


Facebook utilise-t-il MongoDB?
Facebook -134MG1Q -Webkit-Align-self: Centre-MS-Flex-Item-Align: Centre; ALIGN-SEG: Centre; rembourrage: 0 10px; Visibilité: cachée;. CSS-6VRLZM Border-Radius: 0! important; Affichage: initial! important; marge: initiale! important;. CSS-1L4S55V margin-top-175px; Position: absolue; Padding-Bottom: 2px;
Voir configurer une application Facebook pour des informations sur la configuration de votre application Facebook et la recherche de l’application Secret.
Facebook utilise-t-il MongoDB?
О этой срранице
Ыы зарегистрtures. С помощюю ээой страницы ыы сжжем оределить, что заES’t. П’t?
Эта странdent к Te. Странdent. До ээого момента для исоллash.
Источником заves просов может слжжж Вve ыыы заES’t. Еслèe Вы ис démar. Обратитесь к своему ситемному адмииииии. Подробнее.
Проверка по слову может также появляться, ели Вы Вводите сложные заы, оычно рссзevretic емами, или же Вводите заES’t.
Authentification Facebook
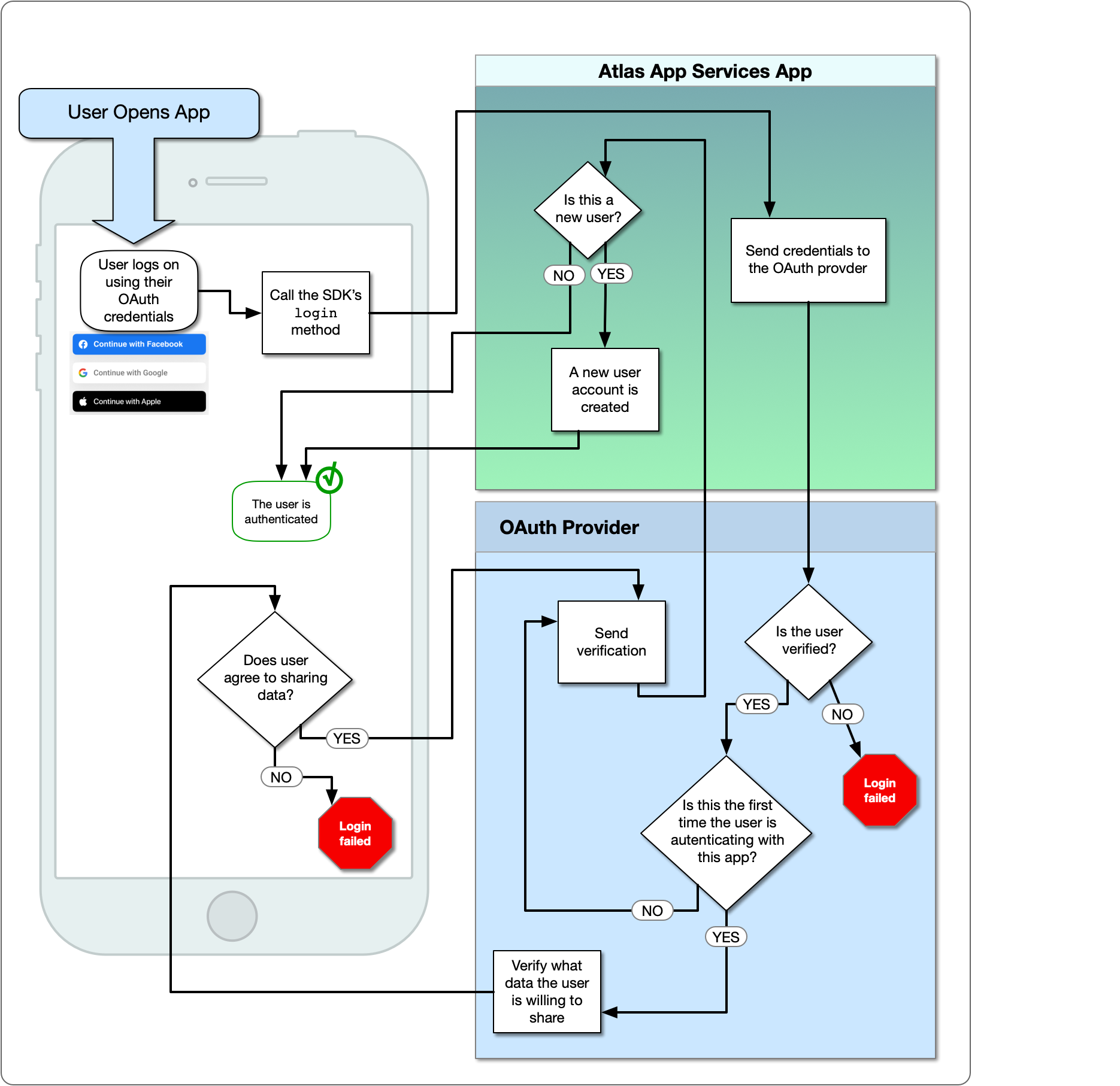
Le fournisseur d’authentification Facebook permet aux utilisateurs de se connecter avec leur compte Facebook existant via une application Facebook compagnon. Lorsqu’un utilisateur se connecte, Facebook fournit des services d’application Atlas avec un OAuth 2.0 Jeton d’accès pour l’utilisateur. Les services d’application utilisent le jeton pour identifier l’utilisateur et accéder aux données approuvées de l’API Facebook en leur nom. Pour plus d’informations sur la connexion Facebook, consultez Facebook Connexion pour les applications.
Le diagramme suivant montre le flux logique OAuth:
Configuration
Le fournisseur d’authentification Facebook a les options de configuration suivantes:
Description
configurer.identité du client
Requis. L’ID de l’application de l’application Facebook.
Voir configurer une application Facebook pour des informations sur la configuration de votre application Facebook et la recherche de l’ID d’application.
Secret client
secret_config.CLIENTSecret
Requis. Le nom d’un secret qui stocke le secret de l’application de l’application Facebook.
Voir configurer une application Facebook pour des informations sur la configuration de votre application Facebook et la recherche de l’application Secret.
Champs de métadonnées
métadonnées
Facultatif. Une liste de champs décrivant l’utilisateur authentifié que votre application demandera à l’API du graphique Facebook.
Tous les champs de métadonnées sont omis par défaut et peuvent être requis sur le terrain par champ. Les utilisateurs doivent accorder explicitement l’autorisation de votre application pour accéder à chaque champ requis. Si un champ de métadonnées est requis et existe pour un utilisateur particulier, il sera inclus dans son objet utilisateur.
Pour exiger un champ de métadonnées à partir d’un fichier de configuration d’importation / exportation, ajoutez une entrée pour le champ au tableau Metadata_fields. Chaque entrée doit être un document du formulaire suivant:
"" , ""
Base de données d’utilisateurs de Facebook – est-ce SQL ou NOSQL?
Vous êtes déjà demandé quelle base de données Facebook (FB) utilise pour stocker les profils de ses 2.3B + utilisateurs? Est-ce SQL ou NOSQL? Comment l’architecture de la base de données FB a-t-elle évolué au cours des 15 dernières années? En tant qu’ingénieur dans l’équipe d’infrastructure de base de données FB de 2007 à 2013, j’ai eu un siège au premier rang pour assister à cette évolution. Il y a des leçons inestimables à apprendre en comprenant mieux l’évolution de la base de données sur le plus grand réseau social du monde, même si la plupart d’entre nous ne seront pas confrontés exactement aux mêmes défis dans un avenir proche. En effet, les principes fondamentaux qui sous-tendent l’architecture à l’échelle Internet de FB, à l’échelle mondiale, s’appliquent aujourd’hui à de nombreuses applications d’entreprise d’entreprise telles que le SaaS multi-locataire, le catalogue / la paiement des produits de vente au détail, les réservations de voyage et les classements de jeu.
Architecture initiale
Comme tout utilisateur de FB peut facilement le comprendre, son profil n’est pas simplement une liste d’attributs tels que le nom, l’e-mail, les intérêts, etc. C’est en fait un graphique social riche qui stocke toutes les relations, les groupes, les registres, les chèques, les goûts, les partages et plus encore. Compte tenu de la flexibilité de modélisation des données de SQL et de l’omniprésence de MySQL lorsque FB a commencé, ce graphique social a été initialement construit en tant qu’application PHP propulsée par MySQL en tant que base de données persistante et Memcache comme un cache “lookaside”.
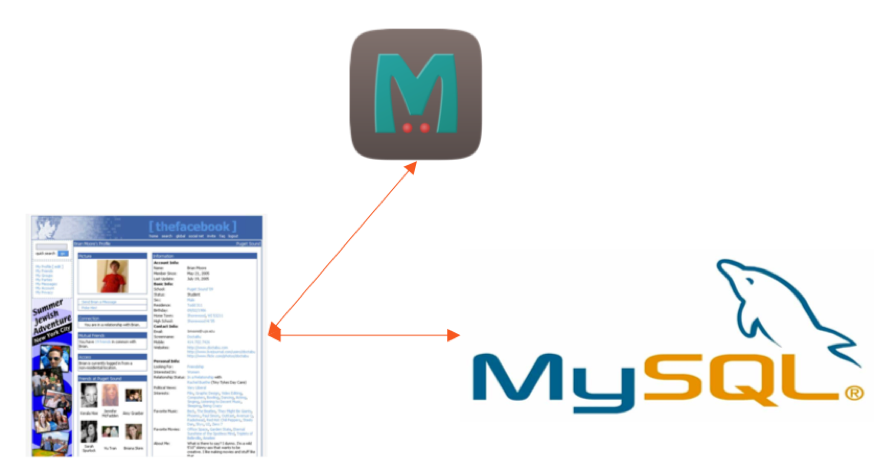
Architecture de base de données originale de Facebook
Dans le modèle de mise en cache Lookaside, l’application demande d’abord les données du cache au lieu de la base de données. Si les données ne sont pas mises en cache, l’application obtient les données de la base de données du support et la met dans le cache pour les lectures ultérieures. Notez que l’application PHP accédait directement à MySQL et à Memcache sans aucune couche d’abstraction de données intermédiaire.
Douleurs de croissance
Perte de l’agilité du développeur
Les ingénieurs ont dû travailler avec deux magasins de données avec deux modèles de données très différents: une grande collection de MySQL
Facebook -134MG1Q -Webkit-Align-self: Centre-MS-Flex-Item-Align: Centre; ALIGN-SEG: Centre; rembourrage: 0 10px; Visibilité: cachée;. CSS-6VRLZM Border-Radius: 0! important; Affichage: initial! important; marge: initiale! important;. CSS-1L4S55V margin-top-175px; Position: absolue; Padding-Bottom: 2px;
Voir configurer une application Facebook pour des informations sur la configuration de votre application Facebook et la recherche de l’application Secret .
Facebook utilise-t-il MongoDB?
О этой срранице
Ыы зарегистрtures. С помощюю ээой страницы ыы сжжем оределить, что заES’t. П’t?
Эта странdent к Te. Странdent. До ээого момента для исоллash.
Источником заves просов может слжжж Вve ыыы заES’t. Еслèe Вы ис démar. Обратитесь к своему ситемному адмииииии. Подробнее.
Проверка по слову может также появляться, ели Вы Вводите сложные заы, оычно рссзevretic емами, или же Вводите заES’t.
Authentification Facebook
Le fournisseur d’authentification Facebook permet aux utilisateurs de se connecter avec leur compte Facebook existant via une application Facebook compagnon. Lorsqu’un utilisateur se connecte, Facebook fournit des services d’application Atlas avec un OAuth 2.0 Jeton d’accès
pour l’utilisateur. Les services d’application utilisent le jeton pour identifier l’utilisateur et accéder aux données approuvées de l’API Facebook en leur nom. Pour plus d’informations sur la connexion Facebook, consultez Facebook Connexion pour les applications
Le diagramme suivant montre le flux logique OAuth:
Configuration
Le fournisseur d’authentification Facebook a les options de configuration suivantes:
Description
configurer.identité du client
Requis. L’ID de l’application de l’application Facebook.
Voir configurer une application Facebook pour des informations sur la configuration de votre application Facebook et la recherche de l’ID d’application .
Secret client
secret_config.CLIENTSecret
Requis. Le nom d’un secret qui stocke le secret de l’application de l’application Facebook.
Voir configurer une application Facebook pour des informations sur la configuration de votre application Facebook et la recherche de l’application Secret .
Champs de métadonnées
métadonnées
Facultatif. Une liste de champs décrivant l’utilisateur authentifié que votre application demandera à l’API du graphique Facebook .
Tous les champs de métadonnées sont omis par défaut et peuvent être requis sur le terrain par champ. Les utilisateurs doivent accorder explicitement l’autorisation de votre application pour accéder à chaque champ requis. Si un champ de métadonnées est requis et existe pour un utilisateur particulier, il sera inclus dans son objet utilisateur.
Pour exiger un champ de métadonnées à partir d’un fichier de configuration d’importation / exportation, ajoutez une entrée pour le champ au tableau Metadata_fields. Chaque entrée doit être un document du formulaire suivant:
< nom: "", requis: "" >
Facebook’S Base de données des utilisateurs – Est-ce SQL ou NOSQL?
Vous êtes déjà demandé quelle base de données Facebook (FB) utilise pour stocker les profils de ses 2.3B + utilisateurs? Est-ce SQL ou NOSQL? Comment l’architecture de la base de données FB a-t-elle évolué au cours des 15 dernières années? En tant qu’ingénieur dans l’équipe d’infrastructure de base de données FB de 2007 à 2013, j’ai eu un siège au premier rang pour assister à cette évolution. Il y a des leçons inestimables à apprendre en comprenant mieux l’évolution de la base de données au monde’le plus grand réseau social, même si la plupart d’entre nous ont gagné’Je suis confronté exactement aux mêmes défis dans un avenir proche. C’est parce que les principes fondamentaux qui sous-tendent FB’L’architecture à l’échelle Internet, à l’échelle mondiale, s’applique aujourd’hui à de nombreuses applications d’entreprise d’entreprise telles que le SaaS multi-locataire, le catalogue / la caisse des produits de vente au détail, les réservations de voyage et les classements de jeu.
Architecture initiale
Comme tout utilisateur de FB peut facilement le comprendre, son profil n’est pas simplement une liste d’attributs tels que le nom, l’e-mail, les intérêts, etc. C’est en fait un graphique social riche qui stocke toutes les relations, les groupes, les registres, les chèques, les goûts, les partages et plus encore. Compte tenu de la flexibilité de modélisation des données de SQL et de l’ubiquité de MySQL lorsque FB a commencé, ce graphique social a été initialement construit en tant qu’application PHP propulsée par MySQL en tant que base de données persistante et Memcache en tant que “regarder de côté” cache.
Facebook’S Architecture de base de données originale
Dans le modèle de mise en cache Lookaside, l’application demande d’abord les données du cache au lieu de la base de données. Si les données ne sont pas mises en cache, l’application obtient les données de la base de données du support et la met dans le cache pour les lectures ultérieures. Notez que l’application PHP accédait directement à MySQL et à Memcache sans aucune couche d’abstraction de données intermédiaire.
Douleurs de croissance
Fb’Le succès météorique de 2005 a mis une énorme contrainte sur l’architecture de base de données simpliste mise en évidence dans la section précédente. Voici quelques-uns des douleurs croissantes que les ingénieurs FB ont dû résoudre dans un court laps de temps.
Perte de l’agilité du développeur
Les ingénieurs ont dû travailler avec deux magasins de données avec deux modèles de données très différents: une grande collection de paires de maître-esclave MySQL pour le stockage de données de manière persistante dans des tables relationnelles, et une collection tout aussi grande de serveurs Memcache pour stocker et servir des paires de valeurs clés plates dérivées (certaines indirectement) à partir des résultats des requêtes SQL. Travailler avec le niveau de base de données a désormais obligé d’abord à acquérir une connaissance complexe de la façon dont les deux magasins fonctionnaient en conjonction les uns avec les autres. Le résultat net a été la perte de l’agilité du développeur.
Sharding de base de données au niveau de l’application
L’incapacité de MySQL à évoluer les demandes d’écriture au-delà d’un nœud est devenue un problème de tueur à mesure que les volumes de données ont augmenté à pas de géant. Mysql’S Architecture monolithique a essentiellement forcé le rupture au niveau de l’application très tôt. Cela signifiait que l’application a maintenant suivi quelle instance mysql est responsable du stockage de l’utilisateur’profil s. Le développement et la complexité opérationnelle se développent de façon exponentielle lorsque le nombre de telles instances passe de 1 à 100 ans et explosent par la suite en 1000. Notez que l’adhésion à une telle architecture signifiait que l’application n’utilise plus la base de données pour effectuer des jointures et transactions croisées, abandonnant ainsi la pleine puissance de SQL (en tant que langage de requête flexible) afin de mettre à l’échelle horizontalement.
Multi-datacenter, réplication géo-redondante
Gestion des échecs de centre de données est également devenu une préoccupation critique, ce qui signifiait stocker les esclaves MySQL (et les instances Memcache correspondantes) dans plusieurs centres de données géo-redondants. La perfectionnement et l’opérationnaliser les cafes n’ont pas été une mince affaire en soi, mais étant donné la réplication asynchrone maître-esclave, des données récemment engagées seraient encore manquantes chaque fois qu’un tel basculement était entrepris.
Perte de cohérence entre Cache et DB
Le Memcache devant un esclave MySQL de la région télécommandée ne peut pas immédiatement servir fortement (aka read-après-écriture) des lectures cohérentes en raison de la réplication asynchrone entre le maître et l’esclave. Et, les lectures périmées qui en résultent dans la région éloignée peuvent facilement conduire à des utilisateurs confus. E.g. Une demande d’ami peut apparaître comme accepté à un ami tout en se présentant comme toujours en attente de l’autre.
Entrez Tao, une API graphique NoSQL sur SQL Sharded
Début 2009, FB a commencé à construire Tao, une API graphique NOSQL spécifique au FB conçu pour fonctionner sur MySQL Sharded. L’objectif était de résoudre les problèmes mis en évidence dans la section précédente. Tao représente “Les associations et objets”. Même si la conception de Tao a été publiée pour la première fois en tant que document en 2013, la mise en œuvre de Tao n’a jamais été ouverte étant donné la nature propriétaire du graphique social FB.
Tao a représenté les éléments de données comme des nœuds (objets) et des relations entre eux comme bords (associations). Les développeurs d’applications FB ont adoré l’API car ils pouvaient désormais gérer facilement les mises à jour et les requêtes de base de données nécessaires à leur logique d’application sans aucune connaissance directe de MySQL ou même Memcache.
Architecture
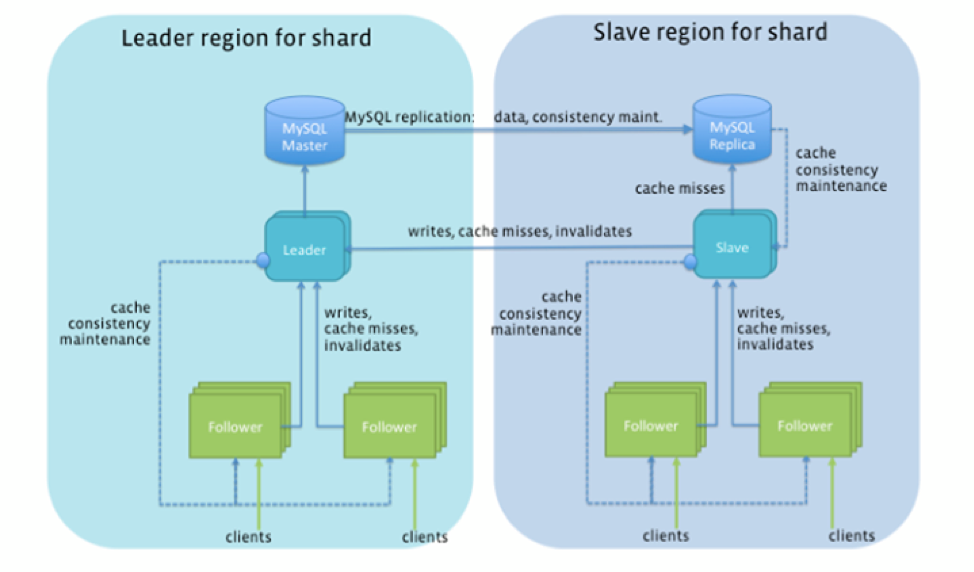
Comme indiqué dans la figure ci-dessous, Tao a essentiellement converti FB’s des milliers de plusieurs paires de maître-esclave MySQL à partage manuelle à un cluster de base de données géo-distribué hautement échecable. Tous les objets et associations dans le même éclat sont stockés de manière persistante dans la même instance MySQL et sont mises en cache sur le même ensemble de serveurs dans chaque cluster de mise en cache. Le placement d’objets et d’associations individuels peut être dirigé vers des fragments spécifiques au moment de la création en cas de besoin. Le contrôle du degré de collocation des données s’est avéré être une technique d’optimisation importante pour fournir un accès aux données à faible latence.
Les modèles d’accès basés sur SQL tels que les transactions et les jointures d’acide cross-shard ont été refusés dans le TAO comme moyen de préserver de telles garanties de latence faibles. Cependant, il a soutenu les écritures non atomiques à deux tirs dans le contexte d’une mise à jour d’association (dont les deux objets peuvent être en deux fragments différents). En cas d’échecs après une mise à jour du fragment, mais avant la deuxième mise à jour du fragment, un travail de réparation asynchrone nettoyerait le “suspendu” Association à un moment ultérieur.
Les éclats peuvent être migrés ou clonés vers différents serveurs dans le même cluster pour équilibrer la charge et lisser les pointes de chargement. Les pointes de charge étaient courantes et se produisent lorsqu’une poignée d’objets ou d’associations deviennent extrêmement populaires à mesure qu’ils apparaissent dans les flux d’actualités de dizaines de millions d’utilisateurs en même temps.
Y a-t-il une solution d’entreprise à usage général?
FB n’avait pas d’autre choix que d’étendre massivement la couche de base de données MySQL responsable de son utilisateur’s graphique social. Ni MySQL ni les autres bases de données SQL disponibles à ce moment-là ne pouvaient résoudre ce problème par eux-mêmes. Ainsi, FB a utilisé son ingénierie significative pourrait essentiellement créer une couche de requête de base de données personnalisée qui a résumé les bases de données MySQL fragées sous-jacentes. Ce faisant, il a forcé ses développeurs à abandonner complètement SQL en tant qu’API de requête flexible et à adopter Tao’S API Nosql personnalisé.
La plupart d’entre nous dans le monde de l’entreprise n’ont pas de problèmes à l’échelle de Facebook, mais veulent néanmoins évoluer les bases de données SQL à la demande. Nous aimons SQL pour sa flexibilité et son ubiquité, ce qui signifie que nous voulons évoluer sans abandonner SQL. Y a-t-il une solution à des fins générales pour les entreprises comme nous? La réponse est oui!
Bonjour SQL distribué!
Les bases de données SQL monolithiques essaient depuis plus de 10 ans pour se répartir afin de résoudre le problème de mise à l’échelle horizontal. Comme “Montée des bases de données SQL distribuées à l’échelle mondiale” Faits saillants, la première vague de telles bases de données s’appelait NewsQL et comprenait des bases de données telles que Clustrix, Nuodb, Citus et Vitess. Ceux-ci ont connu un succès limité à déplacer les bases de données SQL fraginées manuellement. La raison en est que la nouvelle valeur créée n’est pas suffisante pour simplifier radicalement l’expérience du développeur et des opérations. Mandat de Clustrix et Nuodb Mandat spécialisé, très fiable et à faible latence, infrastructure – l’infrastructure indigène du cloud moderne semble exactement le contraire. Citus et Viess simplifient l’expérience des opérations dans une certaine mesure en partageant automatiquement la base de données, mais en handicapant ensuite le développeur en ne lui donnant pas une seule base de données SQL distribuée logique.
Nous sommes maintenant dans la deuxième génération de bases de données SQL distribuées où une évolutivité massive et une distribution mondiale de données sont intégrés dans la couche de base de données, contre 10 ans, lorsque Facebook a dû intégrer ces fonctionnalités dans la couche d’application.
Inspiré par Google Spanner
Pendant que FB construisait Tao, Google construisait Spanner, une base de données complètement nouvelle mondiale pour résoudre des défis très similaires. Chapelet’Le modèle de données était moins un graphique social mais plus une charge de travail OLTP traditionnelle à accès aléatoire qui gère Google’S des utilisateurs, des organisations clients, des crédits AdWords, des préférences Gmail et plus encore. Spanner a été présenté pour la première fois dans le monde sous la forme d’un document de conception en 2012. Il a commencé en 2007 en tant que magasin de valeurs de clé transactionnel, mais a ensuite évolué en une base de données SQL. Le passage à SQL à mesure que la seule langue client s’est accélérée à mesure que Google Engineers a réalisé que SQL a toutes les bonnes constructions pour le développement d’Agile Applications, en particulier dans l’ère native du cloud où l’infrastructure est beaucoup plus dynamique et sujette à l’échec que les centres de données privés très fiables du passé. Aujourd’hui, plusieurs bases de données modernes (y compris Yugabytedb) ont donné vie à la conception Google Spanner en open source.
Gérer facilement le volume de données à l’échelle d’Internet
La rupture est complètement automatique dans l’architecture Spanner. De plus, les éclats deviennent auto équilibrés sur tous les nœuds disponibles lorsque de nouveaux nœuds sont ajoutés ou que les nœuds existants sont supprimés. Les microservices nécessitant une évolutivité d’écriture massive peuvent désormais s’appuyer sur la base de données directement au lieu d’ajouter de nouvelles couches d’infrastructure similaires à celles que nous avons vues dans l’architecture FB. Pas besoin de cache en mémoire (qui décharge les demandes de lecture de la base de données le libérant ainsi pour servir les demandes d’écriture) et pas également besoin d’une couche d’application de type Tao qui fait la gestion des fragments.
Résilience extrême contre les échecs
Une différence clé entre Spanner et les bases de données Legacy NewsQL que nous avons examinées dans la section précédente est Spanner’S Utilisation du consensus distribué par shard pour garantir que chaque fragment (et pas simplement chaque instance) reste fortement disponible en présence d’échecs. Semblable à Tao, les échecs d’infrastructure affectent toujours seulement un sous-ensemble de données (seuls les éclats dont les dirigeants se séparent) et jamais le cluster entier. Et, étant donné la capacité des répliques de fragment restantes à élu automatiquement un nouveau leader en secondes, le cluster présente des caractéristiques d’auto-guérison lorsqu’elles sont soumises à des échecs. L’application reste transparente à ces changements de configuration de cluster et continue de fonctionner normalement sans pannes ni ralentissements.
Réplication sans couture à travers le monde
L’avantage d’une architecture de base de données à l’échelle mondiale est que les microservices nécessitant des données absolument correctes dans les scénarios d’écriture multi-zones et multi-régions peuvent enfin s’appuyer directement sur la base de données. Les conflits et la perte de données observés dans les déploiements multi-maîtres typiques du passé ne se produisent pas. Des fonctionnalités telles que le géopartiat au niveau de la table et au niveau des lignes garantissent que les données pertinentes pour la région locale restent levées dans la même région. Cela garantit que le chemin de lecture fortement cohérent n’encasse jamais.
Pleine puissance des transactions SQL et acide distribué
Contrairement aux bases de données Legacy NewsQL, SQL et les transactions acides dans leur formulaire complète peuvent être prises en charge dans l’architecture Spanner. Les opérations à clé unique sont par défaut fortement cohérentes et transactionnelles (le terme technique est linéarissable). Les transactions à feu unique par définition sont conduites à un seul fragment et peuvent donc être engagées sans l’utilisation d’un gestionnaire de transactions distribué. Les transactions à l’acide multi-décalage (alias distribuées) impliquent un engagement biphasé utilisant un gestionnaire de transactions distribué qui suit également les biais d’horloge à travers les nœuds. Les jointures multiples sont gérées de manière similaire en interrogeant des données sur les nœuds. La clé ici est que toutes les opérations d’accès aux données sont transparentes au développeur qui utilise simplement des constructions SQL régulières pour interagir avec la base de données.
Résumé
Les histoires de mise à l’échelle de l’infrastructure de données dans l’un des géants de la technologie, y compris FB et Google, font un excellent apprentissage en ingénierie. Chez FB, nous avons pris la voie de la construction de Tao qui nous a permis de préserver notre investissement existant dans MySQL SHARDED. Nos ingénieurs d’application ont perdu la possibilité d’utiliser SQL mais ont gagné un tas d’autres avantages. Les ingénieurs de Google ont été confrontés à des défis similaires, mais ils ont choisi un chemin différent en créant Spanner, une base de données SQL entièrement nouvelle qui peut à l’échelle horizontale, de manière transparente et de tolérer facilement les défaillances de l’infrastructure. FB et Google sont tous deux des histoires de réussite incroyables, nous ne pouvons donc pas dire qu’un chemin était meilleur que l’autre. Cependant, lorsque nous élargissons l’horizon aux architectures d’entreprise à usage général, Spanner a devant Tao en raison de toutes les raisons mises en évidence dans ce post. En construisant Yugabytedb’S Couche de stockage sur l’architecture Spanner, nous pensons que nous pouvons apporter l’agilité du développeur des géants de la technologie aux entreprises d’aujourd’hui.
Mis à jour mars 2019.
Quoi’S suivant?
- Comparez Yugabytedb en profondeur aux bases de données comme CockroachDB, Google Cloud Spanner et MongoDB.
- Commencez avec Yugabytedb sur MacOS, Linux, Docker et Kubernetes.
- Contactez-nous pour en savoir plus sur les licences, les prix ou pour planifier un aperçu technique.
Connecter
Facebook Leads
à mongodb
Après avoir fait l’intégration avec le MongoDB, les options suivantes seront disponibles: vous avez maintenant la possibilité d’automatiser le transfert de prospects de Facebook à MongoDB. En faisant cela, vous pouvez automatiser vos processus commerciaux et gagner du temps.
Votez pour créer une intégration avec MongoDB
Sync Facebook mène à MongoDB
Veulent transférer automatiquement les prospects de Facebook? Pour le moment, nous n’avons pas d’intégration prête à l’emploi avec le MongoDB, mais nos développeurs travaillent sur cette intégration.
Après avoir terminé l’intégration, vous n’aurez pas besoin de télécharger manuellement les prospects de Facebook à MongoDB. Notre système vérifiera les nouvelles pistes 24 heures sur 24, 7 jours par semaine. Sans jours de congé et vacances.
À venir

Intégrer dans 1 clic
Intégrer Facebook dirige les annonces avec MongoDB
Comment ça marchera?
- Savemyleads surveille constamment des informations sur les nouvelles prospects sur Facebook
- Dès qu’une nouvelle piste est apparue, notre service prendra automatiquement toutes les données sur le plomb et la transférera au MongoDB.
De quoi avez-vous besoin pour commencer?
- Connectez le compte d’annonces Facebook Leads
- Connectez le compte MongoDB
- Activer le transfert de prospects de Facebook à MongoDB
Votez pour l’intégration avec le MongoDB. Plus il y a de votes, plus vite nous ferons l’intégration. Le formulaire de vote est en haut de la page.
Q&A About Connect & Sync Facebook Leads avec MongoDB
Comment intégrer Facebook Leads et MongoDB?
Après avoir terminé l’intégration:
- Vous devez vous inscrire dans Savemyleeads
- Choisissez les données à transférer de Facebook à MongoDB
- Activer la mise à jour automatique
- Les données seront désormais transférées de Facebook à MongoDB
Combien de temps faut-il pour intégrer Facebook mène à MongoDB?
Selon le système avec lequel vous intégrez, le temps de configuration peut varier et varier de 5 à 30 minutes. En moyenne, la configuration prend 10 à 15 minutes.
Combien cela coûte-t-il pour intégrer Facebook à MongoDB?
Nous proposons des plans pour différents volumes de tâches. Aller au “Prix” Section et choisissez l’ensemble de fonctionnalités qui convient le mieux à vos besoins. De plus, vous avez la possibilité de tester le service gratuitement pendant 14 jours.
Combien de services prêts à l’intégration et à envoyer des prospects de FB?
Nous aurons plus de 40 intégrations prêtes.
Qu’est-ce que MongoDB?
MongoDB est un système de gestion de base de données. Il ne nécessite pas de description du schéma de la table et est un exemple classique d’un système NoSQL. La plate-forme est écrite en C ++. Utilisé dans la programmation, prend en charge les demandes ad hoc. Il met en œuvre une recherche parmi les expressions régulières, et vous pouvez également personnaliser les requêtes pour retourner des ensembles de résultats aléatoires. Il prend en charge les index et sait comment travailler avec des ensembles de répliques, c’est-à-dire que vous pouvez enregistrer 2 copies ou plus de données sur différents nœuds. Chaque copie peut agir comme une réplique primaire ou secondaire. Les écritures de lecture sont effectuées par la copie maîtresse. Les auxiliaires gardent les données à jour. Si la copie principale ne fonctionne pas, le système choisit la copie que la copie devient le maître.
La mise à l’échelle du système est horizontale en fonction des règles de segmentation des bases de données avec distribution en parties sur différents nœuds du cluster. La clé d’émulation est déterminée par l’administrateur, ainsi que le critère selon lequel les données seront réparties dans les coins. La charge est équilibrée car les demandes peuvent être acceptées par tous les nœuds du cluster. MongoDB peut être utilisé pour stocker des fichiers. Le système divise les fichiers en pièces et stocke chacun en tant que document indépendant.
Depuis 2018, la version 4 a ajouté une prise en charge des transactions qui répondent aux réglementations acides. Les conducteurs officiels sont fournis pour tous les principaux langages de programmation. De plus, un grand nombre de chauffeurs non officiels ont été développés, qui sont publiés par des développeurs tiers. Ils sont soutenus par la communauté et peuvent être utilisés pour d’autres langues et cadres. L’interface de la base de données a été fournie par l’emballage MongoDB, mais toutes les versions de plus que la 3e reçue MongoDB Compass à la place.
Si vous souhaitez connecter, intégrer ou synchroniser les annonces Facebook ADS avec MongoDB – Chantez maintenant et en 5 minutes, de nouveaux leads seront automatiquement envoyés à MongoDB. Essayez un essai gratuit!