité -> 't) = /// Résultat du calcul à la sortie normale. laisser mutable résultat :'t option = Aucun /// Résultat si une exception a été lancée. laisser mutable ext : Exception option = Aucun laisser se synchroniser = nouveau Objet() /// objet d'impulsion utilisé pour attendre jusqu'à ce qu'un résultat soit prêt. AssurePulse () est utilisé pour que nous /// Je n'ai pas à créer l'objet si le résultat est fait avant qu'il soit nécessaire. laisser mutable impulsion : Manualresevent = nul laisser assurer() = serrure se synchroniser (amusant () -> correspondre impulsion avec | nul -> impulsion nouveau Manualresevent(FAUX)); | _ -> () impulsion) /// AVERTISSEMENT: Appelez une fois qu'un verrouillage sur le syncroot est déjà détenu. Pulses le notif d'attente. Sûr si /// appelé après la création de 'Pulse' mais avant que Waitone ne soit appelé. laisser notifywaiters() = si impulsion <> nul alors impulsion.Ensemble() |> ignorer laisser travail = nouveau Fondateur de fond() /// sur RunworkerAsync (), exécutez la fonction spécifiée et le résultat du stockage. Toutes les exceptions doivent être /// piégé. faire travail.Faire du travail.Ajouter( amusant args -> essayer résultat Quelques( F()) avec e -> ext Quelques e serrure se synchroniser ( amusant () -> notifywaiters())) /// démarrer immédiatement / automatiquement. faire travail.Runworkerasync() /// renvoie la valeur du calcul, bloquant si le résultat n'est pas encore prêt. membre t.Valeur = // Si disponible, nous pouvons le retourner tout de suite. correspondre résultat avec | Quelques X -> X | Aucun quand ext.Ciseler -> augmenter (Option.obtenir ext) | Aucun -> laisser p = assurer() // Vérifiez à nouveau au cas où il a changé pendant que nous obtenions l'objet d'attente. correspondre résultat avec | Quelques X -> X | Aucun -> // sans verrouillage est ok car si le pouls.La méthode set () est appelée entre quand nous // Vérification du «résultat» et appelez Waitone ici, Waitone reviendra immédiatement. p.Sizon d'attente(1000000000) |> ignorer correspondre résultat avec | Quelques X -> X | Aucun -> si ext.Ciseler alors augmenter (Option.obtenir ext) autre échoue "Le calcul futur a échoué." /// renvoie vrai si le calcul est terminé, faux sinon. membre t.Est complet = correspondre résultat avec | Quelques X -> vrai | Aucun quand Option.ciseler ext -> vrai | Aucun -> FAUX système d'espace de noms
système d'espace de noms.Modèle de composant
système d'espace de noms.Filetage
Multiples
Tapez futur =
Nouveau: f: (unité -> 't) -> futur
Membre ISCOMPLETE: BOOL
Valeur du membre: 'T
Nom complet: script.Avenir
Exécute un calcul dans un travailleur en arrière-plan et se synchronise sur le rendement du résultat. Le
Le calcul est démarré immédiatement et appelle les blocs de «valeur» jusqu'à ce que le résultat soit prêt.
Val F: (unité -> 't)
Type Unité = unité
Nom complet: Microsoft.Fsharp.Cœur.unité
Val Mutable Résultat: `` T option
Résultat du calcul à la sortie normale.
Tapez 'T Option = Option
Nom complet: Microsoft.Fsharp.Cœur.option
Option de cas syndical.Aucun: option
Val Mutable ext: Option Exception
Résultat si une exception a été lancée.
Multiples
Type Exception =
Nouveau: unité -> Exception + 2 surcharges
Données des membres: idictionnaire
Membre GetBaseException: unité -> Exception
membre getObjectData: info: SerializationInfo * Contexte: StreamingContext -> Unité
Membre GetType: Unité -> Type
Membre HELLPLINK: String with Get, définissez
membre inserexception: exception
Message du membre: chaîne
Source du membre: chaîne avec get, définir
membre stackTrace: chaîne
.
Nom complet: système.Exception
--------------------
Exception (): unité
Exception (message: chaîne): unité
Exception (Message: chaîne, innerexception: exn): unité
Val Syncroot: objet
Multiples
type objet =
Nouveau: unité -> obj
Membre est égal à: OBJ: OBJ -> BOOL
Membre GethashCode: unité -> int
Membre GetType: Unité -> Type
Member Tostring: Unit -> String
membre statique est égal: obja: obj * objb: obj -> bool
Membres statiques Reference Equals: Obja: Obj * objb: obj -> bool
Nom complet: système.Objet
Val Mutable Pulse: manualresevent
Objet d'impulsion utilisé pour attendre jusqu'à ce qu'un résultat soit prêt. AssurePulse () est utilisé pour que nous
Je n'ai pas à créer l'objet si le résultat est fait avant qu'il soit nécessaire.
Multiples
type manualresevent =
hériter eventwaithandle
Nouveau: InitialState: bool -> manualresevent
Nom complet: système.Filetage.Manualresevent
--------------------
Manualresevent (Initialstate: bool): unité
VAL SURPULSE: (Unité -> ManualreSetEvent)
Val Lock: LockObject: 'Lock -> Action: (Unité ->' T) -> 'T (Type de référence requise)
Nom complet: Microsoft.Fsharp.Cœur.Les opérateurs.serrure
Val NotifyWaiters: (unité -> unité)
AVERTISSEMENT: Appelez une fois qu'un verrouillage sur le syncroot est déjà tenu. Pulses le notif d'attente. Sûr si
appelé après la création de «pouls» mais avant que Waitone ne soit appelé.
Eventwaithandle.Set (): bool
Val ignore: valeur: 't -> unité
Nom complet: Microsoft.Fsharp.Cœur.Les opérateurs.ignorer
Val Work: Backgroundworker
Multiples
type backgroundworker =
composant hérité
Nouveau: unité -> Backgroundworker
Membre AnnuleSync: Unité -> Unité
Annulation du membre PRENDRE: BOOL
Membre Isbusy: Bool
Rapport membre PROGRESS: PEPROGRESS: int -> unité + 1 surcharge
membre du membre Runworkerasync: unité -> unité + 1 surcharge
WorkerReportsProgress membre: bool avec get, set
Travailleurs membres SupportScellation: bool with get, set
Événement Dowork: DoworkeventHandler
Événement ProgressChanged: ProgressChangedEventHandler
.
Nom complet: système.Modèle de composant.Fondateur de fond
Event des antécédents.Dowork: Ievent
membre iOBServable.Ajouter: rappel 🙁 't -> unité) -> unité
Val Args: Doworkeventargs
Option de cas syndical.Certains: Valeur: 'T -> Option
Val E: Exn
Fondateur de fond.Runworkerasync (): unité
Fondateur de fond.Runworkerasync (argument: obj): unité
Val T: Future
futur membre.Valeur: 'T
Nom complet: script.Future`1.Valeur
Sur Runworkerasync (), exécutez la fonction spécifiée et le résultat du stockage. Toutes les exceptions doivent être
piégé.
Démarrer immédiatement / automatiquement.
Renvoie la valeur du calcul, bloquant si le résultat n'est pas encore prêt.
option de propriété.Issome: Bool
Val Raisie: Exn: Exception -> 'T
Nom complet: Microsoft.Fsharp.Cœur.Les opérateurs.augmenter
Val Get: Option: 't Option ->' t
Nom complet: Microsoft.Fsharp.Cœur.Option.obtenir
Val P: manualresevent
Gardien.Waitone (): bool
Gardien.Waitone (temps mort: timepan): bool
Gardien.Waitone (millisecondstimeout: int): bool
Gardien.Waitone (temps mort: timepan, exitContext: bool): bool
Gardien.Waitone (millisecondstimeout: int, exitContext: bool): bool
Val Failwith: message: chaîne -> 't
Nom complet: Microsoft.Fsharp.Cœur.Les opérateurs.échoue
futur membre.ISCOMPLETE: BOOL
Nom complet: script.Future`1.Est complet
Renvoie True si le calcul est terminé, faux sinon.
Val Issome: Option: 'T OPTION -> BOOL
Nom complet: Microsoft.Fsharp.Cœur.Option.ciseler
Copier le lien Copier Source Raw Afficher le code de test Nouvelle version
Plus d'information
| Lien: | http: // fssnip.net / 5T |
| Publié: | Il y a 11 ans |
| Auteur: | Jason McCampbell |
| Mots clés: | Async, parallèle, futur, thread |
Bâtiment fonctionnel .Applications nettes: un guide de choix entre F # vs C #
L'efficacité est tout dans le monde du développement des applications. Les développeurs et les organisations qui peuvent faire commercialiser les produits plus rapidement et fournir des rafraîchissements plus rapides auront toujours un avantage sur la concurrence.
Ainsi, tout le monde cherche toujours des moyens de réduire le temps de développement, le temps consacré au débogage et aux tests et au temps de pousser les versions terminées aux clients.
La programmation fonctionnelle était courante il y a des décennies, mais a perdu du terrain rapidement dans les langages de programmation orientés objet, qui est rapidement devenu la norme de facto.
Contenu parrainé connexe
Sponsor connexe
/filters:no_upscale()/sponsorship/topic/25afca57-6bcb-4c42-9a70-fbea10ce4fc7/MicrosoftLogoRSB-1678874949003.png)
Code, déploier et mettre à l'échelle Java à votre façon.
Microsoft Azure prend en charge votre charge de travail avec des choix abondants, que vous travailliez sur une application Java, un serveur d'applications ou un cadre. Apprendre encore plus.
Mais ces dernières années, il y a eu une résurgence d'intérêt pour la programmation fonctionnelle comme moyen d'améliorer l'efficacité du développement et de créer des applications plus stables et robustes.
C # et F # sont des langues avec des bases utilisateur en croissance qui abordent la programmation fonctionnelle de manière fondamentalement différente: C # en complément de son paradigme impératif inhérent et F # comme paradigme principal.
Cet article étudie laquelle de ces langues fait le meilleur travail pour les développeurs qui cherchent à mettre en place une programmation fonctionnelle pour leurs équipes et projets.
Le débat sur la programmation fonctionnelle vs orientée objet
Pour comprendre le débat, nous devons commencer à un niveau un peu supérieur avec la différence entre les paradigmes de programmation impérative et déclaratif.
- Programmation impérative: Une approche de programmation basée sur les processus, où les développeurs spécifient comment obtenir des résultats étape par étape. La programmation impérative se concentre sur les changements d'état du programme et d'État. Les langages de programmation orientés objet comme Java et C ++ suivent généralement le paradigme impératif.
- Programmation déclarative: Une approche de programmation axée sur les résultats, où les développeurs spécifient les types de résultats souhaités. La programmation déclarative est sans état et l'ordre d'exécution agnostique. Les langages de programmation fonctionnelle comme Lisp, Python, Haskell et F # suivent le paradigme de programmation déclarative.
Mais c'est une simplification excessive pour essayer de diviser soigneusement tous les langages de programmation existants dans ces catégories, car plusieurs langages offrent des aspects de chacun. Ce sont des langues hybrides ou multi-paradigmes.
Par exemple, même si Java et C ++ entrent traditionnellement dans la classification impérative, ils ont également des aspects fonctionnels. Il en va de même pour C #. De même, bien que F # soit considéré comme un langage fonctionnel, il a également des capacités impératives.
Regardez la liste des dix meilleures langues que les développeurs utilisent. Vous verrez qu'ils englobent principalement des langues hybrides, certains se concentrant sur l'impératif et d'autres plus importants.

JavaScript, qui occupe la première place de cette enquête pendant une décennie, est une langue multi-paradigme, offrant à la fois des fonctionnalités impératives et orientées objet et des fonctionnalités fonctionnelles.
Compte tenu de l'éventail d'adoption, il est utile de considérer les différents avantages que chaque paradigme présente et les différents cas d'utilisation où chacun excelle.
Programmation impérative: avantages et cas d'utilisation
Parmi les principaux avantages du paradigme impératif, c'est que le code écrit en utilisant est généralement facilement compris et peut être facile à lire. De plus, étant donné les descriptions méticuleuses du flux de travail que nécessite la programmation impérative, même les développeurs novices trouvent plus facile à suivre.
Mais le niveau de la programmation impérative des détails nécessite également des inconvénients. Par exemple, dans des applications plus complexes, le code peut rapidement devenir gonflé. À mesure que la taille du code augmente, la facilité de lecture et de compréhension tombe aussi rapidement.
De plus, à mesure que le code se développe, le potentiel de bogues et d'erreurs augmente. Ainsi, les développeurs travaillant avec des langues impératifs se retrouvent souvent à passer beaucoup de temps à déboguer et à tester, retardant les versions de produits.
Néanmoins, la programmation impérative reste incroyablement populaire et dispose d'un large éventail de cas d'utilisation. Les applications traditionnelles pour la programmation impérative comprennent:
- Hypertexte et hypermédia
- Systèmes de gestion de la base de données d'objets (ODBM)
- Systèmes client-serveur
- Systèmes en temps réel
- Intelligence artificielle, réseaux d'apprentissage automatique et neuronaux
- Automatisation
Programmation fonctionnelle: avantages et cas d'utilisation
Les avantages de la programmation fonctionnelle se terminent davantage sur le côté efficacité de l'équation. Le code fonctionnel, bien que moins facile à lire et à comprendre à première vue, a tendance à être plus proche de l'absence de bogue (i.e., Pas d'effets secondaires pour les changements d'état), réduisant le temps des développeurs consacrés à la débogage et aux tests.
Moins de bogues se prêtent également à des applications plus sécurisées, limitant la surface d'attaque pour les cybercriminels afin de réduire les chances d'attaques de ransomware, de logiciels malveillants ou d'injections SQL.
La programmation fonctionnelle est également meilleure dans le traitement parallèle et l'évaluation paresseuse. De plus, le code fonctionnel est plus modulaire et réutilisable, réduisant le besoin de code redondant. Le plus petit ensemble de codes est plus facile à maintenir et peut être plus performant. Cependant, le code fonctionnel peut être à forte intensité de mémoire, éliminant les avantages de la vitesse de la taille du code réduite et conduisant réellement à une diminution des performances globales.
La programmation fonctionnelle est particulièrement populaire parmi les universitaires et les scientifiques des données, car il est efficace pour gérer la manipulation de grands ensembles de données.
Compte tenu de se concentrer sur le traitement parallèle et l'immuabilité, la programmation fonctionnelle est particulièrement utile pour:
- Science des données
- Applications de feuille de calcul
- Applications de financement et de risque
- Le traitement par lots
Programmation fonctionnelle: C # vs f #
C # et F # sont des langues qui ont gagné en popularité ces dernières années. Bien qu'ils soient tous deux multi-paradigmes, leur objectif principal diffère, avec C # s'appuyant sur des principes impératifs orientés objet et F # s'appuyant sur les principes fonctionnels. Mais l'une surpasse-t-elle l'autre en ce qui concerne la programmation fonctionnelle?
Qu'est-ce que C # et qui l'utilise?
C # est un langage multi-paradigme et orienté objet publié pour la première fois par Microsoft il y a environ 20 ans. Comme vous pouvez le voir dans les statistiques d'utilisation ci-dessus, c'était la huitième langue la plus populaire parmi les développeurs en 2022, avec près d'un tiers des développeurs qui l'utilisent. Il a également des scores de satisfaction élevés, avec les deux tiers des utilisateurs C # disant qu'ils aiment l'utiliser.
C # trouve de nombreuses utilisations dans le développement des services Web et cloud, ainsi que le développement de jeux. Les entreprises de Microsoft à TrustPilot en passant par Stackoverflow créent des applications et des services avec C #.
Programmation fonctionnelle en C #
Bien que C # soit principalement orienté objet et mutable / avec état, il a des capacités fonctionnelles. Voici quelques façons d'implémenter le paradigme fonctionnel en C #.
Créer une immuabilité
Parce que les types de données en C # sont intrinsèquement mutables, lorsque vous souhaitez utiliser des principes de programmation fonctionnelle, vous devez créer une immuabilité. Et cela est plus compliqué que de simplement compter sur des types de données immuables dans F #. Plus précisément, pour créer des types immuables en C #, vous devez créer le type en lecture seule, supprimer les propriétés du setter, utiliser un constructeur pour fournir les paramètres, puis créer une nouvelle instance chaque fois qu'un changement d'état est nécessaire, plutôt que de muter une instance existante.
Utilisez des expressions Linq et Lambda
Microsoft a construit le cadre Linq (Language Integrated Query) spécifiquement pour introduire des fonctionnalités de programmation fonctionnelle dans C #. LINQ fournit des fonctions pour fonctionner sur des listes ou des séquences, y compris la cartographie (SELECT), le tri (ordonnance) et le filtrage (où). Chacune de ces expressions a des fonctions pour les arguments. Les expressions créent de nouvelles instances de la séquence plutôt que de muter la séquence existante. LINQ est particulièrement utile pour interroger les ensembles de données, que ce soit des tables SQL, des données XML ou d'autres sources.
Linq permet également l'utilisation d'expressions de lambda, qui sont essentiellement des fonctions anonymes. Les fonctions anonymes sont un aspect clé de la programmation fonctionnelle. Lambda Expressions peut agir comme arguments pour d'autres fonctions dans le code, créant des fonctions d'ordre supérieur, une autre caractéristique commune de la programmation fonctionnelle.
Utiliser des chaînes de méthode
Une caractéristique couramment utilisée de F # est l'opérateur de pipeline, qui passe le résultat d'une fonction à une autre fonction. Le pipeline n'est pas intégré à C, mais les développeurs peuvent imiter les pipelines dans certaines situations à l'aide de chaînes de méthode, ou d'interfaces courantes. Cela peut être effectué en utilisant la fonctionnalité StringBuilder en C #.
Les chaînes de méthode vous permettent également de reproduire une autre caractéristique commune de la programmation fonctionnelle, du curry. Le curry permet une fonction avec plusieurs arguments pour recevoir ces arguments à différents moments. Essentiellement, dans la programmation fonctionnelle, si une fonction ne reçoit pas toutes les entrées nécessaires, il renvoie une nouvelle fonction avec les entrées manquantes comme arguments.
En C #, vous implémentez le curry avec des chaînes de méthode pour décomposer un argument multifonction dans une séquence imbriquée de plusieurs fonctions d'argument unique. Cependant, ce n'est pas aussi soigné ou aussi efficace que dans F #.
Ce ne sont que quelques-unes des façons dont les développeurs C # qualifiés peuvent appliquer des principes de programmation fonctionnelle en C #. Et bien qu'ils puissent avoir besoin de plus d'efforts que simplement de l'utilisation de F #, pour les développeurs qui veulent toutes les autres fonctionnalités que C # a à offrir, ils sont une alternative viable.
Qu'est-ce que F # et qui l'utilise?
Initialement publié par Microsoft pour la plate-forme Windows en 2005, F # est un langage de programmation principalement fonctionnel. Il s'est étendu pour englober les plates-formes Linux et MacOS en 2010, puis JavaScript en 2013. De plus, en 2013, la Fondation du logiciel F # a été lancée pour prendre en charge Microsoft dans son développement et à la fois F # et la communauté F #.
Depuis sa création, la communauté F # a augmenté régulièrement, si lentement. Il comprend désormais un groupe GitHub ainsi que de nombreux projets communautaires différents, des transpiles JavaScript (Fable) aux gestionnaires de packages (PAKET) aux bibliothèques de développement Web (suave) et plus.
Malgré son âge, F # a toujours une place importante pour l'adoption. Les statistiques générales d'utilisation sont un peu difficiles à trouver, mais une enquête en 2021 par JetBrains de plus de 30000 développeurs a indiqué que seulement 1% avaient récemment utilisé F # ou prévoyaient de le faire dans un avenir proche. En comparaison, 21% avaient récemment utilisé C # et 4% prévoyaient de l'utiliser bientôt. Et F # a une cote de satisfaction légèrement inférieure que C #, bien que plus de 60% des développeurs disent qu'ils aiment l'utiliser.
Actuellement, il y a moins de 100 entreprises qui sont connues pour utiliser F # en production, bien qu'elles incluent des noms bien connus comme Walmart et Huddle.
Certains développeurs utilisent F # comme complément à C #, plutôt que de s'appuyer sur les capacités fonctionnelles qui existent nativement en C #. Parce que les deux se compilent à .Langues intermédiaires nettes (IL), il est possible d'utiliser les deux dans le même projet.
Quel langage a l'avantage pour la programmation fonctionnelle?
Il semble que cela devrait être une question très simple à répondre: F # est fonctionnel en premier, tandis que C # est impératif en premier, donc le bord va à F #. Et au plus haut niveau, cette déclaration est vraie. Mais le développement d'applications, comme la vie, est rarement assez simple pour l'application généralisée des vérités de haut niveau.
La meilleure question à poser est quelle langue vous convient, votre équipe et les projets sur lesquels vous travaillez en ce moment. Et c'est une question beaucoup plus complexe à répondre.
Choisir le bon langage pour la programmation fonctionnelle
Lors de la sélection entre C # et F # pour vos besoins en programmation fonctionnelle, il existe plusieurs considérations qui devraient prendre en compte votre décision:
- Quels sont les besoins du projet? Les ensembles de fonctionnalités spécifiques de votre application peuvent vous faire un long chemin dans le processus de décision. Par exemple, si les fonctionnalités les plus importantes de votre application tournent autour des éléments de l'interface utilisateur, avec seulement une manipulation de données mineures, vous voudrez peut-être vous concentrer sur C #. Mais si votre application est à forte intensité de données et que les éléments d'interface utilisateur sont moins importants, vous vous pencherez probablement vers F #.
- Quel est votre niveau de confort avec chaque langue? Si votre application bénéficiera d'une programmation fonctionnelle, mais que vous êtes’t Expérimenté avec C # pour gérer facilement les manipulations nécessaires pour fabriquer des types immuables et se traduire des déclarations aux expressions, alors vous devriez considérer F #.
- Comment votre équipe traitera-t-elle avec différentes langues? Lorsque vous travaillez avec une équipe de développement, vous devez considérer les compétences et l'expérience de chaque membre de l'équipe. Vous pouvez avoir un développeur F # très qualifié, mais d'autres avec peu ou pas d'exposition à F #. Cela peut entraîner des difficultés pour les membres de l'équipe dans le travail avec le code écrit par d'autres développeurs.
- Est une approche multi-langues le meilleur? Votre équipe de développement est-elle suffisamment qualifiée pour que C # et F # travaillent ensemble sur le même projet? Y a-t-il des raisons que l'une ou l'autre de ces langues seule’T répond suffisamment à tous les besoins de votre application? Mais réfléchissez attentivement avant d'adopter cette approche - vous ne devriez le faire que s'il est plus efficace et plus efficace que d'utiliser l'une ou l'autre langue séparément.
Conclusion
Lorsqu'un projet de développement exige une programmation fonctionnelle, il existe de nombreuses options disponibles pour l'équipe de développement, des langages purement fonctionnels aux langages multi-paradigmes comme C # et F #. Faire le meilleur choix parmi les bonnes options concurrentes n'est pas toujours simple, mais le temps investi dans la prise de cette décision sera récompensé par l'amélioration des efficacités de développement et des produits mieux finaux.