


Facebook a-t-il ses propres centres de données
Facebook a-t-il ses propres centres de données?
Résumé:
Meta (anciennement Facebook) compte actuellement 47 centres de données en construction, avec des plans pour avoir plus de 70 bâtiments dans un avenir proche. Cela reflète l’expansion mondiale des infrastructures mondiales de l’entreprise, avec 18 campus du centre de données dans le monde en totalisant 40 millions de pieds carrés. Malgré les défis posés par les perturbations de la pandémie et de la chaîne d’approvisionnement, Meta prévoit d’investir entre 29 milliards de dollars et 34 milliards de dollars de dépenses en capital en 2022.
Points clés:
- Meta a 47 centres de données en construction et plans pour plus de 70 bâtiments dans un avenir proche.
- L’entreprise dispose de 18 campus de centre de données dans le monde.
- L’expansion pendant les perturbations pandémiques et de la chaîne d’approvisionnement est difficile.
- Meta s’attend à investir entre 29 milliards de dollars et 34 milliards de dollars de dépenses en capital en 2022.
- Les opérateurs d’hyperscale comme Meta et Microsoft versent des milliards dans l’élargissement de leur infrastructure de centre de données.
- Open Calcul Project, fondé par Facebook, entraîne l’innovation dans le matériel.
- La construction du centre de données nécessite une sélection et des processus de construction flexibles du site.
- Meta s’occupe des vendeurs et des entrepreneurs en tant que partenaires dans la conduite des meilleures pratiques et une amélioration continue.
- Les méta-opérateurs de méta et d’autres hyperscales sont pionnières de nouvelles stratégies pour fournir une échelle et une vitesse.
- L’échelle et le défi du programme du centre de données sont un moteur de Meta.
Des questions:
- Quel est l’état actuel de la construction du centre de données de META?
- Combien de campus de centre de données Meta a-t-il dans le monde entier?
- Quels défis sont confrontés à la méta dans l’expansion du centre de données?
- Dans quelle mesure Meta prévoit-elle d’investir dans les dépenses en capital en 2022?
- Quelles entreprises investissent également dans l’expansion des infrastructures de centre de données?
- Quel est le rôle du projet de calcul ouvert?
- Quels facteurs sont importants dans la construction du centre de données?
- Comment Meta Vieille-t-il les vendeurs et les entrepreneurs?
- Quelles stratégies sont Meta et autres opérateurs d’hyperscale pionnière?
- Ce qui motive le programme de centre de données de Meta?
Meta compte actuellement 47 centres de données en construction, avec des plans pour plus de 70 bâtiments dans un avenir proche.
Meta a 18 campus de centre de données dans le monde.
L’expansion du centre de données pendant les perturbations pandémiques et de la chaîne d’approvisionnement pose des défis pour Meta.
Meta s’attend à investir entre 29 milliards de dollars et 34 milliards de dollars de dépenses en capital en 2022.
Les opérateurs d’hyperscale comme Microsoft investissent également des milliards pour étendre leur infrastructure de centre de données.
Le projet de calcul ouvert, fondé par Facebook, entraîne l’innovation dans le matériel.
La construction du centre de données nécessite une sélection et des processus de construction flexibles du site.
Meta considère les vendeurs et les entrepreneurs comme des partenaires dans la conduite des meilleures pratiques et une amélioration continue.
Les méta-opérateurs de méta et d’autres hyperscales sont pionnières de nouvelles stratégies pour fournir une échelle et une vitesse.
L’échelle et le défi du programme du centre de données sont un moteur de Meta.
Facebook a-t-il ses propres centres de données
Que fait d’autre Facebook? Frankovsky a déclaré que “beaucoup de cartes mères aujourd’hui viennent avec beaucoup de gestion de la gestion. C’est le terme technique que j’aime utiliser pour cela.”Ce GOOP pourrait être le moteur de gestion du cycle de vie intégré de HP ou les outils de gestion des serveurs distants de Dell.
Facebook possède 47 centres de données en construction
Meta compte actuellement 47 centres de données en construction, a déclaré la société cette semaine, reflétant la portée extraordinaire de l’expansion en cours du monde’s infrastructure numérique.

Il’s une courte déclaration, au fond d’une longue revue de l’innovation dans Facebook’s infrastructure numérique. Mais pour quiconque connaît l’industrie du centre de données, elle’s une véritable révélation des yeux.
“Comme je’M Écrivant ceci, nous avons 48 bâtiments actifs et 47 autres bâtiments en construction,” a déclaré Tom Furlong, président de l’infrastructure, centres de données de Meta (anciennement Facebook). “Alors on’Je vais avoir plus de 70 bâtiments dans un avenir proche.”
La déclaration reflète la portée extraordinaire de la méta’s Expansion mondiale des infrastructures. L’entreprise possède 18 campus de centre de données dans le monde, qui, à la fin, s’étendra sur 40 millions de pieds carrés d’espace de centre de données.
Avoir 47 bâtiments en construction serait un défi en toutes circonstances, mais en particulier lors d’une perturbation mondiale de la pandémie et de la chaîne d’approvisionnement. Il’n’est pas facile ou bon marché. Meta dit qu’elle s’attend à investir entre 29 milliards de dollars et 34 milliards de dollars de dépenses en capital en 2022, contre 19 milliards de dollars l’année dernière.
Il’n’est pas le seul, car les plus grands opérateurs d’hyperscale déversent des milliards de dollars dans l’élargissement de leur infrastructure de centre de données pour répondre à la demande de services numériques. Les dépenses en capital hyperscale ont augmenté de 30% au premier seme.
Ces niveaux de dépenses pourraient facilement augmenter, à la lumière de Facebook’S Projections sur les dépenses CAPEX futures et Microsoft’S prévoit de construire 50 à 100 centres de données par an.
Innovation d’infrastructure à l’échelle épique
Cale’S Blog Blog sur Meta’S Data Center Journey vaut la peine d’être lu, tout comme un article compagnon qui revient sur la progression du projet Open Calcul, l’Open Hardware Initiative fondée par Facebook en 2011.
“Le matériel ouvert entraîne l’innovation et travailler avec plus de fournisseurs signifie plus d’opportunité de développer du matériel de nouvelle génération pour prendre en charge les fonctionnalités actuelles et émergentes sur Meta’S La famille de technologies.,” Furlong écrit.
La nécessité d’innover à grande échelle a également l’inclusion de la construction du centre de données.
“Il y a beaucoup d’activités dans le centre de données et les industries de la construction aujourd’hui, ce qui nous fait pression pour trouver les bons sites et partenaires,” dit furlong. “Cela signifie également que nous devons créer des processus de sélection et de construction de sites plus flexibles. Tout cet effort consiste également à regarder nos fournisseurs et nos entrepreneurs davantage en tant que partenaires dans tout cela. Nous pouvons’t fait juste à propos des dollars. Nous devons faire des performances. Nous devons faire la conduite des meilleures pratiques et une amélioration continue.
“Mais ça’n’est pas la façon dont l’industrie de la construction fonctionne généralement,” il a continué. “Alors on’Ve a dû apporter beaucoup de nos propres idées sur l’exécution des opérations et les améliorations et les impressionner sur les entreprises avec lesquelles nous travaillons.”
L’infrastructure numérique devient de plus en plus importante chaque jour, et Meta et ses homologues à hyperscale sont pionnières de nouvelles stratégies pour fournir l’échelle et la vitesse dont ils ont besoin. Il’est un processus en cours, comme le reflète Furlong.
“Déménager dans l’arène du centre de données n’allait jamais être facile,” il écrit. “Mais je pense que nous’Ve s’est retrouvé avec un programme incroyable à une échelle que je n’aurais jamais imaginée. Et nous’On leur demande toujours d’en faire plus. Ce’s le défi commercial, et il’est probablement l’une des principales choses qui me maintiennent et mon équipe qui vient travailler tous les jours. Nous avons cet énorme défi devant nous pour faire quelque chose qui est incroyablement massif à grande échelle.”
Facebook a-t-il ses propres centres de données


Retour au blog à la maison
с 20 2016
Infrastructure Facebook: stratégie et développement du centre de données intérieur
Par méta-carrières
Rachel Peterson dirige l’équipe de stratégie du centre de données de l’infrastructure de Facebook. Son équipe gère le portefeuille de centres de données de Facebook et fournit un soutien stratégique pour identifier les opportunités pour de nouvelles infrastructures de durabilité, d’efficacité et de fiabilité. Jetez un œil à son expérience sur Facebook et comment son équipe travaille à la connexion du monde.
Quelle est votre histoire Facebook?
J’ai rejoint Facebook en 2009 lorsque la société était sur le point de lancer son premier centre de données à Prineville, Oregon. À cette époque, toute l’équipe du centre de données comprenait moins de 30 membres de l’équipe et Facebook a occupé deux petites empreintes de co-location aux États-Unis. J’ai rejoint pour aider à développer le programme de sélection du site pour les centres de données propriétaires de Facebook. Aujourd’hui, notre équipe comprend plus de 100 personnes dans plusieurs endroits à travers le monde.
Avance rapide jusqu’à aujourd’hui, Facebook possède désormais et exploite un grand portefeuille de centres de données, couvrant les États-Unis, l’Europe et l’Asie. Le programme de sélection du site a lancé avec succès quinze centres de données massifs, et nous nous engageons à alimenter ces centres de données avec 100% d’énergie renouvelable. En 2012, nous avons fixé notre premier objectif de 25% d’énergie propre et renouvelable dans notre mélange d’approvisionnement en électricité en 2015 pour tous les centres de données. En 2017, nous avons dépassé 50% d’énergie propre et renouvelable pour toutes les opérations de Facebook. En 2018, nous avons fixé notre prochain objectif agressif – visant à rencontrer des énergies 100% propres et renouvelables pour toutes les opérations de croissance de Facebook d’ici la fin de 2020.
Il a été vraiment excitant d’être à l’avant-garde de cette croissance et de constituer l’équipe qui a joué un rôle essentiel dans la croissance de l’infrastructure de Facebook. Il n’y a jamais eu de moment ennuyeux dans ce voyage incroyable! La croissance de Facebook a rendu les choses à la fois stimulantes et amusantes, et je ne pense pas qu’un jour se passe là où je n’ai pas appris. J’adore ce que je fais et j’ai vraiment la chance de travailler avec une équipe aussi incroyable et amusante. La culture de Facebook permet à mon équipe d’avoir un impact de grande envergure, et ensemble, nous rendons le monde plus ouvert et connecté. un centre de données à la fois.

La mission de Facebook est de rendre le monde plus ouvert et connecté, quel rôle votre équipe a-t-elle dans ce?
Dirige la stratégie mondiale de localisation de Facebook et les efforts de sélection du site basés sur un certain nombre de critères de location critiques, y compris de nouvelles énergies renouvelables pour soutenir les sites.
Gère les programmes mondiaux mondiaux de conformité environnementale de Facebook, de la sélection des sites à travers les opérations, y compris la conformité à l’air et à l’eau.
Dirige les programmes d’énergie mondiale de Facebook, de la sélection du site tout au long des opérations, l’optimisation de l’approvisionnement énergétique des énergies renouvelables à 100%, tout en assurant la responsabilité budgétaire et la fiabilité.
Mène la planification stratégique, l’activation et la surveillance de la feuille de route du centre mondial.
Fournit un support de science des données pour permettre les décisions stratégiques et l’optimisation des performances tout au long du cycle de vie du centre de données.
Mène notre travail d’engagement communautaire dans des endroits où nous avons des centres de données.
Élabore et gère les stratégies d’atténuation des politiques et des risques pour permettre l’expansion mondiale de Facebook’S INFRASTRUCTURE FOOTPRINT.
Facebook s’est engagé à être une force pour le bien partout où nous travaillons en fournissant des emplois, en cultivant l’économie et en soutenant les programmes qui bénéficient aux communautés dans lesquelles nous vivons.
Notre équipe de durabilité’La mission est de soutenir Facebook’S Capacité à opérer et à se développer efficacement et de manière responsable et à autonomiser les gens à construire des communautés durables.
Dirige la stratégie à l’échelle de l’entreprise dans la motivation de l’excellence opérationnelle de la conception, de la construction et du fonctionnement de notre entreprise. Nous priorisons l’efficacité, la conservation de l’eau et l’excellence de la chaîne d’approvisionnement et sommes fiers de dire que nos installations sont parmi les plus économes en eau et en énergie au monde.
Nous nous engageons à lutter contre le changement climatique et avons fixé un objectif scientifique pour réduire nos émissions de 75% d’ici 2020.

Les valeurs fondamentales de Facebook se déplacent rapidement, se concentrent sur l’impact, créez une valeur sociale, soyez ouvert, soyez audacieux. Quelle valeur résonne vraiment avec votre équipe?
Concentrez-vous sur l’impact. Notre équipe est relativement maigre et pourtant nous avons la capacité de fournir de nombreuses initiatives à fort impact pour l’entreprise.
Qu’est-ce que la plupart des gens ne savent pas de votre équipe?
Nous avons une équipe très diversifiée composée d’avocats, de gestionnaires de politique publique, d’analystes financiers, de gestionnaires de programmes, de scientifiques des données, de professionnels de l’énergie, d’ingénieurs et d’experts des processus commerciaux.
Pouvez-vous partager d’être un leader féminin dans l’industrie technologique et de l’importance de la diversité sur Facebook et Tech en général?
L’une des raisons pour lesquelles j’aime travailler sur Facebook est notre engagement envers la diversité. La diversité n’est pas une activité parascolaire sur Facebook, mais plutôt quelque chose que nous visons à mettre en œuvre à tous les niveaux de l’entreprise. Même si nous et l’industrie technologique dans son ensemble, avons plus de travail à faire ici, nous renforçons continuellement cet engagement à travers notre culture, nos produits et nos priorités d’embauche.
En tant que femme en technologie, je sais de première main à quel point la diversité est importante pour notre industrie et comment les perspectives diverses stimulent de meilleurs résultats. Il est extrêmement important que nous fassions tout notre possible pour améliorer l’embauche de divers candidats et encourager les femmes à rejoindre des secteurs qui sont généralement dominés par les hommes. J’ai trouvé ma carrière en appelant dans la sélection du site immobilier, une industrie traditionnellement dominée par les hommes, et j’ai trouvé mon inspiration à travers les nombreuses femmes talentueuses qui m’ont inspiré et encadré en cours de route. Aujourd’hui, en tant que femme leader de la technologie, c’est mon devoir et mon privilège d’être un mentor pour les femmes, et de faire ce que je peux pour soutenir activement la croissance et l’avancement des femmes dans cette industrie.
Mon conseil pour les femmes? Trouvez vos passions et suivez-les, même si vous finissez par être dans une zone où vous’RE Normalement la seule femme dans la pièce. Vos forces se développeront à travers vos passions et vous’travaillera plus dur sur votre métier. Votre carrière trouvera sa propre trajectoire. Plus important encore, permettez-vous de l’échec de l’échec et revenez tout de suite si vous tombez en cours de route.
Facebook a-t-il ses propres centres de données

Facebook’Les services S s’appuient sur des flottes de serveurs dans les centres de données du monde. C’est pourquoi nous devons nous assurer que le matériel de notre serveur est fiable et que nous pouvons gérer les défaillances du matériel du serveur à notre échelle avec aussi peu de perturbation que possible de nos services.
Les composants matériels eux-mêmes peuvent échouer pour un certain nombre de raisons, y compris la dégradation des matériaux (E.g., Les composants mécaniques d’un disque dur en rotation), un appareil étant utilisé au-delà de son niveau d’endurance (E.g., NAND Flash Devices), Impacts environnementaux (E.g., corrosion due à l’humidité) et des défauts de fabrication.
En général, nous nous attendons toujours à un certain degré de défaillance matérielle dans nos centres de données, c’est pourquoi nous implémentons des systèmes tels que notre système de gestion de cluster pour minimiser les interruptions de service. Dans cet article, nous’RE introduisant quatre méthodologies importantes qui nous aident à maintenir un degré élevé de disponibilité matérielle. Nous avons construit des systèmes qui peuvent détecter et résoudre les problèmes . Nous surveillons et résonnons les événements matériels sans avoir un impact négatif sur les performances de l’application . Nous adoptons des approches proactives pour les réparations matérielles et utilisons la méthodologie de prédiction pour les corrections . Et nous automatiserons l’analyse des causes profondes pour les défaillances matérielles et système à grande échelle pour atteindre rapidement les problèmes.
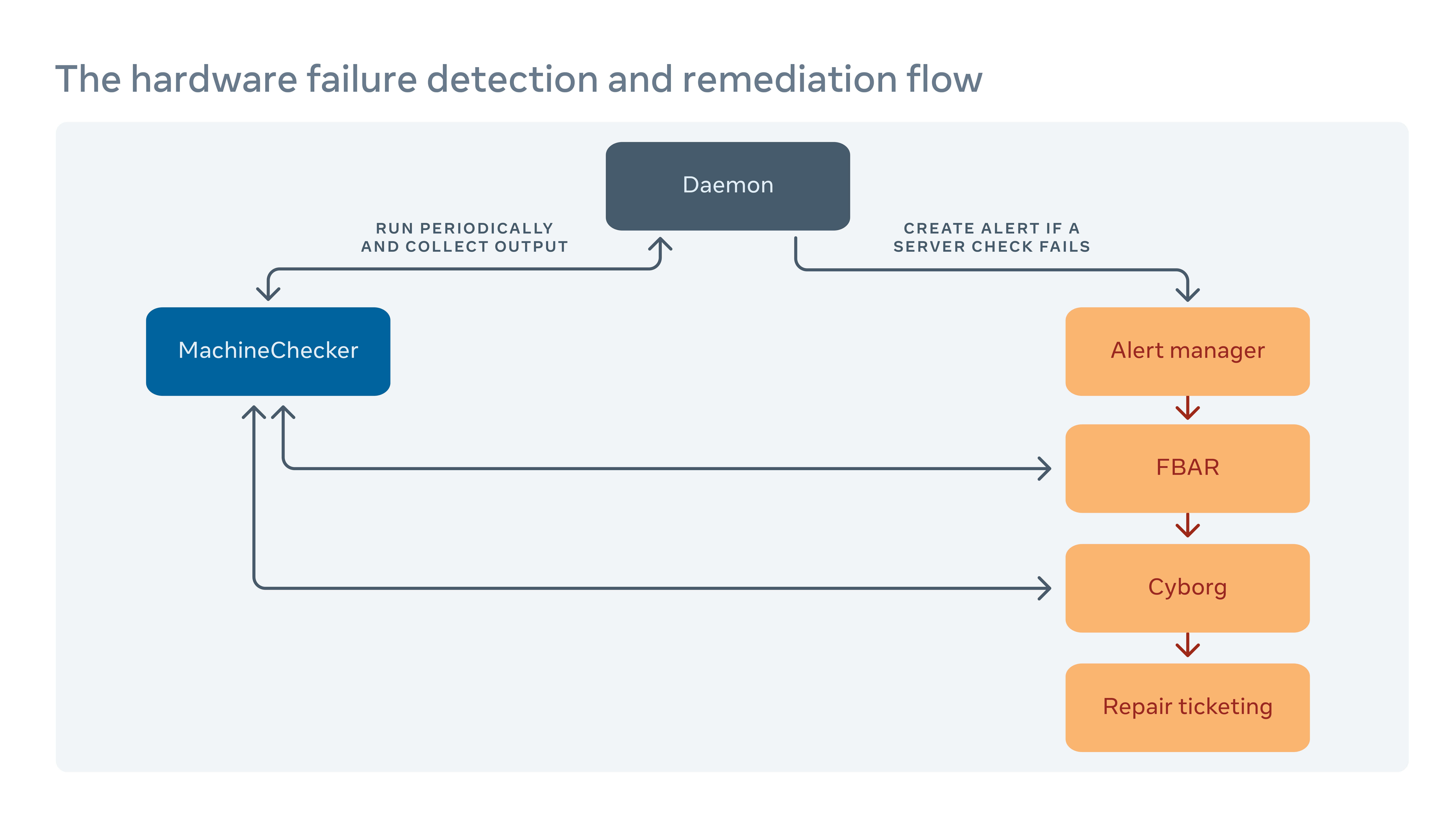
Comment nous gérons la correction matérielle
Nous exécutons périodiquement un outil appelé MachineChecker sur chaque serveur pour détecter les défaillances matérielles et de connectivité. Une fois que MachineChecker crée une alerte dans un système de manutention d’alerte centralisé, un outil appelé Facebook Auto REMEMIATION (FBAR), puis prend l’alerte et exécute des remèdes personnalisables pour réparer l’erreur. Pour s’assurer qu’il y a’s encore suffisamment de capacité pour Facebook’S Services, nous pouvons également fixer des limites de taux pour restreindre le nombre de serveurs répartis à un moment donné.
Si fbar peut’T ramener un serveur à un état sain, l’échec est transmis à un outil appelé cyborg. Cyborg peut exécuter des corrections de niveau inférieur telles que les mises à niveau du micrologiciel ou du noyau, et la réimagerie. Si le problème nécessite une réparation manuelle d’un technicien, le système crée un billet dans notre système de billetterie de réparation.
Nous approfondissons ce processus dans notre article “Rassourtissement matériel à grande échelle.”
Comment nous minimions l’impact négatif des rapports d’erreur sur les performances du serveur
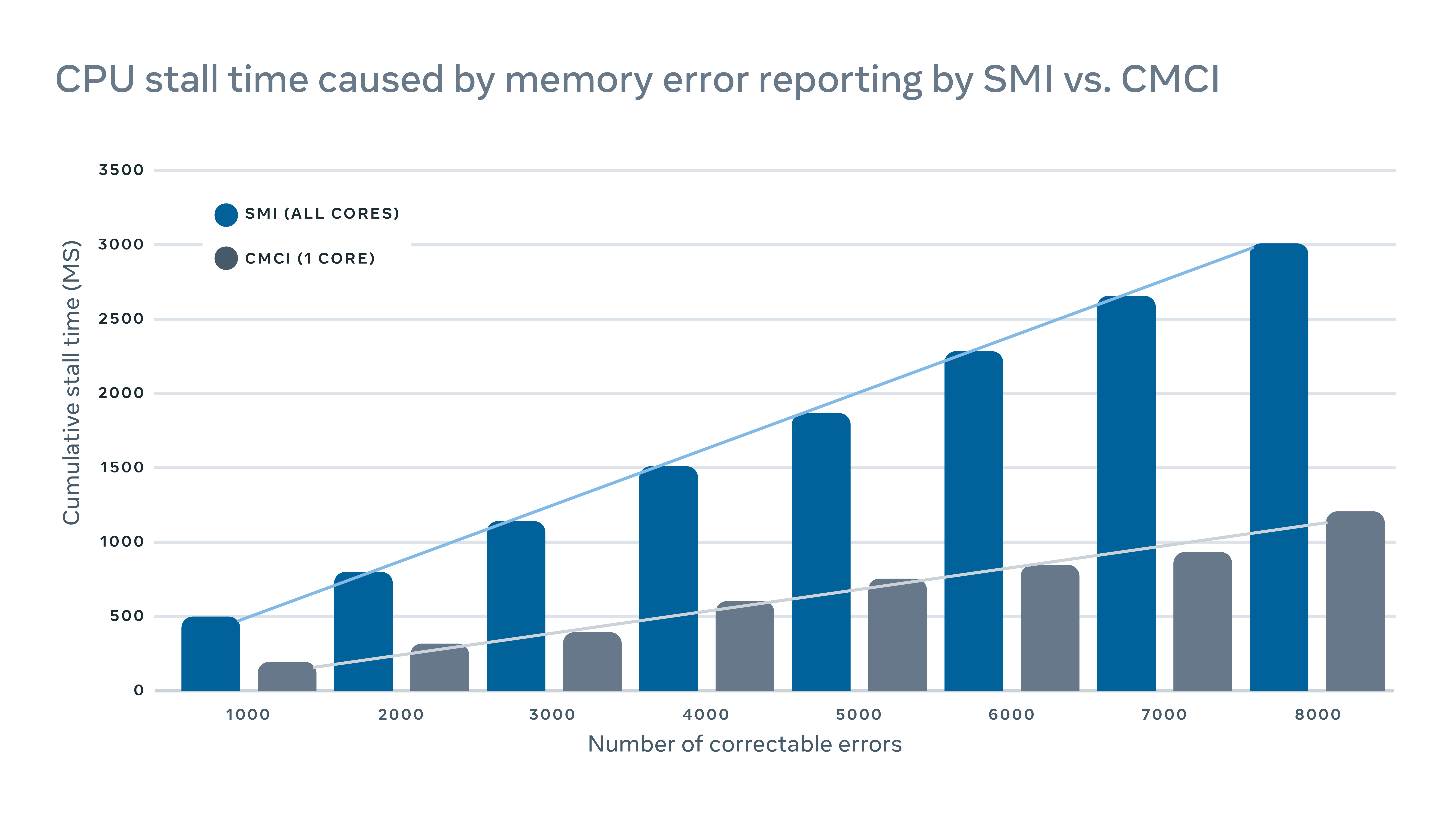
MachineChecker détecte les défaillances matérielles en vérifiant divers journaux de serveurs pour les rapports d’erreur. En règle générale, lorsqu’une erreur matérielle se produit, elle sera détectée par le système (E.g., Échec d’un contrôle de parité) et un signal d’interruption sera envoyé au CPU pour gérer et enregistrer l’erreur.
Étant donné que ces signaux d’interruption sont considérés. Mais cela a un impact sur les performances négatives sur le serveur. Pour l’exploitation des erreurs de mémoire correctes, par exemple, une interruption traditionnelle de gestion du système (SMI) bloquerait tous les noyaux CPU, tandis que l’interruption de vérification de la machine (CMCI) corrigeait qu’un seul des noyaux CPU, laissant le reste des cœurs CPU disponibles pour un fonctionnement normal.
Bien que les stands du processeur ne durent généralement que quelques centaines de millisecondes, ils peuvent toujours perturber les services sensibles à la latence. À l’échelle, cela signifie que les interruptions sur quelques machines peuvent avoir un impact négatif en cascade sur les performances au niveau du service.
Pour minimiser l’impact des performances causée par les rapports d’erreurs, nous avons implémenté un mécanisme hybride pour les rapports d’erreur de mémoire qui utilisent à la fois CMCI et SMI sans perdre la précision en termes de nombre d’erreurs de mémoire corrigées.
Comment nous tirons parti de l’apprentissage automatique pour prédire les réparations
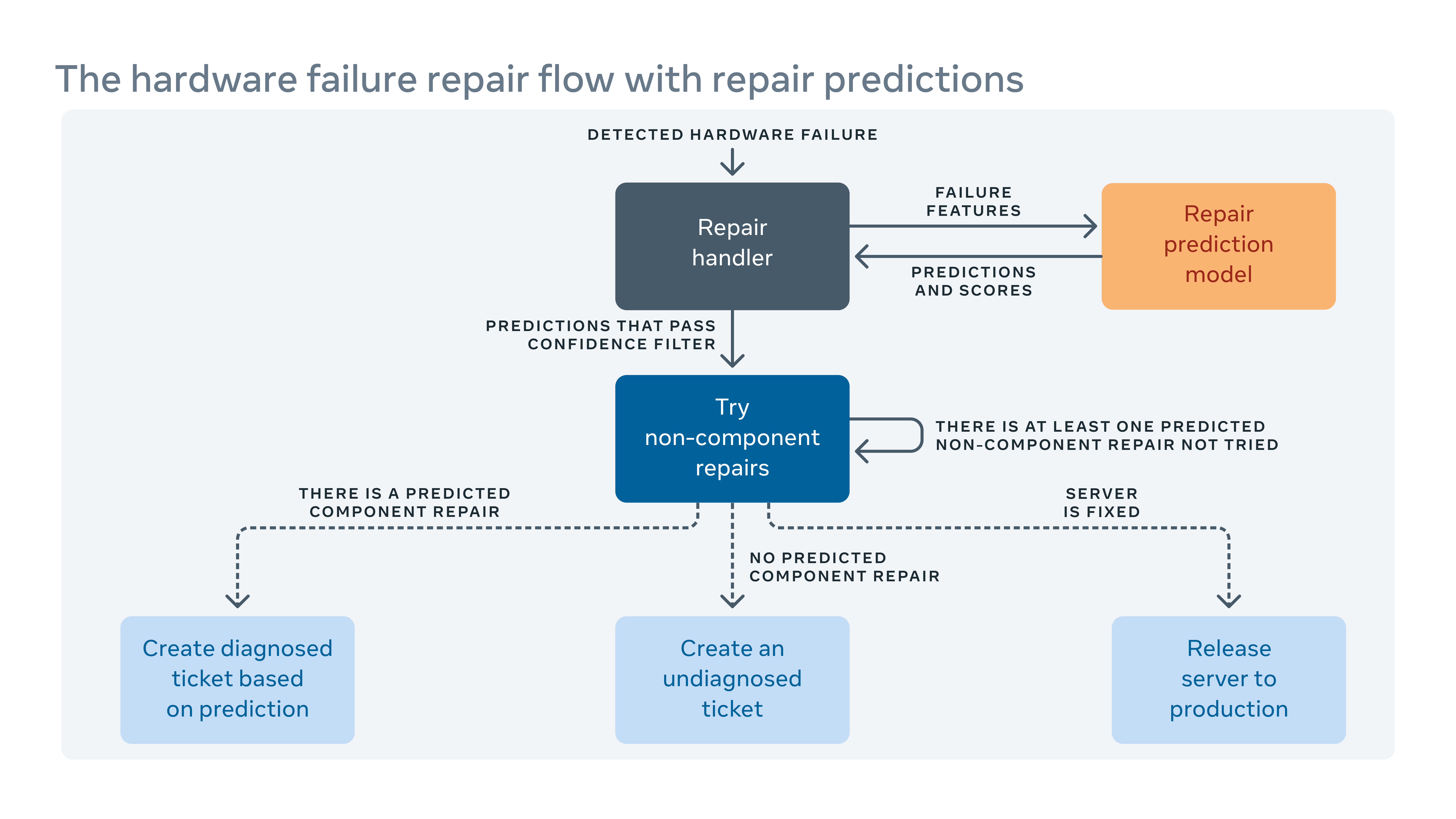
Étant donné que nous introduisons fréquemment de nouvelles configurations matérielles et logicielles dans nos centres de données, nous devons également créer de nouvelles règles pour notre système de rééducation automatique.
Lorsque le système automatisé ne peut pas résoudre une défaillance matérielle, le problème se voit attribuer un billet pour la réparation manuelle. Le nouveau matériel et les logiciels signifient de nouveaux types d’échecs potentiels qui doivent être traités. Mais il pourrait y avoir une lac. Au cours de cet écart, certains billets de réparation pourraient être classés comme “non diagnostiqué,” ce qui signifie que le système n’a pas’t a suggéré une action de réparation, ou “mal diagnostiqué,” ce qui signifie que l’action de réparation suggérée n’est pas’t efficace. Cela signifie plus de travail et de temps d’arrêt du système tandis que les techniciens doivent diagnostiquer le problème eux-mêmes.
Pour combler l’écart, nous avons construit un cadre d’apprentissage automatique qui apprend de la façon dont les échecs ont été résolus dans le passé et essaie de prédire quelles réparations seraient nécessaires aux billets de réparation actuels non diagnostiqués et mal diagnostiqués. Sur la base du coût et des bénéfices des prévisions incorrectes et correctes, nous attribuons un seuil sur la confiance de prédiction pour chaque action de réparation et optimiser l’ordre des actions de réparation. Par exemple, dans certains cas, nous préférerions essayer un redémarrage ou une mise à niveau du firmware d’abord parce que ces types de réparations’T a besoin de toute réparation de matériel physique et prenez moins de temps à terminer, de sorte que l’algorithme doit recommander ce type d’action en premier. Clairement, l’apprentissage automatique nous permet non seulement de prédire comment réparer un problème non diagnostiqué ou mal diagnostiqué, mais aussi de hiérarchiser les plus importants.
Comment nous’Ve Automated Fleet au niveau des causes racinaires
En plus des journaux de serveurs qui enregistrent les redémarrages, les paniques du noyau hors mémoire, etc., Il existe également des journaux de logiciels et d’outillage dans notre système de production. Mais l’échelle et la complexité de tout cela le signifie’s Difficile d’examiner tous les journaux conjointement pour trouver des corrélations entre elles.
Nous avons mis en œuvre un outil d’évaluation de crise de cause dynamique (RCA) qui trie à travers des millions d’entrées de journal (chacune décrite par des centaines de colonnes) pour trouver des corrélations faciles à comprendre et exploitables.
Avec la pré-agrégation des données à l’aide de la plongée, une base de données en mémoire en temps réel, nous avons considérablement amélioré l’évolutivité d’un algorithme d’exploration de motifs traditionnel, la croissance FP, pour trouver des corrélations dans ce cadre RCA. Nous avons également ajouté un ensemble de filtres sur les corrélations signalées pour améliorer l’interprétabilité du résultat. Nous avons déployé cet analyseur largement à l’intérieur de Facebook pour le taux de défaillance du composant matériel sur RCA, les redémarrages de serveurs inattendus et les défaillances du logiciel.
Qui a besoin de HP et Dell? Facebook conçoit maintenant tous ses propres serveurs
Le dernier centre de données de Facebook n’aura pas de serveurs OEM.
Jon Brodkin – 14 février 2013 22:35 PM UTC

Commentaires du lecteur
Il y a près de deux ans, Facebook a dévoilé ce qu’il a appelé le projet de calcul ouvert. L’idée était de partager des conceptions pour le matériel de centre de données comme les serveurs, le stockage et les racks afin que les entreprises puissent construire leur propre équipement au lieu de s’appuyer sur les options étroites fournies par les fournisseurs de matériel.
Alors que n’importe qui pourrait en bénéficier, Facebook a ouvert la voie à déployer le matériel sur mesure dans ses propres centres de données. Le projet a maintenant avancé au point où tous les nouveaux serveurs déployés par Facebook ont été conçus par Facebook lui-même ou conçu par d’autres vers les spécifications exigeantes de Facebook. L’équipement personnalisé aujourd’hui occupe plus de la moitié de l’équipement dans les centres de données Facebook. Ensuite, Facebook ouvrira un centre de données de 290 000 pieds carrés en Suède entièrement stocké avec des serveurs de sa propre conception, une première pour la société.
“C’est le premier où nous allons avoir des serveurs de calcul ouverts à 100% à l’intérieur”, a déclaré Frank Frankovsky, vice-président des opérations de conception matérielle et de chaîne d’approvisionnement sur Facebook, à ARS dans une interview téléphonique cette semaine.
Comme les centres de données existants de Facebook en Caroline du Nord et en Oregon, celui qui sera en ligne cet été à Luleå, la Suède aura des dizaines de milliers de serveurs. Facebook met également son équipement dans un espace de centre de données loué pour maintenir une présence près des utilisateurs du monde entier, y compris sur 11 sites de colocation aux États-Unis. Divers facteurs contribuent au choix des emplacements: taxes, travail technique disponible, source et coût du pouvoir et le climat. Facebook n’utilise pas la climatisation traditionnelle, en s’appuyant complètement sur “l’air extérieur et un système de refroidissement évaporatif unique pour garder nos serveurs assez frais”, a déclaré Frankovsky.
Économiser de l’argent en éliminant ce que vous ne faites pas’t besoin
À l’échelle de Facebook, il est moins cher de maintenir ses propres centres de données que de s’appuyer sur les fournisseurs de services cloud, il a noté. De plus, il est également moins cher pour Facebook d’éviter les fournisseurs de serveurs traditionnels.
Comme Google, Facebook conçoit ses propres serveurs et les a construits par ODMS (fabricants de conception d’origine) à Taiwan et en Chine, plutôt que par les OEM (fabricants d’équipements d’origine) comme HP ou Dell. En roulant, Facebook élimine ce que Frankovsky appelle la «différenciation gratuite», les fonctionnalités matérielles qui rendent les serveurs uniques mais ne profitent pas à Facebook.
Cela pourrait être aussi simple que la lunette plastique sur un serveur avec un logo de marque, car ce peu de matériel supplémentaire oblige les fans à travailler plus dur. Frankovsky a déclaré qu’une étude a montré un serveur OEM de taille 1U standard “a utilisé 28 watts de puissance de ventilateur pour tirer l’air à travers l’impédance causée par cette lunette en plastique”, tandis que le serveur de calcul ouvert équivalent n’a utilisé que trois watts à cet effet.

Que fait d’autre Facebook? Frankovsky a déclaré que “beaucoup de cartes mères aujourd’hui viennent avec beaucoup de gestion de la gestion. C’est le terme technique que j’aime utiliser pour cela.”Ce GOOP pourrait être le moteur de gestion du cycle de vie intégré de HP ou les outils de gestion des serveurs distants de Dell.
Ces fonctionnalités pourraient bien être utiles à de nombreux clients, en particulier s’ils ont standardisé sur un fournisseur. Mais à la taille de Facebook, il n’a pas de sens de compter sur un seul fournisseur, car “une faute de conception pourrait prendre une grande partie de votre flotte ou parce qu’une pénurie de parties pourrait islader votre capacité à livrer un produit à vos centres de données.”
Facebook a ses propres outils de gestion du centre de données, donc les choses HP ou Dell sont inutiles. Un produit de fournisseur “est livré avec son propre ensemble d’interfaces utilisateur, un ensemble d’API et une jolie interface graphique pour vous dire à quelle vitesse les fans tournent et certaines choses qui, en général, déploient ces choses à l’échelle. “C’est différent d’une manière qui n’a pas d’importance pour moi. Cette instrumentation supplémentaire sur la carte mère, non seulement cela coûte de l’argent pour l’acheter dans le point de vue des matériaux, mais cela provoque également une complexité des opérations.”
Un chemin pour HP et Dell: adapter pour ouvrir le calcul
Cela ne signifie pas que Facebook jure HP et Dell pour toujours. “La plupart de notre nouvel équipement est construit par ODMS comme Quanta”, a déclaré la société dans une réponse par e-mail à l’une de nos questions de suivi. “Nous faisons plusieurs sources de tous nos équipements, et si un OEM peut construire à nos normes et l’apporter à moins de 5%, alors il se trouve généralement dans ces discussions multi-sources.”
HP et Dell ont commencé à fabriquer des conceptions conformes pour ouvrir les spécifications de calcul, et Facebook a déclaré qu’il en testait un de HP pour voir s’il peut faire la coupe. La société a confirmé, cependant, que son nouveau centre de données en Suède n’inclurait aucun serveur OEM lors de son ouverture.
Facebook dit qu’il obtient des économies financières de 24% en raison d’une infrastructure à moindre coût, et cela permet d’économiser 38% des coûts opérationnels en cours en raison de la construction de ses propres trucs. Les serveurs personnalisés de Facebook n’exécutent pas de charges de travail différentes que tout autre serveur, ils les exécutent plus efficacement.
“Un serveur HP ou Dell, ou ouvrir un serveur de calcul, ils peuvent tous exécuter les mêmes charges de travail”, a déclaré Frankovsky. “C’est juste une question de travail que vous faites par watt par dollar.”
Facebook ne virtualise pas ses serveurs, car son logiciel consomme déjà toutes les ressources matérielles, ce qui signifie que la virtualisation entraînerait une pénalité de performance sans gain d’efficacité.
Le géant des médias sociaux a publié les conceptions et les spécifications de ses propres serveurs, cartes mères et autres équipements. Par exemple, la carte mère “Windmill” utilise deux processeurs Intel Xeon E5-2600, avec jusqu’à huit cœurs par CPU.
La fiche de spécification de Facebook le décompose:
- 2 processeurs Intel® Xeon® E5-2600 (LGA2011) jusqu’à 115W
- 2 liens d’interconnexion Intel Quickpath pleine largeur (QPI) jusqu’à 8 GT / S / Direction
- Jusqu’à 8 cœurs par CPU (jusqu’à 16 fils avec une technologie hyper-threading)
- Cache de dernier niveau jusqu’à 20 Mo
- Mode processeur unique
- DDR3 Prise en charge de la mémoire attachée directe sur CPU0 et CPU1 avec:
- Interface de mémoire enregistrée DDR3 à 4 canaux sur les processeurs 0 et 1
- 2 emplacements DDR3 par canal par processeur (total de 16 dimms sur la carte mère)
- Rdimm / lv-rdimm (1.5v / 1.35V), LRDIMM et ECC UDIMM / LV-UDIMM (1.5v / 1.35V)
- DIMMS simple, double et quad
- Vitesses DDR3 de 800/1066/1333/1600 MHz
- Jusqu’à maximum de 512 Go de mémoire avec 32 Go RDIMM DIMMS
Et maintenant un diagramme de la carte mère:
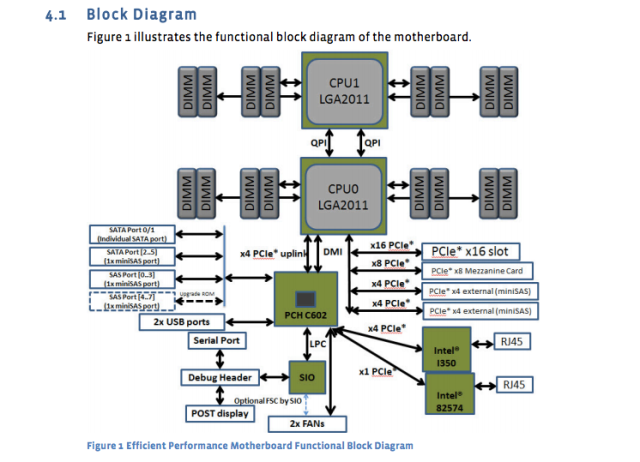
Ces spécifications de la carte mère ont été publiées il y a près d’un an, mais elles sont toujours la norme. Le serveur de base de données nouvellement conçu “Dragonstone” et le serveur Web “Winterfell” s’appuient sur la carte mère de Windmill, bien que les nouveaux processeurs Intel puissent frapper la production sur Facebook plus tard cette année.

Les conceptions de serveurs de Facebook sont adaptées à différentes tâches. Comme l’a rapporté le Timothy Prickett Morgan du registre le mois dernier, certaines fonctions de base de données sur Facebook nécessitent des alimentations redondantes, tandis que d’autres tâches peuvent être gérées par des serveurs avec plusieurs nœuds de calcul partageant une seule alimentation électrique.
Les centres de données utilisent un mélange de stockage flash et de disques de rotation traditionnels, avec des fonctionnalités Facebook en flash nécessitant les vitesses les plus rapides disponibles. Les serveurs de base de données utilisent tous les flash. Les serveurs Web ont généralement des processeurs très rapides, avec des quantités relativement faibles de stockage et de RAM. 16 Go est une quantité typique de RAM, a déclaré Frankovsky. Intel et AMD Chips ont tous deux une présence dans l’équipement Facebook.
Et Facebook est accablé de beaucoup de “stockage froid”, des trucs écrits une fois et rarement accessibles à nouveau. Même là-bas, Frankovsky veut utiliser de plus en plus Flash en raison du taux de défaillance des disques de rotation. Avec des dizaines de milliers d’appareils en fonctionnement, “nous ne voulons pas que les techniciens courent pour remplacer les disques durs”, a-t-il déclaré.
Le flash de classe centrale de données est généralement beaucoup plus cher que les disques de rotation, mais Frankovsky dit qu’il peut y avoir un moyen de lui faire la peine. “Si vous utilisez la classe de NAND [Flash] dans les lecteurs de pouce, qui est généralement considéré comme un NAND de balayage ou de ferraille, et que vous utilisez un type d’algorithme de contrôleur vraiment cool pour caractériser les cellules bonnes et quelles cellules ne sont pas, vous pouvez potentiellement construire une solution de stockage à froid très haute performance”, a-t-il dit à très faible coût “, a-t-il dit.
Prendre une flexibilité du centre de données à l’extrême
Frankovsky veut des conceptions si flexibles que les composants individuels peuvent être échangés en réponse à l’évolution de la demande. Un effort le long de cette ligne est la nouvelle spécification “Group Hug” de Facebook pour les cartes mères, qui pourraient accueillir des processeurs de nombreux fournisseurs. AMD et Intel, ainsi que les fournisseurs de puces à bras appliqués Micro et Calxeda, se sont déjà engagés à soutenir ces planches avec de nouveaux produits SOC (System on Chip).
C’était l’un des nombreux articles qui sont sortis du Sommet Open Calcul du mois dernier à Santa Clara, en Californie. Au total, les annonces indiquent un avenir dans lequel les clients peuvent «mettre à niveau à travers plusieurs générations de processeurs sans avoir à remplacer les cartes mères ou le réseautage dans le rack», a noté Frankovsky dans un article de blog.
Calxeda a proposé une carte de serveur basée sur ARM qui peut glisser dans le système de stockage ouvert de Vault de Facebook, le nom de code “Knox.”” Il transforme le périphérique de stockage en serveur de stockage et élimine la nécessité d’un serveur séparé pour contrôler le disque dur “, a déclaré Frankovsky. (Facebook n’utilise pas de serveurs ARM aujourd’hui car il nécessite un support 64 bits, mais Frankovsky dit que “les choses deviennent intéressantes” dans la technologie des bras.)
Intel a également contribué des conceptions pour une prochaine technologie de photonique en silicium qui permettra des interconnexions de 100 Gbit / s, 10 fois plus rapides que les connexions Ethernet que Facebook utilise dans ses centres de données aujourd’hui. Avec la faible latence activée par ce type de vitesse, les clients peuvent être en mesure de séparer les CPU, DRAM et le stockage dans différentes parties du rack et d’ajouter ou de soustraire des composants au lieu de serveurs entiers en cas de besoin, a déclaré Frankovsky. Dans ce scénario, plusieurs hôtes pourraient partager un système flash, améliorant l’efficacité.
Malgré tous ces designs personnalisés venant de l’extérieur du monde OEM, HP et Dell ne sont pas complètement laissés pour compte. Ils se sont adaptés pour essayer de capturer certains clients qui souhaitent la flexibilité des conceptions de calcul ouvertes. Un dirigeant de Dell a livré l’un des keynotes lors de l’Open Compute Summit de cette année, et HP et Dell ont annoncé l’année dernière “des conceptions de serveurs et de stockage” Clean-Sheet qui sont compatibles avec la spécification “Open Rack” du projet Open Calcul.
En plus d’être bon pour Facebook, Frankovsky espère que Open Compute bénéficiera aux clients du serveur en général. Fidelity et Goldman Sachs font partie de ceux qui utilisent des conceptions personnalisées réglées sur leurs charges de travail à la suite d’un calcul ouvert. Les petits clients pourraient également en bénéficier, même s’ils louent un espace dans un centre de données où ils ne peuvent pas modifier la conception du serveur ou du rack, a-t-il dit. Ils pouvaient “prendre des blocs de construction [de calcul ouvert] et les restructurer dans des conceptions physiques qui s’inscrivent dans leurs créneaux de serveur”, a déclaré Frankovsky.
“L’industrie change et change dans le bon sens, en faveur des consommateurs, en raison d’un calcul ouvert”, a-t-il déclaré.