


Google a-t-il une fonctionnalité de transcription
Transcrire dans Google Docs: transcription audio à texte
Utilisez l’extrait de code ci-dessous pour convertir un fichier vidéo en un fichier audio à l’aide de ffmpeg .
Transcrire l’audio à partir d’un fichier vidéo à l’aide de la parole en texte
Ce tutoriel montre comment transcrire la piste audio à partir d’un fichier vidéo à l’aide de la parole à texte.
Les fichiers audio peuvent provenir de nombreuses sources différentes. Les données audio peuvent provenir d’un téléphone (comme la messagerie vocale) ou de la bande sonore incluse dans un fichier vidéo.
La parole à texte peut utiliser l’un des nombreux apprentissage automatique des modèles Pour transcrire votre fichier audio, pour correspondre au mieux à la source d’origine de l’audio. Vous pouvez obtenir de meilleurs résultats de votre transcription vocale en spécifiant la source de l’audio d’origine. Cela permet à la parole de texte de traiter vos fichiers audio à l’aide d’un modèle d’apprentissage automatique formé pour des données similaires à votre fichier audio.
Objectifs
- Envoyez une demande de transcription audio pour un fichier vidéo dans le discours à texte.
Frais
- Discours à texte
Pour générer une estimation des coûts en fonction de votre utilisation projetée, utilisez la calculatrice de tarification. Les nouveaux utilisateurs de Google Cloud pourraient être éligibles pour un essai gratuit.
Avant que tu commences
Ce tutoriel a plusieurs conditions préalables:
- Vous avez mis en place un projet de discours sur le texte dans la console Google Cloud.
- Vous avez configuré votre environnement en utilisant les informations d’identification par défaut de l’application dans la console Google Cloud.
- Vous avez configuré l’environnement de développement pour votre langage de programmation choisi.
- Vous avez installé la bibliothèque client de Google Cloud pour votre langage de programmation choisi.
Préparer les données audio
Avant de pouvoir transcrire l’audio à partir d’une vidéo, vous devez extraire les données du fichier vidéo. Après avoir extrait les données audio, vous devez les stocker dans un seau de stockage cloud ou le convertir en codage de base64.
Note: Si vous utilisez une bibliothèque client pour la transcription, vous n’avez pas besoin de stocker ou de convertir les données audio. Il vous suffit d’extraire les données audio du fichier vidéo avant d’envoyer une demande de transcription.
Extraire les données audio
Vous pouvez utiliser n’importe quel outil de conversion de fichiers qui gère les fichiers audio et vidéo, tels que FFMPEG.
Utilisez l’extrait de code ci-dessous pour convertir un fichier vidéo en un fichier audio à l’aide de ffmpeg .
FFMPEG -i Video-Input-File Audio-Output-File
Stocker ou convertir les données audio
Vous pouvez transcrire un fichier audio stocké sur votre machine locale ou dans un seau de stockage cloud.
Utilisez la commande suivante pour télécharger votre fichier audio sur un seau de stockage cloud existant à l’aide de l’outil GSUtil.
Gsutil CP Audio-Output-File Storage-Bucket-Uri
Si vous utilisez un fichier local et prévoyez d’envoyer une demande à l’aide de l’outil Curl à partir de la ligne de commande, vous devez d’abord convertir le fichier audio en données codées Base64.
Utilisez la commande suivante pour convertir un fichier audio en fichier texte.
base64 audio-sortie-file -w 0> audio-data-text
Envoyer une demande de transcription
Utilisez le code suivant pour envoyer une demande de transcription à la parole à texte.
Demande de fichier local
Protocole
Reportez-vous au discours: reconnaissez le point de terminaison de l’API pour plus de détails.
Pour effectuer une reconnaissance de la parole synchrone, faites une demande de poste et fournissez le corps de demande approprié. Ce qui suit montre un exemple de demande de poste utilisant Curl . L’exemple utilise le jeton d’accès pour un compte de service configuré pour le projet à l’aide de Google Cloud Google Cloud CLI. Pour des instructions sur l’installation de la CLI Gcloud, la mise en place d’un projet avec un compte de service et l’obtention d’un jeton d’accès, consultez le QuickStart.
curl -s -h "contenu-type: application / json" \ -h "Autorisation: Bearer $ (gcloud autorité application-default print-access-token)" \ https: // discours.googleapis.com / v1 / discours: reconnaître \ --data ' < "config": < "encoding": "LINEAR16", "sampleRateHertz": 16000, "languageCode": "en-US", "modèle": "vidéo" >, "Audio": < "uri": "gs://cloud-samples-tests/speech/Google_Gnome.wav" >> '
Voir la documentation de référence RecognitionConfig pour plus d’informations sur la configuration du corps de la demande.
Si la demande réussit, le serveur renvoie un code d’état HTTP 200 OK et la réponse au format JSON:
Aller
Pour s’authentifier dans le texte parole, configurer les informations d’identification par défaut de l’application. Pour plus d’informations, voir Configurer l’authentification pour un environnement de développement local.
Func ModelSelection (w io.Écrivain, String de chemin) Erreur {ctx: = contexte.Fond () client, err: = discours.Newclient (ctx) si err != nil {return fmt.Errorf ("newclient:% w", err)} différer le client.Close () // path = "../ testdata / google_gnome.Données Wav ", err: = ioutil.ReadFile (chemin) Si err != nil {return fmt.Errorf ("readfile:% w", err)} req: = & speechpb.Recontectionrequest {config: & speechpb.RecognitionConfig {Encoding: SpeechPB.RecognitionConfig_linear16, SamplerateHertz: 16000, LanguageCode: "En-US", modèle: "VIDEO",}, Audio: & SpeechPB.RecognitionAudio {Audiosource: & SpeechPB.RecognitionAudio_Content,},} resp, err: = Client.Reconnaître (ctx, req) si err != nil {return fmt.Errorf ("reconnaître:% w", err)} pour i, résultat: = plage resp.Résultats {FMT.Fprintf (w, "% s \ n", cordes.Répéter ("-", 20)) FMT.Fprintf (w, "résultat% d \ n", i + 1) pour j, alternative: = Résultat de la plage.Alternatives {FMT.Fprintf (w, "alternative% d:% s \ n", j + 1, alternative.Transcrit)}} return nil} Java
Pour s’authentifier dans le texte parole, configurer les informations d’identification par défaut de l’application. Pour plus d’informations, voir Set U
Transcrire dans Google Docs: transcription audio à texte
Utilisez l’extrait de code ci-dessous pour convertir un fichier vidéo en un fichier audio à l’aide de ffmpeg .
Transcrire l’audio à partir d’un fichier vidéo à l’aide de la parole en texte
Ce tutoriel montre comment transcrire la piste audio à partir d’un fichier vidéo à l’aide de la parole à texte.
Les fichiers audio peuvent provenir de nombreuses sources différentes. Les données audio peuvent provenir d’un téléphone (comme la messagerie vocale) ou de la bande sonore incluse dans un fichier vidéo.
La parole à texte peut utiliser l’un des nombreux apprentissage automatique des modèles Pour transcrire votre fichier audio, pour correspondre au mieux à la source d’origine de l’audio. Vous pouvez obtenir de meilleurs résultats de votre transcription vocale en spécifiant la source de l’audio d’origine. Cela permet à la parole de texte de traiter vos fichiers audio à l’aide d’un modèle d’apprentissage automatique formé pour des données similaires à votre fichier audio.
Objectifs
- Envoyez une demande de transcription audio pour un fichier vidéo dans le discours à texte.
Frais
- Discours à texte
Pour générer une estimation des coûts en fonction de votre utilisation projetée, utilisez la calculatrice de tarification. Les nouveaux utilisateurs de Google Cloud pourraient être éligibles pour un essai gratuit.
Avant que tu commences
Ce tutoriel a plusieurs conditions préalables:
- Vous avez mis en place un projet de discours sur le texte dans la console Google Cloud.
- Vous avez configuré votre environnement en utilisant les informations d’identification par défaut de l’application dans la console Google Cloud.
- Vous avez configuré l’environnement de développement pour votre langage de programmation choisi.
- Vous avez installé la bibliothèque client de Google Cloud pour votre langage de programmation choisi.
Préparer les données audio
Avant de pouvoir transcrire l’audio à partir d’une vidéo, vous devez extraire les données du fichier vidéo. Après avoir extrait les données audio, vous devez les stocker dans un seau de stockage cloud ou le convertir en codage de base64.
Note: Si vous utilisez une bibliothèque client pour la transcription, vous n’avez pas besoin de stocker ou de convertir les données audio. Il vous suffit d’extraire les données audio du fichier vidéo avant d’envoyer une demande de transcription.
Extraire les données audio
Vous pouvez utiliser n’importe quel outil de conversion de fichiers qui gère les fichiers audio et vidéo, tels que FFMPEG.
Utilisez l’extrait de code ci-dessous pour convertir un fichier vidéo en un fichier audio à l’aide de ffmpeg .
ffmpeg -i vidéo-fichier vidéo fichier audio-sortie
Stocker ou convertir les données audio
Vous pouvez transcrire un fichier audio stocké sur votre machine locale ou dans un seau de stockage cloud.
Utilisez la commande suivante pour télécharger votre fichier audio sur un seau de stockage cloud existant à l’aide de l’outil GSUtil.
gsutil cp fichier audio-sortie Storage-Bucket-Uri
Si vous utilisez un fichier local et prévoyez d’envoyer une demande à l’aide de l’outil Curl à partir de la ligne de commande, vous devez d’abord convertir le fichier audio en données codées Base64.
Utilisez la commande suivante pour convertir un fichier audio en fichier texte.
base64 fichier audio-sortie -W 0> texta audio-data
Envoyer une demande de transcription
Utilisez le code suivant pour envoyer une demande de transcription à la parole à texte.
Demande de fichier local
Protocole
Reportez-vous au discours: reconnaissez le point de terminaison de l’API pour plus de détails.
Pour effectuer une reconnaissance de la parole synchrone, faites une demande de poste et fournissez le corps de demande approprié. Ce qui suit montre un exemple de demande de poste utilisant Curl . L’exemple utilise le jeton d’accès pour un compte de service configuré pour le projet à l’aide de Google Cloud Google Cloud CLI. Pour des instructions sur l’installation de la CLI Gcloud, la mise en place d’un projet avec un compte de service et l’obtention d’un jeton d’accès, consultez le QuickStart.
curl -s -h "contenu-type: application / json" \ -h "Autorisation: Bearer $ (gcloud autorité application-default print-access-token)" \ https: // discours.googleapis.com / v1 / discours: reconnaître \ --data ' < "config": < "encoding": "LINEAR16", "sampleRateHertz": 16000, "languageCode": "en-US", "modèle": "vidéo" >, "Audio": < "uri": "gs://cloud-samples-tests/speech/Google_Gnome.wav" >> '
Voir la documentation de référence RecognitionConfig pour plus d’informations sur la configuration du corps de la demande.
Si la demande réussit, le serveur renvoie un code d’état HTTP 200 OK et la réponse au format JSON:
Aller
Pour s’authentifier dans le texte parole, configurer les informations d’identification par défaut de l’application. Pour plus d’informations, voir Configurer l’authentification pour un environnement de développement local.
Func ModelSelection (w io.Écrivain, chaîne de chemin) Erreur < ctx := context.Background() client, err := speech.NewClient(ctx) if err != nil < return fmt.Errorf("NewClient: %w", err) >différer.Close () // path = "../ testdata / google_gnome.Données Wav ", err: = ioutil.ReadFile (chemin) Si err != NIL < return fmt.Errorf("ReadFile: %w", err) >req: = & speechpb.Reconnaissance< Config: &speechpb.RecognitionConfig< Encoding: speechpb.RecognitionConfig_LINEAR16, SampleRateHertz: 16000, LanguageCode: "en-US", Model: "video", >, Audio: & SpeechPB.Reconnaissance audio< AudioSource: &speechpb.RecognitionAudio_Content, >, > resp, err: = client.Reconnaître (ctx, req) si err != NIL < return fmt.Errorf("Recognize: %w", err) >pour i, résultat: = range respol.Résultats < fmt.Fprintf(w, "%s\n", strings.Repeat("-", 20)) fmt.Fprintf(w, "Result %d\n", i+1) for j, alternative := range result.Alternatives < fmt.Fprintf(w, "Alternative %d: %s\n", j+1, alternative.Transcript) >> retour nil> Java
Pour s’authentifier dans le texte parole, configurer les informations d’identification par défaut de l’application. Pour plus d’informations, voir Configurer l’authentification pour un environnement de développement local.
/ ** * Effectue la transcription du fichier audio donné de manière synchrone avec le modèle sélectionné. * * @param nom de fichier Le chemin d'accès à un fichier audio à transcrire * / public static void transcricceModeLelection (string filename) lève une exception < Path path = Paths.get(fileName); byte[] content = Files.readAllBytes(path); try (SpeechClient speech = SpeechClient.create()) < // Configure request with video media type RecognitionConfig recConfig = RecognitionConfig.newBuilder() // encoding may either be omitted or must match the value in the file header .setEncoding(AudioEncoding.LINEAR16) .setLanguageCode("en-US") // sample rate hertz may be either be omitted or must match the value in the file // header .setSampleRateHertz(16000) .setModel("video") .build(); RecognitionAudio recognitionAudio = RecognitionAudio.newBuilder().setContent(ByteString.copyFrom(content)).build(); RecognizeResponse recognizeResponse = speech.recognize(recConfig, recognitionAudio); // Just print the first result here. SpeechRecognitionResult result = recognizeResponse.getResultsList().get(0); // There can be several alternative transcripts for a given chunk of speech. Just use the // first (most likely) one here. SpeechRecognitionAlternative alternative = result.getAlternativesList().get(0); System.out.printf("Transcript : %s\n", alternative.getTranscript()); >>Nœud.js
Pour s’authentifier dans le texte parole, configurer les informations d’identification par défaut de l’application. Pour plus d’informations, voir Configurer l’authentification pour un environnement de développement local.
// importe la bibliothèque client de Google Cloud pour Beta API / ** * TODO (développeur): Mettez à jour l'importation de la bibliothèque client pour utiliser la nouvelle version * de l'API lorsque les fonctionnalités souhaitées deviennent disponibles * / const Speech = require (@ google-cloud / speech ').v1p1beta1; const fs = require ('fs'); // crée un client const client = nouveau discours.SpeechClient (); / ** * TODO (développeur): Décommente les lignes suivantes avant d'exécuter l'échantillon. * / // const filename = 'chemin local vers le fichier audio, e.g. / chemin / vers / audio.brut'; // const Model = 'modèle à utiliser, e.g. Phone_Call, vidéo, par défaut '; // constant coding = 'Encoding du fichier audio, e.g. Linéaire16 '; // const SamplerateHertz = 16000; // const LangonageCode = 'BCP-47 Code de langue, E.g. en-us '; const config = < encoding: encoding, sampleRateHertz: sampleRateHertz, languageCode: languageCode, model: model, >; const Audio = < content: fs.readFileSync(filename).toString('base64'), >; const de demande = < config: config, audio: audio, >; // détecte le discours dans le fichier audio const [réponse] = attendre le client.reconnaître (demande); Const transcription = réponse.résultats .map (résultat => résultat.Alternatives [0].transcription) .join ('\ n'); console.log ('transcription:', transcription);Python
Pour s’authentifier dans le texte parole, configurer les informations d’identification par défaut de l’application. Pour plus d’informations, voir Configurer l’authentification pour un environnement de développement local.
Def transcribe_model_selection (Speech_file, modèle): "" "Transcrire le fichier audio donné de manière synchrone avec le modèle sélectionné."" "De Google.Cloud Import Speech Client = Speech.SpeechClient () avec Open (Speech_File, "RB") comme Audio_file: Content = Audio_file.lire () audio = discours.RecognitionAudio (Content = Content) config = Speech.RecognitionConfig (Encoding = Speech.RecognitionConfig.Audioencodage.Linear16, samptample_rate_hertz = 16000, linguiste_code = "en-us", modèle = modèle,) réponse = client.reconnaître (config = config, audio = audio) pour i, entraîner un énumération (réponse.résultats): alternative = résultat.alternatives [0] print ("-" * 20) imprimer (f "première alternative du résultat") imprimer (f "transcription:") Langues supplémentaires
C #: Veuillez suivre les instructions de configuration C # sur la page des bibliothèques des clients, puis visitez la documentation de référence de parole pour le texte pour .FILET.
Php: Veuillez suivre les instructions de configuration PHP sur la page des bibliothèques des clients, puis visitez la documentation de référence de parole pour PHP.
Rubis: Veuillez suivre les instructions de configuration de Ruby sur la page des bibliothèques des clients, puis visitez la documentation de référence de parole pour Ruby.
Demande de fichier distant
Java
Pour s’authentifier dans le texte parole, configurer les informations d’identification par défaut de l’application. Pour plus d’informations, voir Configurer l’authentification pour un environnement de développement local.
/ ** * Effectue la transcription du fichier audio distant de manière asynchrone avec le modèle sélectionné. * * @param gcSuri le chemin d'accès au fichier audio distant à transcrire. * / public static void transcricmodeLelectiongcs (String gcsuri) lève une exception < try (SpeechClient speech = SpeechClient.create()) < // Configure request with video media type RecognitionConfig config = RecognitionConfig.newBuilder() // encoding may either be omitted or must match the value in the file header .setEncoding(AudioEncoding.LINEAR16) .setLanguageCode("en-US") // sample rate hertz may be either be omitted or must match the value in the file // header .setSampleRateHertz(16000) .setModel("video") .build(); RecognitionAudio audio = RecognitionAudio.newBuilder().setUri(gcsUri).build(); // Use non-blocking call for getting file transcription OperationFutureresponse = speech.longRunningRecognizeAsync(config, audio); while (!response.isDone()) < System.out.println("Waiting for response. "); Thread.sleep(10000); >Liste des résultats = réponse.obtenir().getResultsList (); // imprime juste le premier résultat ici. SpeechrecognitionResult Result = Résultats.get (0); // il peut y avoir plusieurs transcriptions alternatives pour une partie de la parole donnée. Utilisez simplement le // d'abord (très probablement) ici. SpeechRecognitionalternative Alternative = Résultat.getAlternatisList ().get (0); Système.dehors.printf ("transcription:% s \ n", alternative.getTranscript ()); >>Nœud.js
Pour s’authentifier dans le texte parole, configurer les informations d’identification par défaut de l’application. Pour plus d’informations, voir Configurer l’authentification pour un environnement de développement local.
// importe la bibliothèque client de Google Cloud pour Beta API / ** * TODO (développeur): Mettez à jour l'importation de la bibliothèque client pour utiliser la nouvelle version * de l'API lorsque les fonctionnalités souhaitées deviennent disponibles * / const Speech = require (@ google-cloud / speech ').v1p1beta1; // crée un client const client = nouveau discours.SpeechClient (); / ** * TODO (développeur): Décommente les lignes suivantes avant d'exécuter l'échantillon. * / // const gcsuri = 'gs: // my-bucket / audio.brut'; // const Model = 'modèle à utiliser, e.g. Phone_Call, vidéo, par défaut '; // constant coding = 'Encoding du fichier audio, e.g. Linéaire16 '; // const SamplerateHertz = 16000; // const LangonageCode = 'BCP-47 Code de langue, E.g. en-us '; const config = < encoding: encoding, sampleRateHertz: sampleRateHertz, languageCode: languageCode, model: model, >; const Audio = < uri: gcsUri, >; const de demande = < config: config, audio: audio, >; // détecte le discours dans le fichier audio. const [réponse] = attendre le client.reconnaître (demande); Const transcription = réponse.résultats .map (résultat => résultat.Alternatives [0].transcription) .join ('\ n'); console.log ('transcription:', transcription);Python
Pour s’authentifier dans le texte parole, configurer les informations d’identification par défaut de l’application. Pour plus d’informations, voir Configurer l’authentification pour un environnement de développement local.
Def transcribe_model_selection_gcs (GCS_URI, modèle): "" "Transcrire le fichier audio donné de manière asynchrone avec le modèle sélectionné."" "De Google.Cloud Import Speech Client = Speech.SpeechClient () Audio = Speech.RecognitionAudio (uri = gcs_uri) config = discours.RecognitionConfig (Encoding = Speech.RecognitionConfig.Audioencodage.Linear16, samptample_rate_hertz = 16000, linguiste_code = "en-us", modèle = modèle,) opération = client.long_running_recognize (config = config, audio = audio) print ("En attente de l'opération terminée. ") Réponse = opération.Résultat (tempsout = 90) pour i, entraîner un énumération (réponse.résultats): alternative = résultat.alternatives [0] print ("-" * 20) imprimer (f "première alternative du résultat") imprimer (f "transcription:") Langues supplémentaires
C #: Veuillez suivre les instructions de configuration C # sur la page des bibliothèques des clients, puis visitez la documentation de référence de parole pour le texte pour .FILET.
Php: Veuillez suivre les instructions de configuration PHP sur la page des bibliothèques des clients, puis visitez la documentation de référence de parole pour PHP.
Rubis: Veuillez suivre les instructions de configuration de Ruby sur la page des bibliothèques des clients, puis visitez la documentation de référence de parole pour Ruby.
Nettoyer
Pour éviter de souscrire des frais à votre compte Google Cloud pour les ressources utilisées dans ce tutoriel, supprimez le projet qui contient les ressources, soit conserver le projet et supprimer les ressources individuelles.
Supprimer le projet
Le moyen le plus simple d’éliminer la facturation est de supprimer le projet que vous avez créé pour le tutoriel.
- Tout dans le projet est supprimé. Si vous avez utilisé un projet existant pour ce tutoriel, lorsque vous le supprimez, vous supprimez également tout autre travail que vous avez fait dans le projet.
- Les identifiants de projet personnalisés sont perdus. Lorsque vous avez créé ce projet, vous avez peut-être créé un ID de projet personnalisé que vous souhaitez utiliser à l’avenir. Pour préserver les URL qui utilisent l’ID du projet, comme un apppot.com URL, supprimez les ressources sélectionnées à l’intérieur du projet au lieu de supprimer l’ensemble du projet.
Avertir: La suppression d’un projet a les effets suivants:
Si vous prévoyez d’explorer plusieurs tutoriels et Quickstarts, la réutilisation des projets peut vous aider à éviter de dépasser les limites de quota du projet.
Supprimer les instances
- Dans la console Google Cloud, allez au Instances VM page. Aller aux instances VM
- Sélectionnez la case à cocher pour l’instance que vous souhaitez supprimer.
- Pour supprimer l’instance, cliquez sur More_vert Plus d’actions, Cliquez sur Supprimer, puis suivez les instructions.
Supprimer les règles de pare-feu pour le réseau par défaut
- Dans la console Google Cloud, allez au Pare-feu page. Aller au pare-feu
- Sélectionnez la case à cocher pour la règle du pare-feu que vous souhaitez supprimer.
- Pour supprimer la règle du pare-feu, cliquez sur Supprimer Supprimer.
Et après
- Apprenez à obtenir des horodatages pour l’audio.
- Identifiez différents orateurs dans un fichier audio.
Essayez-le par vous-même
Si vous êtes nouveau dans Google Cloud, créez un compte pour évaluer comment le discours à texte fonctionne dans les scénarios du monde réel. Les nouveaux clients obtiennent également 300 $ en crédits gratuits pour exécuter, tester et déployer des charges de travail.
Envoyer des commentaires
Sauf indication contraire, le contenu de cette page est licencié sous l’attribution Creative Commons 4.0 Licence et les échantillons de code sont sous licence sous l’Apache 2.0 Licence. Pour plus de détails, consultez les politiques du site Google Developers. Java est une marque déposée d’Oracle et / ou de ses affiliés.
Dernière mise à jour 2023-05-19 UTC.
Transcrire dans Google Docs: transcription audio à texte
Cet article examinera comment transcrire dans Google Docs à l’aide de la fonction de frappe vocale. Cet outil de transcription gratuit est utile pour de nombreuses tâches en plus de la frappe vocale régulière: vous pouvez mettre vos idées sous forme écrite rapidement, obtenir des notes difficiles des réunions et créer des scripts pour les discours également. Les transcriptions sont utiles pour un certain nombre de raisons: ils sont consultables, vous pouvez les utiliser pour créer des sous-titres, et’est facile de les sauver pour référence future.
Google Docs peut-il transcrire un fichier audio?
Peu de gens savent que vous pouvez utiliser Google Docs pour transcrire des fichiers audio (bien que nous ne faisons pas’t le recommande! Au lieu de cela, utilisez un outil tiers comme SPF.IO pour obtenir des transcriptions précises et rapides à partir de fichiers audio). N’oubliez pas que l’utilisation d’un outil pour autre chose que son objectif principal vous donnera des résultats moins que idéaux. Si vous utilisez la frappe vocale pour obtenir des transcriptions gratuites à partir de fichiers audio, l’écriture manquera de ponctuation, aura probablement des mots incorrects ou manquants et nécessitera une modification substantielle par la suite.
Ce sont quelques avantages à utiliser la fonction de typage vocale Google Docs:
-GRATUIT: Google Docs ne nécessite aucun frais pour commencer.
-Modifiable: le texte dans un Google Doc est facile à modifier, à commenter et à utiliser avec des collaborateurs qui vous aident
-Facilement partageable: puisque vous’Ren travaillant directement dans Google Docs, vous pouvez utiliser le
“partager” fonctionnalité pour envoyer votre transcription à des amis et des collègues
Inconvénients de l’utilisation d’outils de transcription gratuits comme Google Docs:
-Pas de traduction
-Pas d’horodatage
-Pas de ponctuation automatique (vous pouvez dire verbalement “période” ou “virgule,” Mais les documents ne se transcrire pas avec ponctuation. En savoir plus sur les commandes vocales ici).
-Pas de dictionnaire personnalisé ou de corrections d’orthographe automatique (si vous voulez cette fonctionnalité, utilisez SPF.IO et créez votre propre base de données de remplacement automatique)
Comment utiliser Google’outil de text-vocation
Une fois que vous avez un fichier audio, suivez ces étapes pour transcrire dans Google Docs:
- Créez un nouveau doc:
Ouvrez un nouveau fichier Google Doc sur https: // docs.Google.com / document /
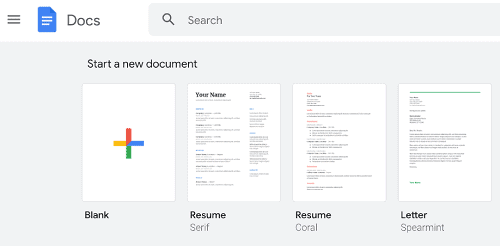
- Activer le texte-parole:
Sous les outils, sélectionnez “Typage vocal”
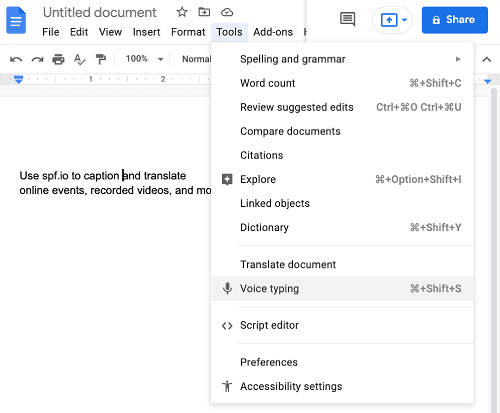
- Sélectionnez votre langue de transcription:
Lorsque le microphone apparaît, vous pouvez utiliser la flèche déroulante à côté de la langue affichée (dans ce cas, l’anglais (États-Unis)) pour sélectionner votre langue. Lorsque vous transcrivez dans Google Docs pour un travail bilingue, vous’Je dois faire une pause et éteindre le microphone avant de passer à une nouvelle langue chaque fois que vous voulez en parler un autre.
- Commencez à transcrire votre fichier audio:
Commencez à lire votre fichier audio dans une autre fenêtre (assurez-vous qu’il joue sur vos haut-parleurs, pas via un casque!). Cliquez sur le microphone dans Google Docs dès que possible pour capturer le son. La raison pour laquelle vous devez le faire dans l’ordre est que si vous cliquez loin de la fenêtre Google Docs, la transcription s’arrêtera. L’inconvénient est que vous’LL perdez la première partie de votre fichier audio ou vidéo lorsque vous cliquez sur Google Docs pour démarrer la transcription.
- Modifiez votre transcription:
C’est la partie la plus longue de ce processus depuis que vous avez gagné’t Obtenez la ponctuation ajoutée automatiquement lorsque vous transcrivez sur Google Docs. Notez que vous pouvez’t Modifier le texte dans le document lorsque votre vidéo / audio est en cours de transcription – la typage vocal ajoutera du texte partout où vous mettez votre curseur.
D’autres façons d’utiliser Google Docs Speech-to-Text:
- Écrivez plus rapidement
- Prendre des notes d’une réunion
- Créer un script pour un discours
Transcriptions audio / vidéo faciles et précises avec SPF.Io
Bien que le processus à transcrire dans Google Docs soit gratuit, cela peut prendre beaucoup de temps (ce qui peut finir par être plus cher à la fin!). Nous vous recommandons d’utiliser des outils tiers comme SPF.IO pour obtenir des transcriptions précises qui nécessitent une modification moins longue que les outils gratuits nécessiteront. Ceci est particulièrement nécessaire si vous avez de nombreuses heures de vidéo / audio à transcrire.
Avec SPF.IO, vous pouvez même utiliser votre transcription pour créer des légendes et des sous-titres. Puisque nous proposons de nombreuses options dans notre outil tout-en-un, vous avez la liberté de traduire votre texte en plus de 60 langues! Nous offrons également des sous-titres en direct pour la plupart des plateformes comme Zoom, Streamyard, YouTube, et plus.
Fatigué d’essayer de transcrire dans Google Docs? Simplifiez votre processus et obtenez un devis de SPF.IO pour votre projet de transcription!
Transcription du contenu audio: ressources et comment

Si vous souhaitez transcrire du contenu audio, alors vous’venez au bon endroit. Que vous choisissiez d’utiliser un service de transcription tiers ou de bricolage (faites-le vous-même), il’est important de peser les avantages et les inconvénients et de choisir l’option qui vous convient le mieux.
Avantages de la transcription audio
- Créer une meilleure expérience utilisateur
- Augmentez vos chances d’être citées et créditées
- Stimuler l’optimisation des moteurs de recherche (SEO)
- Améliorer l’accessibilité pour les utilisateurs d / sourds ou malentendants
De plus, de nombreuses entreprises et organisations Légalement nécessaire pour créer des transcriptions pour leur contenu Basé sur la loi sur les Americans with Disabilities et les articles 504 et 508 de la loi de réadaptation. Wcag 2.0 est un ensemble de lignes directrices mises en place par le World Wide Web Consortium pour rendre le contenu numérique plus accessible pour les utilisateurs, y compris ceux handicapés. Wcag 2.0 a trois niveaux de conformité: niveau A, AA et AAA. L’article 508 a été révisé pour se conformer au WCAG 2.0 Niveau A et AA. Selon le niveau le plus bas, le niveau A, des transcriptions sont recommandées pour le contenu audio uniquement.
Nous’LL fournira les différentes ressources que vous’Il faut transcrire un fichier audio et vous aider à déterminer le choix le plus viable en fonction de votre budget, de votre temps et de vos besoins particuliers. Bonne chance et bonne transcription!
Transcription de bricolage
La transcription manuelle de l’audio peut être une tâche intimidante, surtout lorsque vous avez des formes de contenu plus longues. Cela prend généralement 5 à 6 fois le temps réel du contenu. Heureusement, il existe de nombreux outils gratuits et à faible coût pour simplifier le processus. Avant de commencer la transcription, assurez-vous de vous Capture audio clair et bruyant. Cela aidera à réduire les drapeaux rouges et les sons inaudibles dans votre transcription.
Youtube

Si vous hébergez votre contenu audio sur YouTube, vous pouvez utiliser l’outil de transcription vidéo automatique gratuit. Cet outil transcrit automatiquement l’audio en texte, mais gardez à l’esprit qu’il est livré avec beaucoup d’erreurs. Transcriptions produites par YouTube’L’outil S est trop inexact pour être utilisé seul. Par conséquent, il’est fortement recommandé de les nettoyer car ils peuvent Nouez votre accessibilité vidéo et votre classement sur les pages de résultats des moteurs de recherche (SERP).
Ici’s Comment tirer parti de YouTube’S Transcription vidéo automatique:
- Dans le gestionnaire vidéo, sélectionnez votre vidéo et cliquez Éditer> sous-titres et cc. Sélectionner Ajouter des sous-titres ou CC Et choisissez votre langue.
- Sélectionner Transcrire et définir des horaires, et tapez la transcription dans l’espace fourni. YouTube suscitera automatiquement la vidéo en tapant afin que vous puissiez transcrire plus rapidement et avec précision.
- Une fois que vous êtes satisfait, sélectionnez Se dérouler des horaires. Cela synchronisera votre transcription avec la vidéo.
De même, vous pouvez créer un transcrit à l’avance et le télécharger sur YouTube:
- Tout d’abord, créez une transcription avec Youtube’S Recommandations pour la mise en forme.
- Accédez au directeur vidéo sur YouTube et cliquez Éditer> sous-titres et cc. Sélectionnez Ajouter des sous-titres ou CC et choisissez votre langue.
- Choisir Télécharger un fichier, sélectionner Transcription, Et choisissez votre .fichier txt pour le téléchargement.
- Une fois votre relevé de notes téléchargé, cliquez Se dérouler des horaires Pour synchroniser votre transcription avec la vidéo et créer des légendes fermées.
Vous pouvez également télécharger le fichier de transcription plus tard avec des horaires en tant que fichier de légende:
- Accédez à la vidéo à partir de laquelle vous souhaitez télécharger la transcription. Clique sur le Plus d’actions bouton (3 points horizontaux). Astuce: ça’S Situé à côté du bouton Partager.
- Sélectionnez le Transcription option.
- Une transcription des légendes fermées avec les codes de temps générera automatiquement.
Logiciel ASR

La reconnaissance automatique de la parole, autrement connue sous le nom d’ASR, est une technologie qui ramasse la parole humaine et la convertit en texte. Vous pouvez télécharger vos médias sur ASR Software, et il transcrira automatiquement l’audio en texte. Cette méthode est toujours livrée avec de nombreuses erreurs, mais’est beaucoup plus facile et plus rapide pour nettoyer une transcription inexacte que de commencer à zéro.
Il existe de nombreuses options de logiciel de transcription qui sont gratuites ou disponibles pour un petit coût, telles que Express Scribe, Erescribe et Dragon NaturallySpeaking.
Google Docs
Google propose une fonctionnalité impressionnante qui vous permet de transformer les documents en logiciel de transcription gratuit. Si tu ne fais pas’t avoir un compte gmail, vous pouvez vous inscrire à un gratuitement. Si vous avez un compte existant, vous avez déjà accès à une fonctionnalité appelée Google Docs; Google Docs est un outil de traitement de texte qui vous permet de créer des documents texte dans votre navigateur Web. À l’aide de la frappe vocale, Google Voice Transcription peut créer des transcriptions de texte à partir de l’audio. Comme beaucoup d’autres outils de transcription manuelle, il y aura des erreurs, alors assurez-vous de le nettoyer avant de l’utiliser.
Suivez ces étapes pour créer votre transcription:
- À l’aide de n’importe quel navigateur de votre choix, accédez au site Web de Google Docs et Démarrer un nouveau document.
- Cliquer sur Outils et sélectionner Typage vocal. Cela permettra la reconnaissance vocale.
- Clique le Microphone icône à gauche pour activer Typage vocal. Google transcrira tout ce qui est dit au document Word.
iOS / Android

Une autre façon de transcrire du contenu audio est d’utiliser votre smartphone. Semblable à Google Docs, le microphone reprendra l’audio et le transcrira dans le texte. La transcription sur votre smartphone a tendance à fonctionner un peu mieux que Google Docs, car le microphone sur votre téléphone ramasse moins de bruit de fond; Cependant, ce n’est toujours pas’t comparer à un microphone de haute qualité. L’enregistrement sur votre smartphone a gagné’t Assurer un taux de précision élevé, vous devrez donc nettoyer la transcription finale.
Voici des instructions étape par étape pour transcrire l’audio en texte avec votre smartphone:
- Ouvrir un application de traitement de texte sur votre smartphone.
- Sur le clavier de votre smartphone, sélectionnez le Microphone bouton, et il commencera à enregistrer.
- Tenez votre téléphone près de votre ordinateur ou d’un autre appareil et Recherche la vidéo. Votre téléphone transformera automatiquement l’audio en texte.
PROS VS. Inconvénients des transcriptions de bricolage
Avantages
- Plus budgétaire
- Bon pour le contenu plus court
Les inconvénients
- Qui prend du temps à créer
- Travail intensif
- Niveau de faible précision
Services de transcription
Une autre option pour transcrire du contenu audio au texte est d’utiliser un service de transcription tiers. Si tu’Re cherchez des transcriptions précises et précises, c’est certainement la voie à suivre!
3Play Media propose un Processus de transcription en 3 étapes qui utilise à la fois la technologie et les transcriptistes humains, assurant un 99.Taux de précision de 6%. Lorsque le fichier audio se compose d’un contenu difficile, a un bruit de fond ou contient des accents, le taux de précision diminue. ASR fournit généralement une précision de 60 à 70%, de sorte que l’utilisation des transcriptiteurs humains distingue 3 Play des autres options de transcription.
Notre technologie brevetée utilise ASR pour produire automatiquement une transcription approximative, ce qui est utile pour créer des horaires précis même si les mots et la grammaire sont incorrects. À l’aide d’un logiciel propriétaire, nos transcripteurs passent et modifient la transcription. Tous nos transcriptiteurs subissent un processus de certification rigoureux et ont une forte compréhension de la grammaire anglaise, ce qui est important pour comprendre toutes les nuances de votre contenu. Après le processus d’édition, votre fichier passe par une revue finale appelée Quality Assurance. Votre fichier est examiné par nos meilleurs éditeurs, qui s’assurent que votre transcription est pratiquement sans faille.
Une fonctionnalité que nous proposons également est le Transcription interactive 3Play. Cette fonctionnalité permet aux utilisateurs d’interagir avec votre vidéo en recherchant la vidéo, en naviguant en cliquant sur n’importe quel mot et en lisant avec l’audio. Les transcriptions interactives rendent votre contenu plus accessible et améliorent l’expérience utilisateur.
PROS VS. Inconvénients d’un service de transcription
Avantages
- Niveau de haute précision
- Plus fiable
- Gère les grandes quantités de contenu
- Accès aux outils uniques
- Accès au personnel qualifié
Les inconvénients
- Plus cher
Meilleures pratiques de transcription
Maintenant que vous avez une meilleure compréhension de la transcription manuelle par rapport à un service de transcription, vous pouvez prendre une décision éclairée. Quelle que soit l’option que vous choisissez,’est important de savoir comment Tirez le meilleur parti de vos transcriptions.
- Grammaire et ponctuation: Assurez-vous qu’il n’y a pas d’erreurs dans votre transcription afin qu’il soit facile à lire.
- Identification de l’orateur: Utilisez des étiquettes de haut-parleurs pour identifier qui parle, surtout lorsqu’il y a plusieurs haut-parleurs.
- Sons de non-parole: Communiquer des sons de non-discours dans les transcriptions. Ceux-ci sont généralement indiqués avec [les crochets].
- Textuellement: Transcrire le contenu aussi près que possible mot à mot. Laisser de côté des mots de remplissage tels que “um” ou “comme” à moins qu’ils’concernant intentionnellement dans l’audio.
Veux en savoir plus?

Ce message a été initialement publié par Samantha Sauld le 30 août 2018 et a depuis été mis à jour.
Transcrire la parole au texte en utilisant la console Google Cloud
Ce QuickStart vous présente la console de la parole du cloud. Dans ce quickstart, vous allez créer et affiner une transcription et apprendre à utiliser cette configuration avec l’API de la parole pour le texte pour vos propres applications.
Pour apprendre à envoyer des demandes et à recevoir des réponses en utilisant l’API REST au lieu de la console, consultez la page avant de commencer.
Avant que tu commences
Avant de pouvoir commencer à utiliser la console parole à texte, vous devez activer l’API dans la console de la plate-forme Google Cloud. Les étapes ci-dessous vous guident à travers les actions suivantes:
- Activer la parole à texte sur un projet.
- Assurez-vous que la facturation est activée pour le discours à texte.
Configurez votre projet Google Cloud
- Connectez-vous à Google Cloud Console
- Accédez à la page Sélecteur de projet Vous pouvez soit choisir un projet existant ou en créer un nouveau. Pour plus de détails sur la création d’un projet, voir Google Cloud Platform Documentation.
- Si vous créez un nouveau projet, vous serez invité à relier un compte de facturation à ce projet. Si vous utilisez un projet préexistant, assurez-vous que vous avez activé la facturation. Apprenez à confirmer que la facturation est activée pour votre projetNote: Vous devez permettre à la facturation d’utiliser l’API de la parole à texte, mais vous ne serez facturé que si vous dépassez le quota gratuit. Voir la page de tarification pour plus de détails.
- Une fois que vous avez sélectionné un projet et l’avoir lié à un compte de facturation, vous pouvez activer l’API Speech-to-Text. Aller au Rechercher des produits et des ressources bar en haut de la page et tapez “discours”.
- Sélectionnez le API Speech-the-Text cloud à partir de la liste des résultats.
- Pour essayer la parole de texte sans le lier à votre projet, choisissez le Essayez cette API option. Pour activer l’API Speech-to-Text pour une utilisation avec votre projet, cliquez ACTIVER.
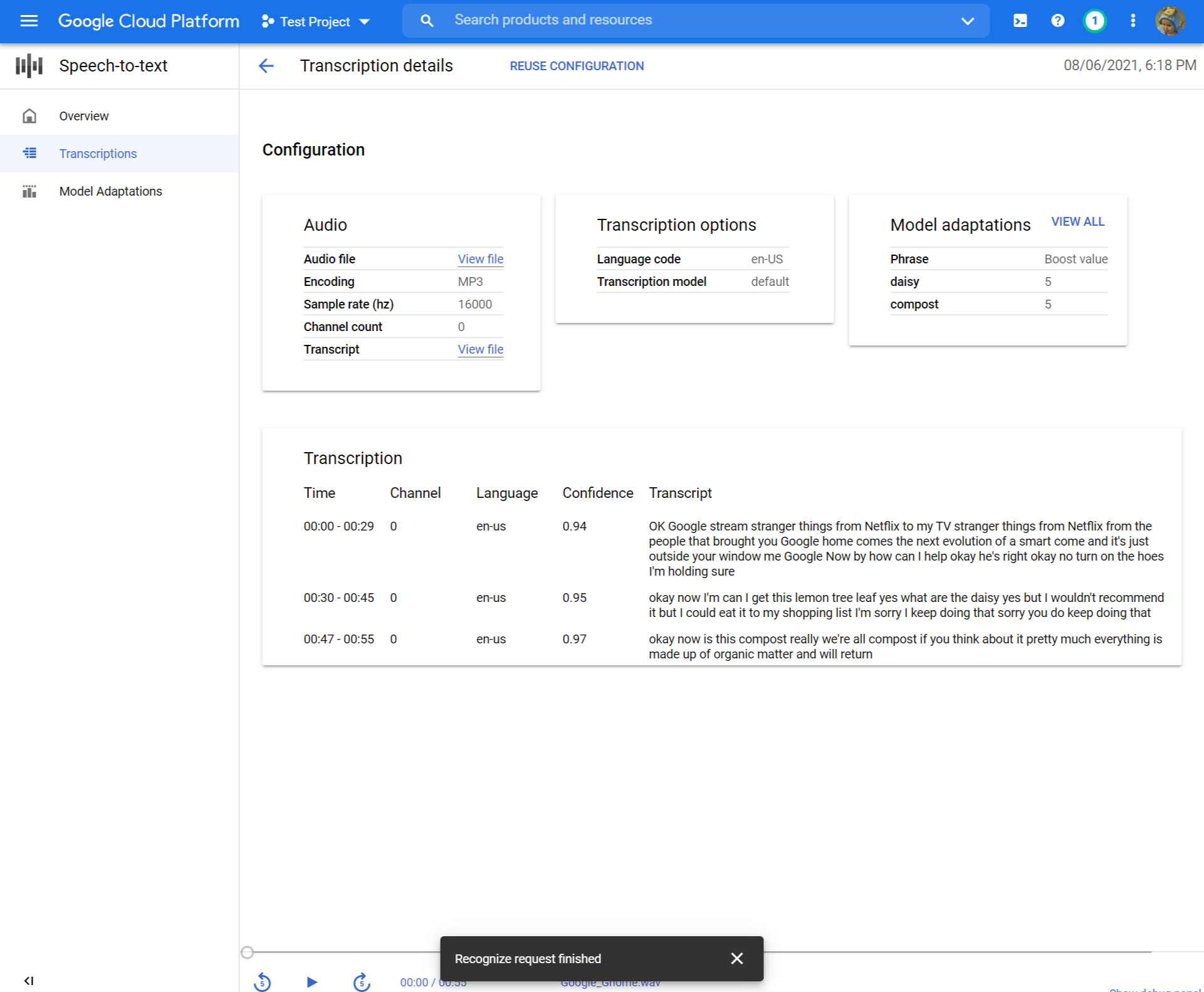
Créer une transcription
Utilisez la console Google Cloud pour créer une nouvelle transcription:
Configuration audio
- Ouvrir le Discours à texte aperçu.

- Cliquez sur Créer une transcription.
- Si c’est la première fois que vous utilisez la console, il vous sera demandé de choisir où dans le stockage dans le cloud pour stocker vos configurations et transcriptions.
- Si c’est la première fois que vous utilisez la console, il vous sera demandé de choisir où dans le stockage dans le cloud pour stocker vos configurations et transcriptions.
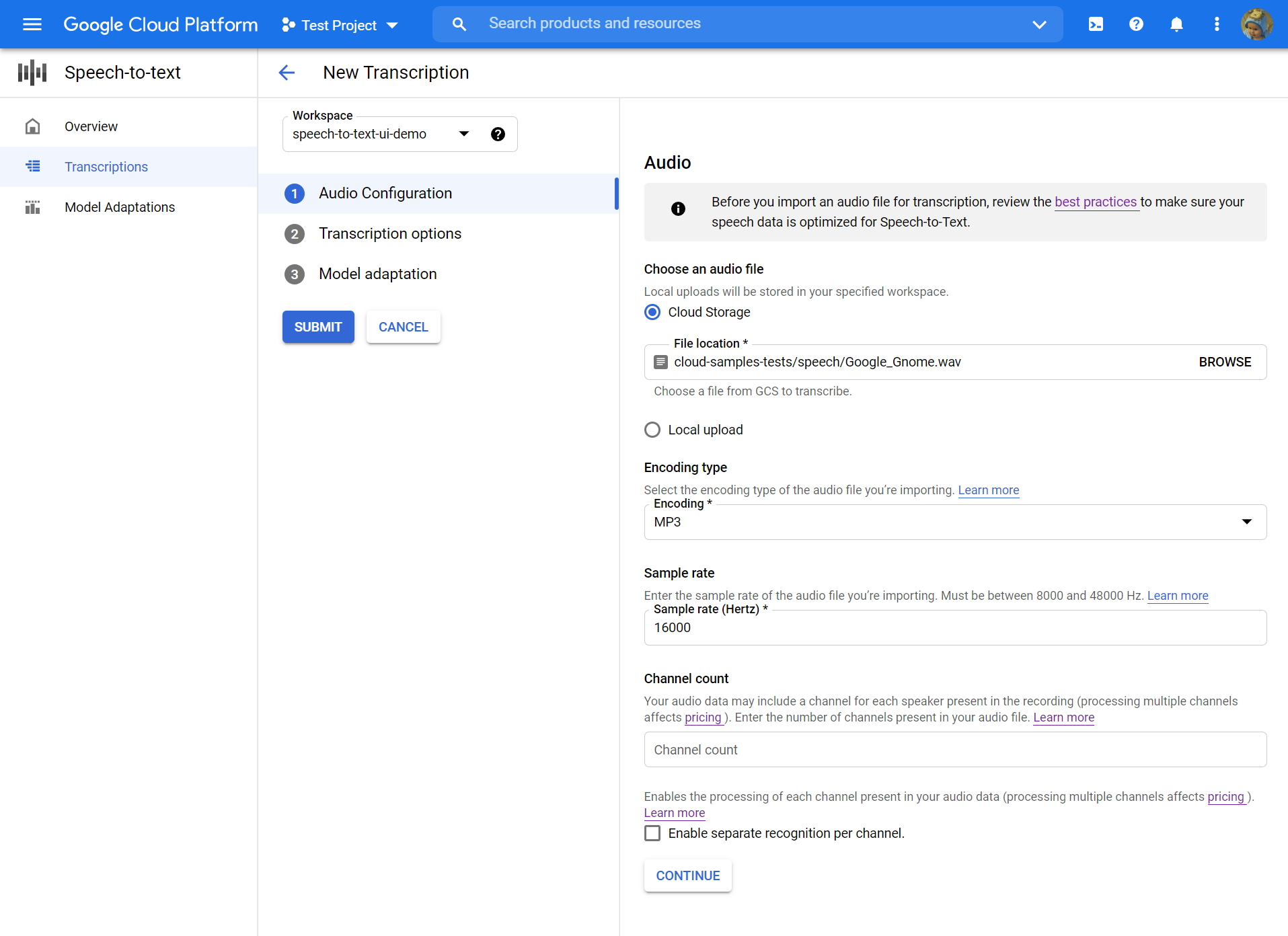
- Dans le Créer une transcription page, Télécharger un fichier audio source. Vous pouvez choisir un fichier déjà enregistré dans le stockage cloud ou en télécharger un nouveau sur votre destination de stockage cloud spécifié.
- Sélectionnez les fichiers audio téléchargés type de codage.
- Spécifiez son taux d’échantillonnage.
- Cliquez sur Continuer. Vous serez emmené à Options de transcription.
Options de transcription

- Sélectionnez le code linguistique de votre audio source. C’est la langue parlée dans l’enregistrement.
- Choisir la modèle de transcription Vous souhaitez utiliser sur le fichier. L’option par défaut est présélectionnée et, généralement, aucun changement n’est nécessaire, mais faire correspondre le modèle au type d’audio peut entraîner une précision plus élevée. Notez que les coûts du modèle varient.
- Cliquez sur Continuer. Vous serez emmené à Adaptation modèle.
Adaptation du modèle (facultatif)
Si votre audio source contient des choses comme des mots rares, des noms propres ou des termes propriétaires et que vous rencontrez des problèmes de reconnaissance, l’adaptation du modèle peut aider.

- Vérifier Allumez l’adaptation du modèle.
- Choisir Ressource d’adaptation unique.
- Ajouter pertinent phrases Et donnez-leur un valeur de renforcement.
- Dans la colonne de gauche, cliquez Soumettre Pour créer votre transcription.
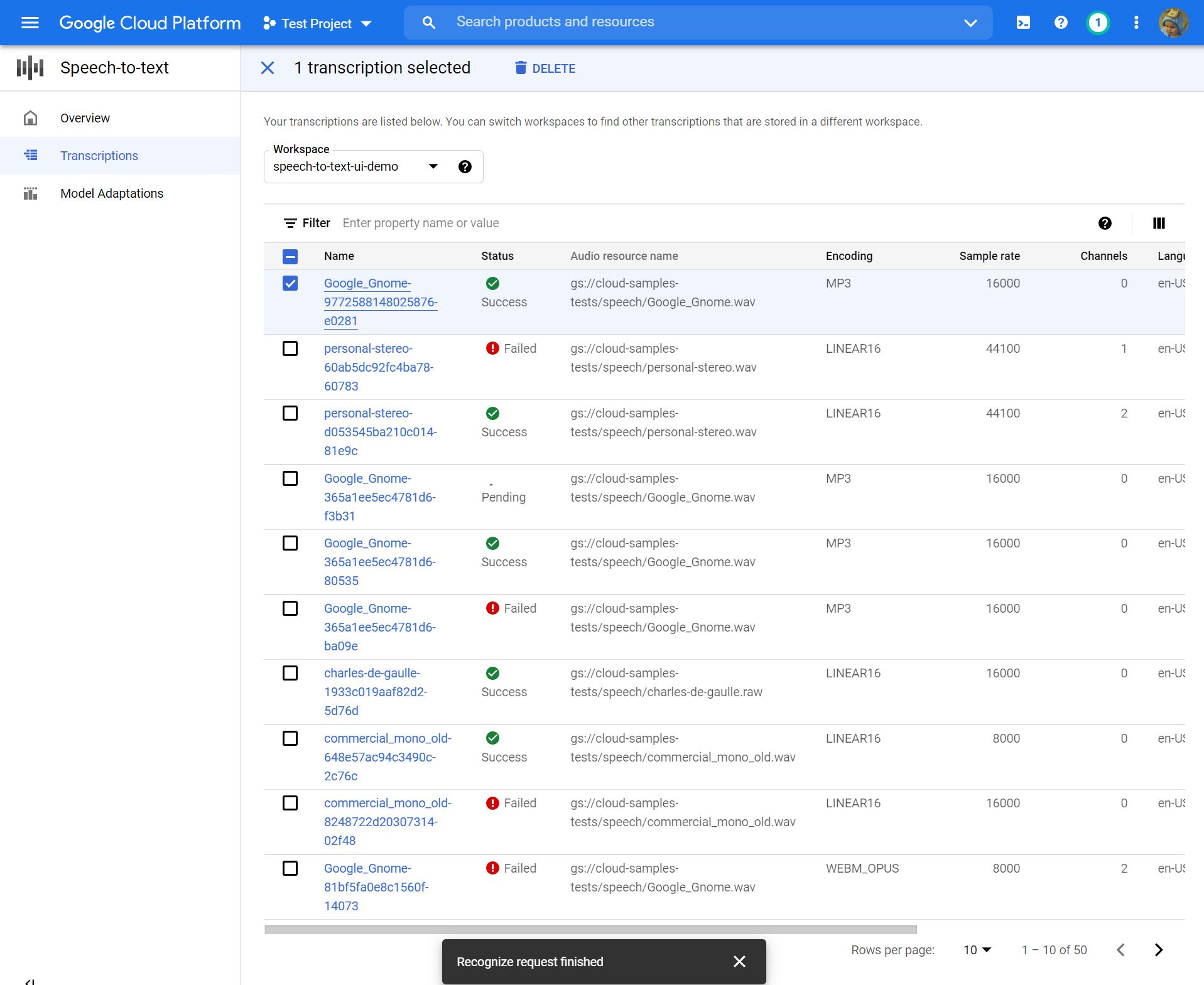
Passez en revue votre transcription
Selon la taille de votre fichier audio, une transcription peut prendre de minutes à heures. Une fois votre transcription créée, elle est prête à examen. Le tri du tableau par horodat peut vous aider à localiser facilement vos transcriptions récentes.
- Clique sur le Nom de la transcription que vous souhaitez revoir.
- Comparez le Transcription Texte dans le fichier audio
- Si vous souhaitez apporter des modifications, cliquez Réutiliser la configuration. Cela vous amènera au Créer une transcription Flux avec les mêmes options présélectionnées, vous permettant de modifier quelques choses, de créer une nouvelle transcription et de comparer les résultats.
Et après
- Pratiquez la transcription des fichiers audio courts.
- Apprenez à lancer de longs fichiers audio pour la reconnaissance vocale.
- Apprenez à transcrire l’audio en streaming comme un microphone.
- Commencez avec la parole à texte dans votre langue de choix en utilisant une bibliothèque client de discours à texte.
- Travailler sur les applications d’échantillons.
- Pour les meilleures performances, précision et autres conseils, consultez la documentation des meilleures pratiques.
Envoyer des commentaires
Sauf indication contraire, le contenu de cette page est licencié sous l’attribution Creative Commons 4.0 Licence et les échantillons de code sont sous licence sous l’Apache 2.0 Licence. Pour plus de détails, consultez les politiques du site Google Developers. Java est une marque déposée d’Oracle et / ou de ses affiliés.
Dernière mise à jour 2023-05-16 UTC.