


Facebook ha i propri datacenter
Facebook ha i propri data center?
Riepilogo:
Meta (precedentemente Facebook) ha attualmente 47 data center in costruzione, con piani per avere più di 70 edifici nel prossimo futuro. Ciò riflette l’espansione globale delle infrastrutture dell’azienda, con 18 campus di data center in tutto il mondo per un totale di 40 milioni di piedi quadrati. Nonostante le sfide poste dalla pandemia e dalle interruzioni della catena di approvvigionamento, Meta prevede di investire tra $ 29 miliardi e $ 34 miliardi di spese in conto capitale nel 2022.
Punti chiave:
- Meta ha 47 data center in costruzione e piani per oltre 70 edifici nel prossimo futuro.
- La società ha 18 campus di data center in tutto il mondo.
- L’espansione durante le interruzioni della pandemia e della catena di approvvigionamento è impegnativa.
- Meta prevede di investire tra $ 29 miliardi e $ 34 miliardi di spese in conto capitale nel 2022.
- Gli operatori di iperscale come Meta e Microsoft stanno versando miliardi nell’espansione della propria infrastruttura del data center.
- Apri Calcolo Progetto, fondato da Facebook, guida l’innovazione in hardware.
- La costruzione del data center richiede processi di selezione e costruzione del sito flessibili.
- Meta guarda ai venditori e agli appaltatori come partner nella guida delle migliori pratiche e il miglioramento continuo.
- Meta e altri operatori di iperscale sono pionieristici nuove strategie per fornire scala e velocità.
- La scala e la sfida del programma Data Center sono una forza trainante per il meta.
Domande:
- Qual è lo stato attuale della costruzione del data center di Meta?
- Quanti campus di data center hanno meta in tutto il mondo?
- Quali sfide affrontano il meta -center nell’espansione del data center?
- Quanto meta pianifica per investire nelle spese in conto capitale nel 2022?
- Quali aziende stanno inoltre investendo nell’espansione delle infrastrutture dei data center?
- Qual è il ruolo del progetto di calcolo aperto?
- Quali fattori sono importanti nella costruzione del data center?
- In che modo i fornitori e gli appaltatori di Meta Visualizzano?
- Quali strategie sono i meta e altri operatori iperscale pionieristici?
- Cosa guida il programma Data Center di Meta?
Meta ha attualmente 47 data center in costruzione, con piani per oltre 70 edifici nel prossimo futuro.
Meta ha 18 campus di data center in tutto il mondo.
L’espansione del data center durante le interruzioni della pandemia e della catena di approvvigionamento pone sfide per il meta.
Meta prevede di investire tra $ 29 miliardi e $ 34 miliardi di spese in conto capitale nel 2022.
Anche gli operatori di iperscale come Microsoft stanno investendo miliardi nell’espansione della propria infrastruttura del data center.
Il progetto Open Compute, fondato da Facebook, guida l’innovazione in hardware.
La costruzione del data center richiede processi di selezione e costruzione del sito flessibili.
Meta vede venditori e appaltatori come partner nella guida delle migliori pratiche e il miglioramento continuo.
Meta e altri operatori di iperscale sono pionieristici nuove strategie per fornire scala e velocità.
La scala e la sfida del programma Data Center sono una forza trainante per il meta.
Facebook ha i propri datacenter
Cos’altro si spoglia Facebook? Frankovsky ha detto che “molte schede madri oggi arrivano con un sacco di management Goop. Questo è il termine tecnico che mi piace usare per questo.”Questo goop potrebbe essere il motore di gestione del ciclo di vita integrato di HP o gli strumenti di gestione del server remoto di Dell.
Facebook ha 47 data center in costruzione
Meta ha attualmente 47 data center in costruzione, ha affermato la società questa settimana, riflettendo la portata straordinaria dell’espansione in corso del mondo’S Digital Infrastructure.

Esso’s una breve dichiarazione, in profondità all’interno di una lunga revisione dell’innovazione su Facebook’S Digital Infrastructure. Ma per chiunque conosca l’industria dei data center,’è un vero occhi aperti.
“Come io’m Scrivendo questo, abbiamo 48 edifici attivi e altri 47 edifici in costruzione,” Disse Tom Furlong, presidente dell’infrastruttura, data center di Meta (precedentemente Facebook). “Quindi noi’avrà più di 70 edifici nel prossimo futuro.”
La dichiarazione riflette l’ambito straordinario della meta’S Espansione dell’infrastruttura globale. La società ha 18 campus di data center in tutto il mondo, che al completamento estenderanno 40 milioni di piedi quadrati di spazio del data center.
Avere 47 edifici in costruzione sarebbe una sfida in qualsiasi circostanza, ma in particolare durante una pandemia globale e l’interruzione della catena di approvvigionamento. Esso’non è facile o economico. Meta afferma che prevede di investire tra $ 29 miliardi e $ 34 miliardi di spese in conto capitale nel 2022, rispetto a $ 19 miliardi dell’anno scorso.
Esso’non solo, poiché i più grandi operatori di iperscale stanno versando miliardi di dollari nell’espansione della propria infrastruttura del data center per soddisfare la domanda per i loro servizi digitali. Le spese in conto capitale iperscale sono aumentate del 30 % nella prima metà del 2021, secondo un’analisi del gruppo di ricerca Synergy, che tiene traccia di 19 fornitori di iperscale che hanno speso circa $ 83 miliardi nel periodo di sei mesi.
Quei livelli di spesa potrebbero facilmente aumentare, alla luce di Facebook’S Proiezioni sulla spesa Capex futura e Microsoft’S prevede di costruire da 50 a 100 data center all’anno.
Innovazione infrastrutturale su scala epica
Furlong’S Blog post sul meta’Il viaggio del data center è utile leggere, così come un post di accompagnamento che ripensa ai progressi del progetto Open Calco.
“Open Hardware guida l’innovazione e lavorare con più fornitori significa maggiori opportunità per sviluppare hardware di prossima generazione per supportare le funzionalità attuali ed emergenti tra i meta’S Famiglia di tecnologie.,” Scrive Furlong.
La necessità di innovare su scala ha anche la costruzione del data center.
“C’è molta attività nel data center e nelle industrie delle costruzioni oggi, il che ci fa pressione per trovare i siti e i partner giusti,” ha detto Furlong. “Significa anche che dobbiamo creare processi di selezione e costruzione del sito più flessibili. Tutto questo sforzo implica anche la ricerca dei nostri fornitori e appaltatori come partner in tutto questo. Noi possiamo’t basta fare questo sui dollari. Dobbiamo fare per le prestazioni. Dobbiamo fare la guida delle migliori pratiche e il miglioramento continuo.
“Ma quello’non è il modo in cui l’industria delle costruzioni in genere funziona,” Lui continuò. “Quindi, noi’Ve ha dovuto portare molte delle nostre idee sulla gestione delle operazioni e apportando miglioramenti e impressionarle sulle aziende con cui lavoriamo.”
L’infrastruttura digitale sta diventando sempre più importante ogni giorno e la meta e le sue controparti iperscale sono nuove strategie per offrire la scala e la velocità di cui hanno bisogno. Esso’S un processo in corso, come riflette Furlong.
“Spostarsi nell’arena del data center non sarebbe mai stato facile,” lui scrive. “Ma penso che noi’è finito con un programma straordinario su una scala che non avrei mai immaginato. E noi’viene sempre chiesto di fare di più. Quello’è la sfida aziendale, ed It’è probabilmente una delle cose principali che mantengono me e il mio team che va al lavoro ogni giorno. Abbiamo questa enorme sfida davanti a noi per fare qualcosa di incredibilmente massiccio su vasta scala.”
Facebook ha i propri datacenter


Torna al blog a casa
сен 20 2016
Infrastruttura di Facebook: strategia e sviluppo del data center all’interno
Da meta carriere
Rachel Peterson guida il team di strategia del data center di Facebook. Il suo team gestisce il portafoglio di data center di Facebook e fornisce supporto strategico per identificare le opportunità per ulteriori infrastrutture, efficienza e affidabilità delle infrastrutture. Dai un’occhiata alla sua esperienza su Facebook e come il suo team sta lavorando per connettere il mondo.
Qual è la tua storia di Facebook?
Sono entrato a far parte di Facebook nel 2009 quando la società stava per lanciare il suo primo data center a Prineville, Oregon. A quel tempo, l’intero team di data center consisteva in meno di 30 membri del team e Facebook occupava due piccole impronte di co-locazione negli Stati Uniti. Mi sono unito per aiutare a costruire il programma di selezione del sito per i data center di proprietà di Facebook. Oggi il nostro team comprende oltre 100 persone in più località in tutto il mondo.
Avanti veloce ad oggi, Facebook ora possiede e gestisce un grande portafoglio di data center, che copre gli Stati Uniti, l’Europa e l’Asia. Il programma di selezione del sito ha lanciato con successo quindici enormi data center e ci impegniamo a alimentare questi data center con energia rinnovabile al 100%. Nel 2012, nel 2015 abbiamo fissato il nostro primo obiettivo di energia pulita e rinnovabile del 25%. Nel 2017, abbiamo superato il 50% di energia pulita e rinnovabile per tutte le operazioni di Facebook. Nel 2018, abbiamo fissato il nostro prossimo obiettivo aggressivo, con l’obiettivo di soddisfare l’energia pulita e rinnovabile al 100% per tutte le operazioni in crescita di Facebook entro la fine del 2020.
È stato davvero emozionante essere in prima linea in questa crescita e costruire il team che ha svolto un ruolo fondamentale nella coltivazione dell’infrastruttura di Facebook. Non c’è mai stato un momento noioso in questo fantastico viaggio! La crescita di Facebook ha reso sia impegnativo che divertente, e non credo che sia passato un giorno in cui non ho imparato. Amo quello che faccio e sono davvero fortunato a lavorare con una squadra così straordinaria e divertente. La cultura di Facebook consente al mio team di avere un impatto di vasta portata e insieme stiamo rendendo il mondo più aperto e connesso. Un data center alla volta.

La missione di Facebook è rendere il mondo più aperto e connesso, quale ruolo ha il tuo team in questo?
Guida la strategia di posizione globale di Facebook e gli sforzi di selezione del sito basati su una serie di criteri di ubicazione critica, tra cui nuove energia rinnovabile per supportare i siti.
Gestisce i programmi di conformità ambientale globale di Facebook, dalla selezione del sito durante le operazioni, tra cui la conformità dell’aria e dell’acqua.
Dirige i programmi energetici globali di Facebook, dalla selezione del sito durante le operazioni, ottimizzando l’approvvigionamento energetico per l’energia rinnovabile al 100%, assicurando al contempo la responsabilità fiscale e l’affidabilità.
Guida la pianificazione strategica, l’abilitazione e il monitoraggio della tabella di marcia globale dei data center.
Fornisce supporto per la scienza dei dati per consentire le decisioni strategiche e l’ottimizzazione delle prestazioni nel ciclo di vita dei data center.
Guida il nostro lavoro di coinvolgimento della comunità in luoghi in cui abbiamo data center.
Sviluppa e gestisce le strategie di mitigazione delle politiche e del rischio per consentire l’espansione globale di Facebook’impronta dell’infrastruttura S.
Facebook è impegnato ad essere una forza per il bene ovunque lavoriamo fornendo posti di lavoro, facendo crescere l’economia e supportando programmi a beneficio delle comunità in cui viviamo.
Il nostro team di sostenibilità’La missione è di supportare Facebook’capacità di operare e crescere in modo efficiente e responsabile e consentire alle persone di costruire comunità sostenibili.
Guida la strategia a livello aziendale nel guidare l’eccellenza operativa dalla progettazione, dalla costruzione e dal funzionamento della nostra attività. Diamo la priorità all’efficienza, alla conservazione dell’acqua e all’eccellenza della catena di approvvigionamento e siamo orgogliosi di dire che le nostre strutture sono tra le più efficienti dell’acqua ed efficienza energetica del mondo.
Ci impegniamo a combattere i cambiamenti climatici e abbiamo fissato un obiettivo scientifico per ridurre le nostre emissioni del 75 % entro il 2020.

I valori fondamentali di Facebook si muovono rapidamente, si concentrano sull’impatto, costruiscono valore sociale, sii aperto, sii audace. Quale valore risuona davvero con la tua squadra?
Concentrati sull’impatto. Il nostro team è relativamente snello e tuttavia abbiamo la capacità di fornire molte iniziative ad alto impatto per l’azienda.
Cos’è qualcosa che la maggior parte delle persone non sa della tua squadra?
Abbiamo un team molto diversificato composto da avvocati, responsabili delle politiche pubbliche, analisti finanziari, gestori di programmi, data scientist, professionisti dell’energia, ingegneri ed esperti di processi aziendali.
Puoi condividere sull’essere una leader femminile nel settore tecnologico e l’importanza della diversità di Facebook e Tech in generale?
Uno dei motivi per cui adoro lavorare su Facebook è il nostro impegno per la diversità. La diversità non è un’attività extracurricolare su Facebook, ma piuttosto qualcosa che miriamo a implementare a tutti i livelli dell’azienda. Anche se noi e l’industria tecnologica nel suo insieme, abbiamo più lavoro da fare qui, rafforziamo continuamente questo impegno attraverso la nostra cultura, i nostri prodotti e le nostre priorità di assunzione.
Come donna in tecnologia, so in prima persona quanto sia importante la diversità per il nostro settore e quanto le diverse prospettive guidino risultati migliori. È fondamentale che facciamo tutto il possibile per migliorare l’assunzione di diversi candidati e per incoraggiare le donne a unirsi a settori che sono in genere dominati da maschi. Ho trovato la mia carriera chiamando nella selezione del sito immobiliare, un’industria tradizionalmente dominata dagli uomini, e ho trovato la mia ispirazione attraverso le molte donne di talento che mi hanno ispirato e guidato lungo la strada. Oggi, come leader della tecnologia, è mio dovere e privilegio essere un mentore per le donne e fare il possibile per sostenere attivamente la crescita e il progresso delle donne in questo settore.
Il mio consiglio per le donne? Trova le tue passioni e seguile, anche se finisci per essere in un’area in cui tu’normalmente l’unica donna nella stanza. I tuoi punti di forza si svilupperanno attraverso le tue passioni e tu’Lavorerò di più sul tuo mestiere. La tua carriera troverà la propria traiettoria. Ancora più importante, lasciati fallire un po ‘di spazio e rialzati se inciamphi lungo la strada.
Facebook ha i propri datacenter

Facebook’S Servizi si basano su flotte di server in data center di tutto il mondo: tutti eseguendo applicazioni e offrendo le prestazioni di cui hanno bisogno i servizi di cui hanno bisogno i servizi. Questo è il motivo per cui dobbiamo assicurarci che il nostro hardware del server sia affidabile e che possiamo gestire i guasti hardware del server nella nostra scala con la minore interruzione possibile per i nostri servizi.
I componenti hardware stessi possono fallire per qualsiasi numero di motivi, incluso il degrado del materiale (E.G., I componenti meccanici di un’unità disco rigido rotante), un dispositivo utilizzato oltre il suo livello di resistenza (E.G., Dispositivi NAND FLASH), impatti ambientali (E.G., corrosione dovuta all’umidità) e difetti di produzione.
In generale, ci aspettiamo sempre un certo grado di fallimento hardware nei nostri data center, motivo per cui implementiamo sistemi come il nostro sistema di gestione dei cluster per ridurre al minimo le interruzioni del servizio. In questo articolo noi’RETRUZIONE DI QUATTRO METODOLOGIE importanti che ci aiutano a mantenere un alto grado di disponibilità hardware. Abbiamo sistemi costruiti in grado di rilevare e risolvere i problemi . Monitoriamo e rimediamo gli eventi hardware senza influire negativamente sulle prestazioni dell’applicazione . Adottiamo approcci proattivi per le riparazioni hardware e utilizziamo la metodologia di previsione per le correggezioni . E automatizziamo l’analisi delle cause alla radice per i guasti hardware e del sistema su larga scala per arrivare rapidamente alla parte inferiore dei problemi.
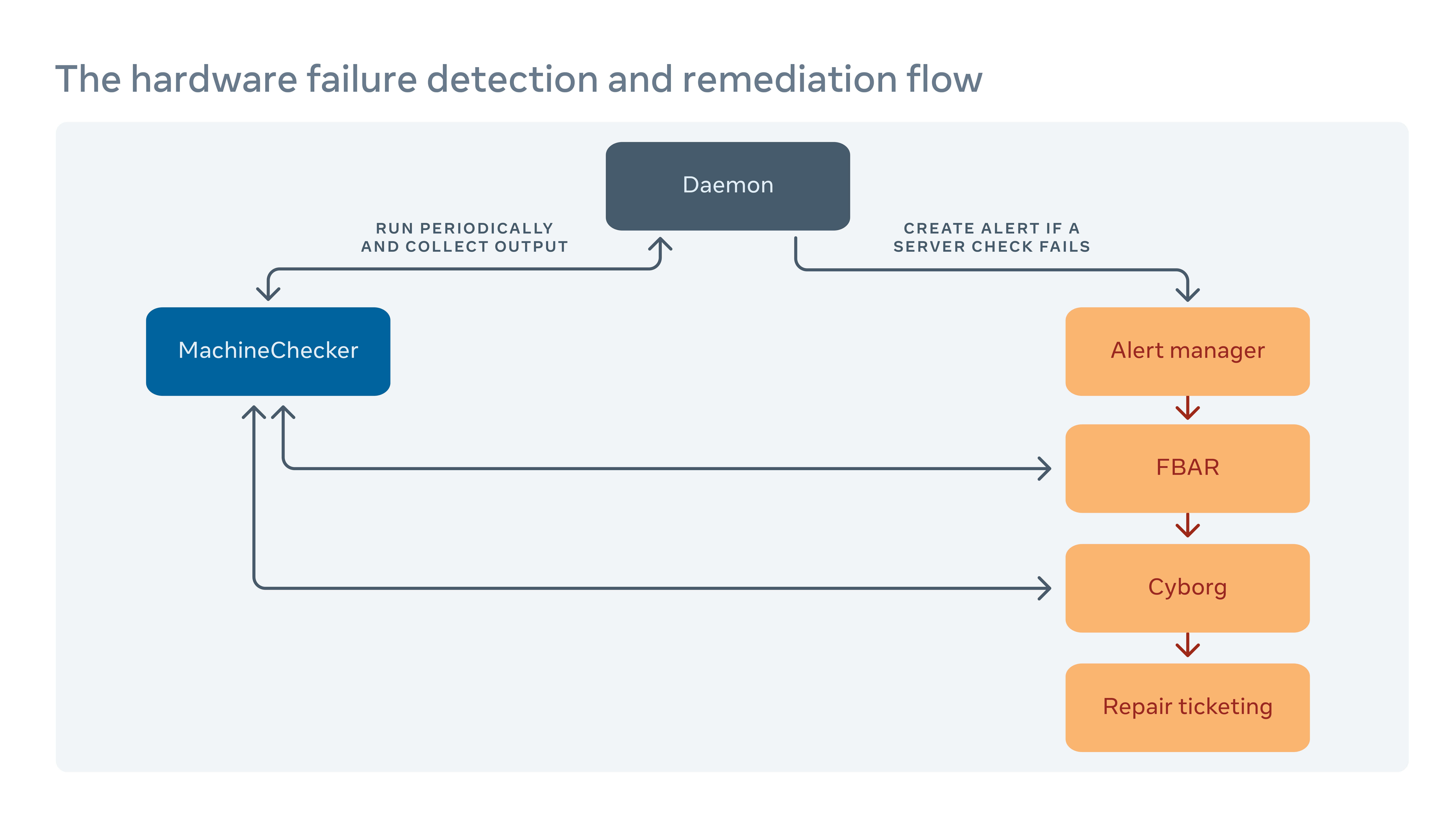
Come gestiamo la bonifica hardware
Eseguiamo periodicamente uno strumento chiamato MachineChecker su ciascun server per rilevare gli errori di hardware e connettività. Una volta che MachineChecker crea un avviso in un sistema di gestione degli avvisi centralizzati, uno strumento chiamato Facebook Auto-Remediation (FBAR), quindi raccoglie l’avviso ed esegue correzioni personalizzabili per correggere l’errore. Per assicurarti che ci sia’s ancora una capacità sufficiente per Facebook’S Servizi, possiamo anche stabilire limiti di tariffa per limitare il numero di server riparati in qualsiasi momento.
Se FBAR può’T riportare un server a uno stato sano, il fallimento viene passato a uno strumento chiamato cyborg. Il cyborg può eseguire correttive di livello inferiore come aggiornamenti del firmware o del kernel e il reimaging. Se il problema richiede una riparazione manuale da un tecnico, il sistema crea un biglietto nel nostro sistema di biglietteria per riparazioni.
Approfondiamo questo processo nel nostro documento “Risoluzione dell’hardware su larga scala.”
Come minimizziamo l’impatto negativo del reporting degli errori sulle prestazioni del server
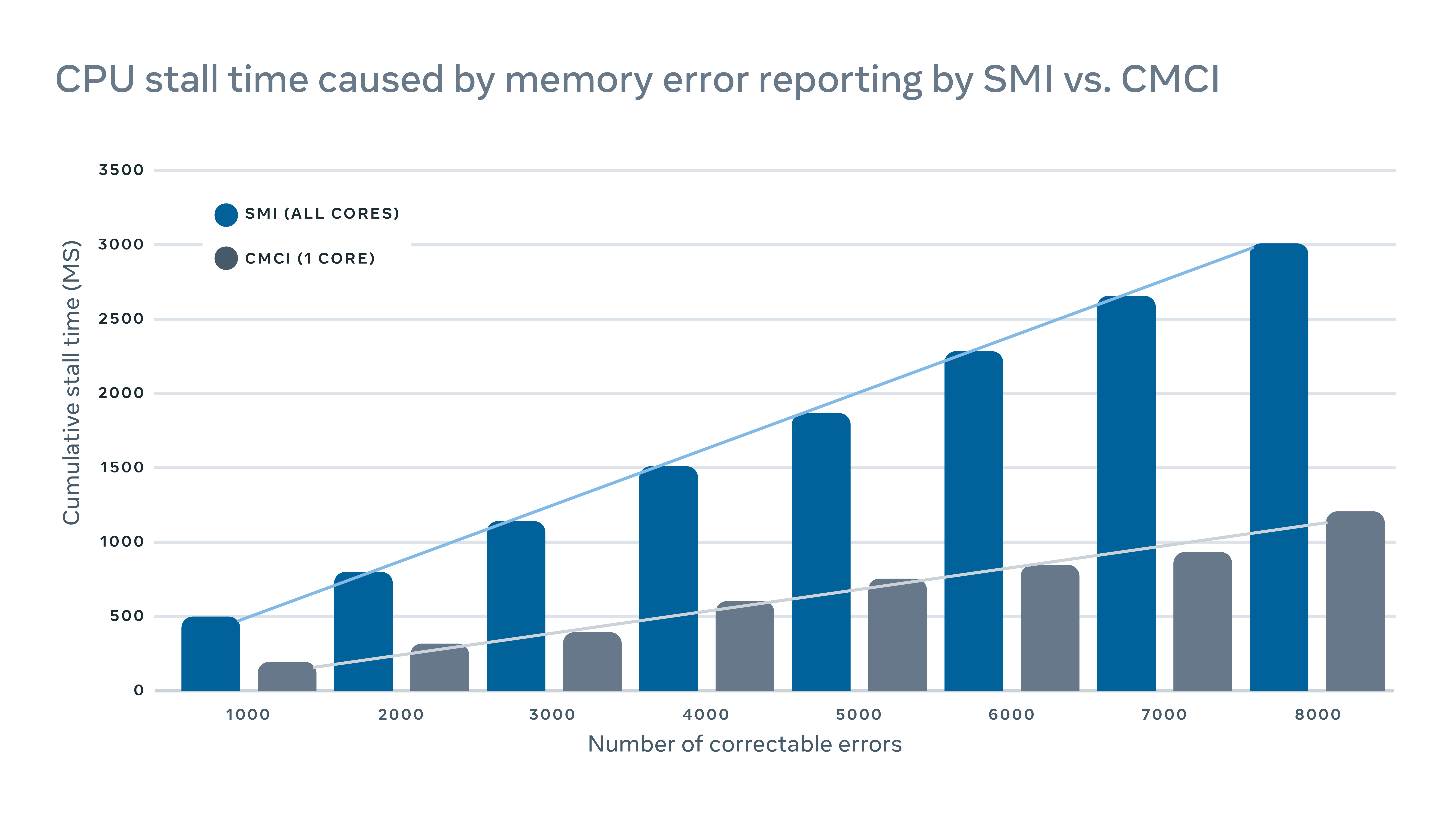
MachineChecker rileva gli errori hardware controllando vari registri dei server per i report di errore. In genere, quando si verifica un errore hardware, verrà rilevato dal sistema (E.G., fallimento di un controllo di parità) e un segnale di interrupt verrà inviato alla CPU per la gestione e la registrazione dell’errore.
Poiché questi segnali di interrupt sono considerati segnali ad alta priorità, la CPU fermerà la sua normale operazione e dedicherà la sua attenzione alla gestione dell’errore. Ma questo ha un impatto negativo sulle prestazioni sul server. Per la registrazione di errori di memoria correggibili, ad esempio, un tradizionale interrupt di gestione del sistema di interruzione (SMI) si staccarebbe tutti i core della CPU, mentre il controllo corretto del controllo della macchina (CMCI) avrebbe messo in piedi solo uno dei nuclei della CPU, lasciando il resto dei core della CPU disponibili.
Sebbene le bancarelle della CPU in genere durano solo poche centinaia di millisecondi, possono comunque interrompere i servizi sensibili alla latenza. In scala, questo significa che gli interruzioni su alcune macchine possono avere un impatto negativo a cascata sulle prestazioni a livello di servizio.
Per ridurre al minimo l’impatto sulle prestazioni causato dal report di errori, abbiamo implementato un meccanismo ibrido per il report di errori di memoria che utilizza sia CMCI che SMI senza perdere l’accuratezza in termini di numero di errori di memoria correggibili.
Come sfruttiamo l’apprendimento automatico per prevedere le riparazioni
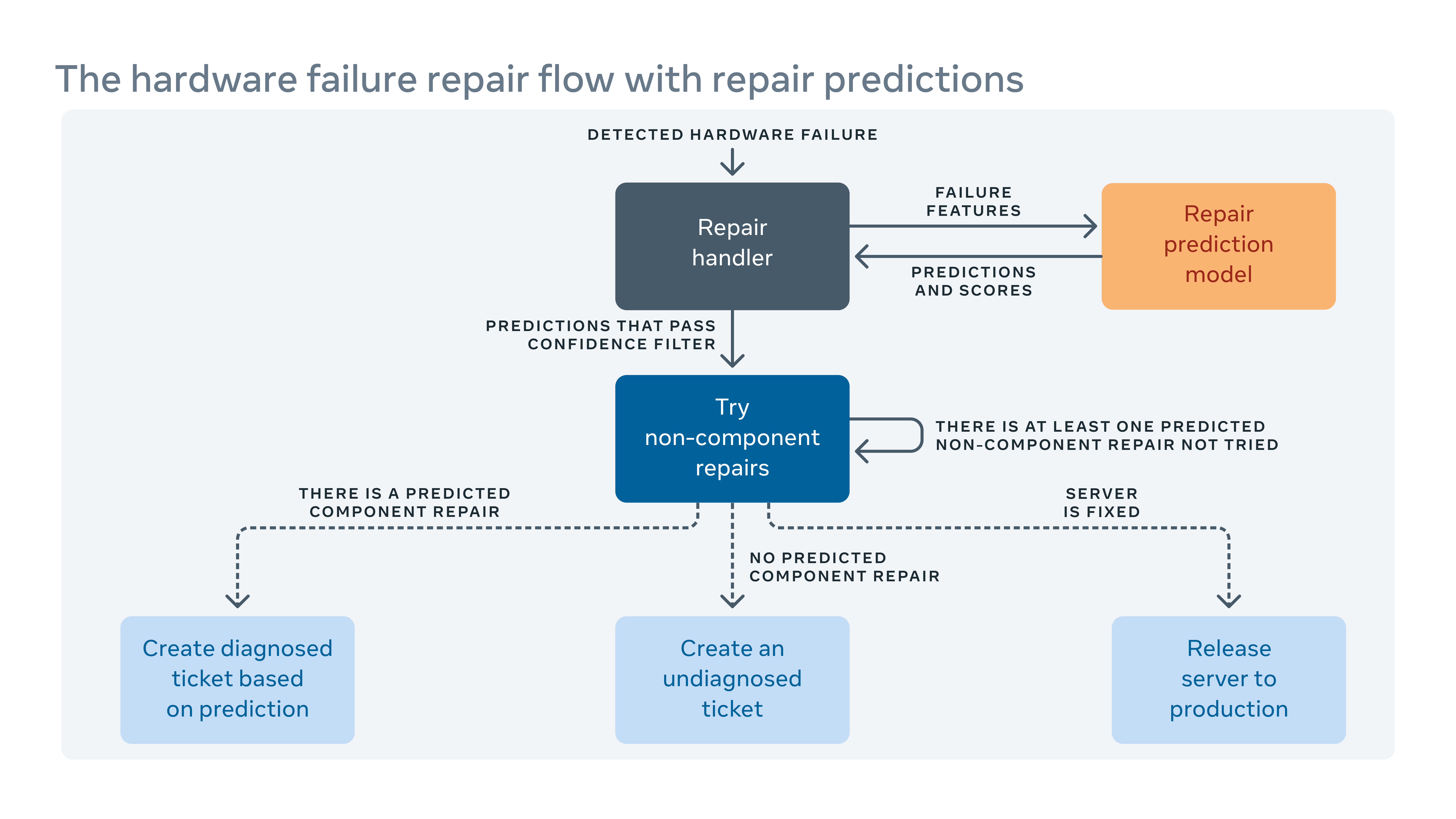
Dal momento che introduciamo spesso nuove configurazioni hardware e software nei nostri data center, dobbiamo anche creare nuove regole per il nostro sistema di remediazione automatica.
Quando il sistema automatizzato non può correggere un errore hardware, al problema viene assegnato un biglietto per la riparazione manuale. Nuovi hardware e software significano nuovi tipi di potenziali guasti che devono essere affrontati. Ma potrebbe esserci un divario tra quando vengono implementati nuovi hardware o software e quando siamo in grado di incorporare nuove regole di risanamento. Durante questo divario, alcuni biglietti per la riparazione potrebbero essere classificati come “non diagnosticato,” Significa che il sistema ha’T ha suggerito un’azione di riparazione, o “erroneamente diagnosticato,” Significa che l’azione di riparazione suggerita non è’t efficace. Ciò significa più tempo di manodopera e di sistema mentre i tecnici devono diagnosticare il problema da soli.
Per colmare il divario, abbiamo creato un framework di apprendimento automatico che apprende da come i fallimenti sono stati fissati in passato e cerca di prevedere quali riparazioni sarebbero necessarie per gli attuali biglietti per la riparazione non diagnosticati e diagnosticati errati. Sulla base del costo e del beneficio dalle previsioni errate e corrette, assegniamo una soglia sulla fiducia della previsione per ciascuna azione di riparazione e ottimizziamo l’ordine delle azioni di riparazione. Ad esempio, in alcuni casi preferiremmo provare prima un riavvio o un aggiornamento del firmware perché questo tipo di riparazioni non’T richiede qualsiasi riparazione di hardware fisico e impiegano meno tempo per finire, quindi l’algoritmo dovrebbe prima raccomandare questo tipo di azione. Chiaramente, l’apprendimento automatico ci consente non solo di prevedere come riparare un problema non diagnosticato o erroneamente diagnosticato, ma anche di dare la priorità a quelli più importanti.
Come noi’VE Analisi della causa radice a livello di flotta automatizzata
Oltre ai registri dei server che registrano riavvii, il kernel panico fuori memoria, ecc., Ci sono anche registri di software e strumenti nel nostro sistema di produzione. Ma la scala e la complessità di tutti questi significano’è difficile esaminare tutti i registri per trovare correlazioni tra loro.
Abbiamo implementato uno strumento Scalable Root-Cause-Analysis (RCA) che ordina attraverso milioni di voci di registro (ciascuna descritta da potenzialmente centinaia di colonne) per trovare correlazioni facili da capire e fruibili.
Con la pre-aggregazione dei dati che utilizzano SCUBA, un database in termini di memoria in tempo reale, abbiamo migliorato significativamente la scalabilità di un tradizionale algoritmo di mining di modelli, FP-Growth, per trovare correlazioni in questo framework RCA. Abbiamo anche aggiunto una serie di filtri sulle correlazioni riportate per migliorare l’interpretazione del risultato. Abbiamo distribuito questo analizzatore ampiamente all’interno di Facebook per il tasso di errore del componente RCCA su hardware, riavvii server imprevisti e guasti del software.
Chi ha bisogno di HP e Dell? Facebook ora progetta tutti i suoi server
Il nuovo data center di Facebook non avrà server OEM.
Jon Brodkin – 14 febbraio 2013 22:35 UTC

Commenti dei lettori
Quasi due anni fa, Facebook ha svelato quello che ha chiamato Open Compute Project. L’idea era di condividere progetti per hardware del data center come server, archiviazione e rack in modo che le aziende potessero costruire le proprie attrezzature invece di fare affidamento sulle opzioni strette fornite dai fornitori di hardware.
Mentre chiunque potesse beneficiare, Facebook ha aperto la strada a distribuire l’hardware su misura nei propri data center. Il progetto è ora avanzato fino al punto in cui tutti i nuovi server distribuiti da Facebook sono stati progettati da Facebook stesso o progettati da altri sulle specifiche impegnative di Facebook. Attrezzatura personalizzata oggi occupa più della metà dell’attrezzatura nei data center di Facebook. Successivamente, Facebook aprirà un data center di 290.000 piedi quadrati in Svezia fornita interamente con server del proprio design, un primo per l’azienda.
“È il primo in cui avremo i server di calcolo aperti al 100 % all’interno”, ha detto a ARS Frankovsky, vicepresidente della progettazione hardware e delle operazioni della catena di approvvigionamento su Facebook.
Come i data center esistenti di Facebook in North Carolina e Oregon, quello che arriverà online quest’estate a Luleå, la Svezia, avrà decine di migliaia di server. Facebook mette inoltre la propria attrezzatura nello spazio del data center in affitto per mantenere una presenza vicino agli utenti di tutto il mondo, anche in 11 siti di colocation negli Stati Uniti. Vari fattori contribuiscono alla scelta delle posizioni: tasse, lavoro tecnico disponibili, fonte e costo del potere e clima. Facebook non utilizza l’aria condizionata tradizionale, invece basandosi completamente su “Air esterno e un unico sistema di raffreddamento evaporativo per mantenere i nostri server abbastanza freschi”, ha detto Frankovsky.
Risparmiando denaro eliminando ciò che non’b ha bisogno
In scala di Facebook, è più economico mantenere i propri data center piuttosto che fare affidamento sui fornitori di servizi cloud, ha osservato. Inoltre, è anche più economico per Facebook evitare i tradizionali fornitori di server.
Come Google, Facebook progetta i propri server e li ha costruiti da ODM (produttori di design originale) a Taiwan e in Cina, piuttosto che OEM (produttori di apparecchiature originali) come HP o Dell. Rotolando il proprio, Facebook elimina ciò che Frankovsky chiama “differenziazione gratuita”, funzionalità hardware che rendono i server unici ma non beneficiano di Facebook.
Potrebbe essere semplice come la cornice di plastica su un server con un logo del marchio, perché quel bit di materiale extra costringe i fan a lavorare di più. Frankovsky ha detto che uno studio ha mostrato uno standard di OEM di dimensioni 1U “ha usato 28 watt di potenza della ventola per tirare l’aria attraverso l’impedenza causata da quella cornice di plastica”, mentre il server di calcolo aperto equivalente ha usato solo tre watt a tale scopo.

Cos’altro si spoglia Facebook? Frankovsky ha detto che “molte schede madri oggi arrivano con un sacco di management Goop. Questo è il termine tecnico che mi piace usare per questo.”Questo goop potrebbe essere il motore di gestione del ciclo di vita integrato di HP o gli strumenti di gestione del server remoto di Dell.
Queste caratteristiche potrebbero essere utili a molti clienti, in particolare se hanno standardizzato su un fornitore. Ma alle dimensioni di Facebook, non ha senso fare affidamento su un solo fornitore, perché “un difetto del design potrebbe prendere una grande parte della tua flotta o perché una parte di carenza di parte potrebbe fare la tua capacità di fornire prodotti ai tuoi data center.”
Facebook ha i propri strumenti di gestione dei data center, quindi la roba che HP o Dell produce non è necessaria. Un prodotto di fornitore “viene fornito con il proprio set di interfacce utente, set di API e una bella GUI per dirti quanto stanno girando i fan veloci e alcune cose che in generale la maggior parte dei clienti distribuisce queste cose su larga visione come differenziazione gratuita”, ha detto Frankovsky. “È diverso in un modo che non importa per me. Quella strumentazione extra sulla scheda madre, non solo costa denaro per acquistarla dal punto di vista dei materiali, ma provoca anche complessità nelle operazioni.”
Un percorso per HP e Dell: Adatta a Open Calco
Ciò non significa che Facebook sta giurando da HP e Dell per sempre. “La maggior parte della nostra nuova attrezzatura è costruita da ODM come Quanta”, ha detto la società in una risposta e-mail a una delle nostre domande di follow-up. “Facciamo multi-source tutta la nostra attrezzatura e se un OEM può costruire ai nostri standard e portarlo entro il 5 percento, allora sono di solito in quelle discussioni multi-source.”
HP e Dell hanno iniziato a realizzare progetti conformi ad aprire le specifiche di calcolo e Facebook ha detto che sta testando uno da HP per vedere se può effettuare il taglio. La società ha confermato, tuttavia, che il suo nuovo data center in Svezia non includerà alcun server OEM quando si apre.
Facebook afferma che ottiene un risparmio finanziario del 24 % dall’avere un’infrastruttura a basso costo e risparmia il 38 % nei costi operativi in corso a seguito della costruzione delle proprie cose. I server personalizzati di Facebook non eseguono carichi di lavoro diversi rispetto a qualsiasi altro server, li eseguono semplicemente in modo più efficiente.
“Un server HP o Dell o Apri Server Calco. “È solo una questione di quanto lavoro hai fatto per watt per dollaro.”
Facebook non virtualizza i suoi server, perché il suo software consuma già tutte le risorse hardware, il che significa che la virtualizzazione comporterebbe una penalità per le prestazioni senza un guadagno di efficienza.
Il gigante dei social media ha pubblicato i progetti e le specifiche dei propri server, schede madri e altre attrezzature. Ad esempio, la scheda madre “Windmill” utilizza due processori Intel Xeon E5-2600, con un massimo di otto core per CPU.
Il foglio delle specifiche di Facebook lo scompone:
- 2 Processori della serie Intel® Xeon® E5-2600 (LGA2011) fino a 115W
- 2 INTLETCONNECT Intel a larghezza intera QuickPath (QPI) collega fino a 8 GT/S/Direction
- Fino a 8 core per CPU (fino a 16 thread con tecnologia iper-threading)
- Cache dell’ultimo livello fino a 20 MB
- Modalità processore singolo
- DDR3 Supporto di memoria allegata diretta su CPU0 e CPU1 con:
- Interfaccia di memoria registrata DDR3 a 4 canali su processori 0 e 1
- 2 slot DDR3 per canale per processore (totale di 16 dimm sulla scheda madre)
- RDIMM/LV-RDIMM (1.5V/1.35V), LRDIMM e ECC UDIMM/LV-UDIMM (1.5V/1.35v)
- Dimm di rango singolo, doppio e quad
- Velocità DDR3 di 800/1066/1333/1600 MHz
- Memoria al massimo 512 GB con Dimm RDIMM da 32 GB
E ora un diagramma della scheda madre:
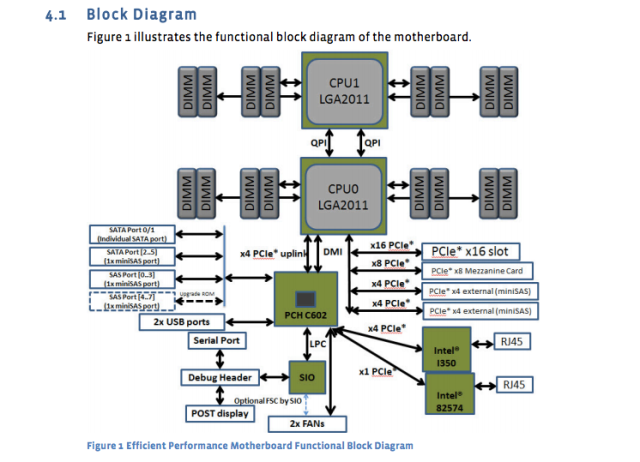
Quelle specifiche della scheda madre sono state pubblicate quasi un anno fa, ma sono ancora lo standard. Il server di database di nuova progettazione “Dragonstone” e Web Server “Winterfell” si basano sulla scheda madre del mulino Wind, sebbene le nuove CPU Intel potrebbero colpire la produzione su Facebook entro la fine dell’anno.

I design dei server di Facebook sono adattati a diverse attività. Come riportato il Timothy Prickett Morgan del registro, alcune funzioni di database su Facebook richiedono alimentatori ridondanti, mentre altre attività possono essere gestite dai server con più nodi di calcolo che condividono una singola alimentazione.
I data center utilizzano un mix di archiviazione flash e dischi di rotazione tradizionali, con Flash che serve funzionalità Facebook che richiedono le velocità disponibili più rapide. I server di database utilizzano tutto il flash. I server Web in genere hanno CPU molto veloci, con quantità relativamente basse di archiviazione e RAM. 16 GB è una quantità tipica di RAM, ha detto Frankovsky. I chip Intel e AMD hanno entrambi una presenza su Facebook Gear.
E Facebook è gravato da un sacco di “cella frigorifero”, le cose scritte una volta e raramente si accedono. Anche lì, Frankovsky vuole usare sempre più il flash a causa del tasso di fallimento dei dischi rotanti. Con decine di migliaia di dispositivi in funzione, “Non vogliamo che i tecnici che corrono in giro sostituiscono i dischi rigidi”, ha detto.
Il flash di classe Data Center è in genere molto più costoso dei dischi di rotazione, ma Frankovsky afferma che potrebbe esserci un modo per valere la pena. “Se si utilizza la classe di NAND [flash] nelle unità del pollice, che in genere è considerata spazzando o scart NAND, e usi un tipo di controller davvero interessante per caratterizzare quali celle sono buone e quali celle non lo sono, potresti potenzialmente costruire una soluzione di conservazione a freddo davvero ad alte prestazioni”, ha detto.
Portare la flessibilità del data center all’estremo
Frankovsky vuole design così flessibili che i singoli componenti possono essere scambiati in risposta al cambiamento della domanda. Uno sforzo lungo quella linea è il nuovo “abbraccio di gruppo” di Facebook per le schede madri, che potrebbero ospitare i processori di numerosi fornitori. AMD e Intel, nonché i fornitori di chip ARM applicati Micro e Calxeda, si sono già impegnati a supportare queste schede con nuovi prodotti SOC (System on Chip).
Quello è stato uno dei numerosi articoli di notizie che sono usciti dal vertice Open Compute Open del mese scorso a Santa Clara, CA. In totale, gli annunci indicano un futuro in cui i clienti possono “aggiornare attraverso più generazioni di processori senza dover sostituire le schede madri o la rete in rack”, ha osservato Frankovsky in un post sul blog.
Calxeda ha inventato una scheda server basata su ARM in grado di scivolare nel sistema di archiviazione di Vault Open di Facebook, in codice “Knox.”” Trasforma il dispositivo di archiviazione in un server di archiviazione ed elimina la necessità di un server separato per controllare il disco rigido “, ha detto Frankovsky. (Facebook non usa i server ARM oggi perché richiede supporto a 64 bit, ma Frankovsky afferma che “le cose stanno diventando interessanti” nella tecnologia ARM.)
Intel ha anche contribuito con progetti per una prossima tecnologia di fotonica del silicio che consentirà interconnessioni da 100 Gbps, 10 volte più velocemente delle connessioni Ethernet che Facebook utilizza oggi nei suoi data center. Con la bassa latenza abilitata da quel tipo di velocità, i clienti potrebbero essere in grado di separare le CPU, la DRAM e l’archiviazione in diverse parti del rack e aggiungere o sottrarre i componenti anziché interi server quando necessario, Frankovsky ha detto. In questo scenario, più host potrebbero condividere un sistema flash, migliorando l’efficienza.
Nonostante tutti questi disegni personalizzati provenienti da fuori dal mondo OEM, HP e Dell non vengono completamente lasciati alle spalle. Si sono adattati per cercare di catturare alcuni clienti che desiderano la flessibilità dei progetti di calcolo aperto. Un dirigente di Dell ha consegnato una delle note chiave al vertice Open Compute Open di quest’anno, e sia HP che Dell l’anno scorso hanno annunciato “Design Clean-Sheet Server e Archivia.
Oltre ad essere bravo per Facebook, Frankovsky spera che Open Compute andrà a beneficio dei clienti del server in generale. Fidelity e Goldman Sachs sono tra quelli che utilizzano design personalizzati sintonizzati sui loro carichi di lavoro a seguito di un calcolo aperto. Anche i clienti più piccoli potrebbero essere in grado di beneficiare. Potrebbero “prendere blocchi [di Open Caltal] e ristrutturare in progetti fisici che si adattano alle loro slot di server”, ha detto Frankovsky.
“L’industria sta spostando e cambia in modo positivo, a favore dei consumatori, a causa del calcolo aperto”, ha detto.