


Facebook usa MongoDB?
Facebook -134mg1q -webkit-align-se stesso: centrale-ms-flex-item-align: centro; allineare: centro; imbottitura: 0 10px; Visibilità: nascosto;. CSS-6VRLZM Border-RADIUS: 0! importante; Visualizza: iniziale! importante; Margine: iniziale! importante;. CSS-1L4S55V MARGIN-TOP-175PX; Posizione: assoluto; imbottitura-bottom: 2px;
Vedi Imposta un’app Facebook per informazioni sull’impostazione della tua app di Facebook e sulla ricerca del segreto dell’app.
Facebook usa MongoDB?
Об этой сттце
Ыы зарегистрировали подозритеstituire. С помощю ээй ст р ы ыы сможем о imperceде quello. Почему ээо мо л поззти?
Эта страница отображается в тех с лччч, когда автоматическиtal систе quisi которые наршают условия иполззования. Страница перестан scegliere. До этого момента для иполззования сжж google необходимо пхоходить поверку по по по по по.
” ылку запросов. Если ы и ипоеете общий доступ в интернет, проmma. Обратитесь к с ое системому администратору. Подробнеi.
Проверка по слову может также появляться, если вы вводите сложные запросы, обычно распространяемые автоматизированными системами, или же вводите запросы очень часто.
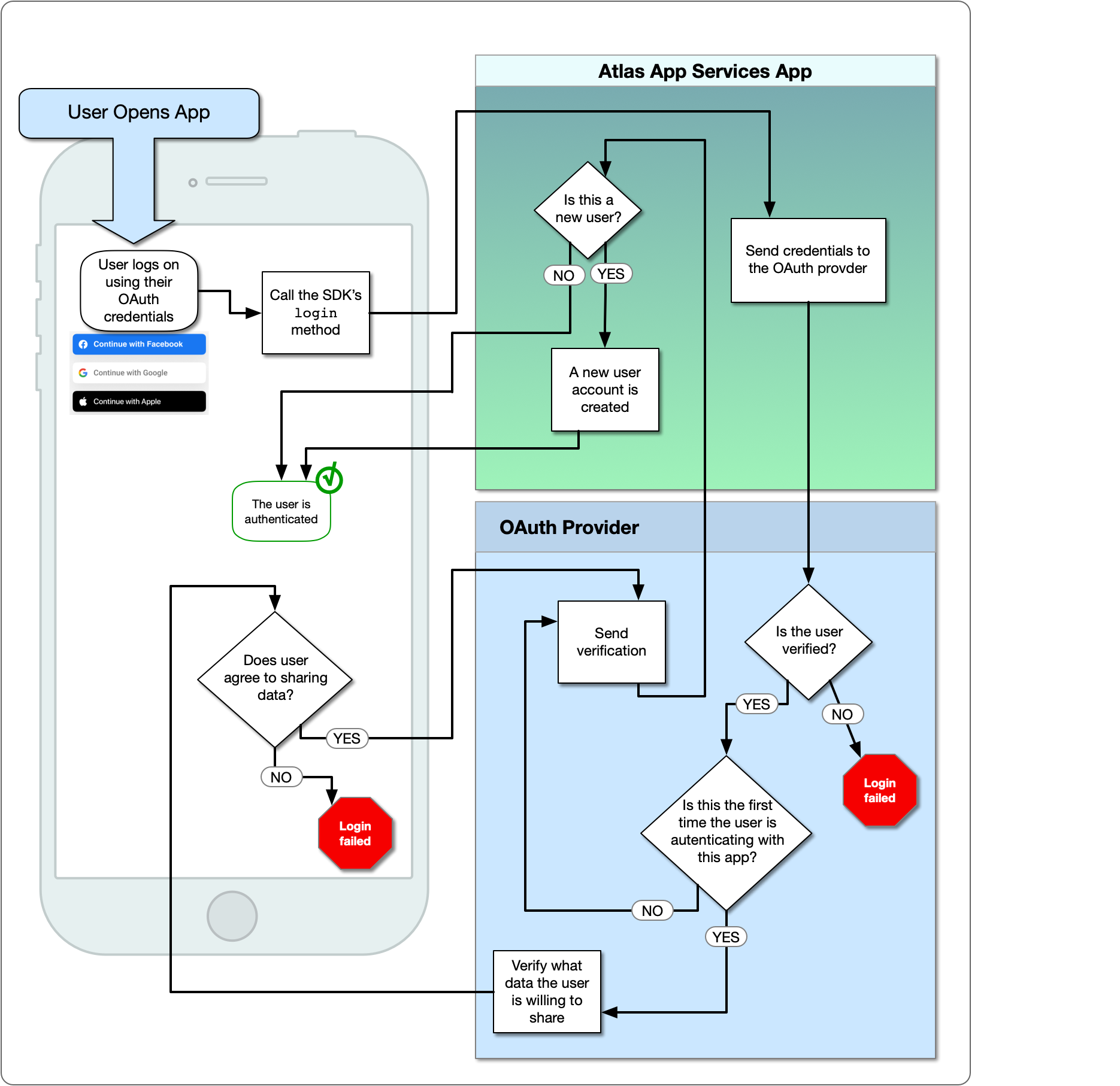
Autenticazione di Facebook
Il provider di autenticazione di Facebook consente agli utenti di accedere con il proprio account Facebook esistente tramite un’applicazione Facebook di accompagnamento. Quando un utente accede, Facebook fornisce servizi di app Atlas con OAuth 2.0 token di accesso per l’utente. App Services utilizza il token per identificare l’utente e l’accesso ai dati approvati dall’API di Facebook per loro conto. Per ulteriori informazioni sul login di Facebook, consultare l’accesso a Facebook per le app.
Il seguente diagramma mostra il flusso logico OAuth:
Configurazione
Il provider di autenticazione di Facebook ha le seguenti opzioni di configurazione:
Descrizione
configurazione.Identificativo cliente
Necessario. L’ID app dell’app Facebook.
Vedi Imposta un’app Facebook per informazioni sull’impostazione della tua app di Facebook e sulla ricerca dell’ID dell’app.
Segreto del cliente
Secret_config.CustomerCret
Necessario. Il nome di un segreto che memorizza l’app segreta dell’app Facebook.
Vedi Imposta un’app Facebook per informazioni sull’impostazione della tua app di Facebook e sulla ricerca del segreto dell’app.
Campi di metadati
metadata_fields
Opzionale. Un elenco di campi che descrivono l’utente autenticato che l’applicazione richiederà dall’API del grafico di Facebook.
Tutti i campi di metadati sono omessi per impostazione predefinita e possono essere richiesti su base per campo per campo. Gli utenti devono concedere esplicitamente l’autorizzazione dell’app per accedere a ciascun campo richiesto. Se è richiesto un campo di metadati ed esiste per un determinato utente, sarà incluso nel proprio oggetto utente.
Per richiedere un campo di metadati da un file di configurazione di importazione/esportazione, aggiungi una voce per il campo all’array Metadata_Fields. Ogni voce dovrebbe essere un documento del seguente modulo:
"" , ""
Database utente di Facebook: è SQL o NOSQL?
Mai chiesto quale database usa Facebook (FB) per archiviare i profili dei suoi 2.3b+ utenti? È SQL o NOSQL? Come si è evoluta l’architettura del database FB negli ultimi 15 anni? Come ingegnere nel team di infrastrutture del database FB dal 2007 al 2013, ho avuto un posto in prima fila per assistere a questa evoluzione. Ci sono lezioni inestimabili da apprendere comprendendo meglio l’evoluzione del database sul più grande social network del mondo, anche se la maggior parte di noi non affronterà esattamente le stesse sfide nel prossimo futuro. Questo perché i principi fondamentali alla base dell’architettura su scala Internet di FB oggi si applicano oggi a molte app aziendali aziendali-critical.
Architettura iniziale
Come qualsiasi utente FB può facilmente comprendere, il suo profilo non è semplicemente un elenco di attributi come nome, e -mail, interessi e così via. È in effetti un ricco grafico sociale che memorizza tutte le relazioni, gruppi, check-in, mi piace, condivisioni e altro ancora amici/familiari. Data la flessibilità di modellazione dei dati di SQL e l’ubiquità di MySQL quando è iniziata FB, questo grafico sociale è stato inizialmente creato come un’applicazione PHP alimentata da MySQL come database persistente e memcache come cache “Lookaside”.
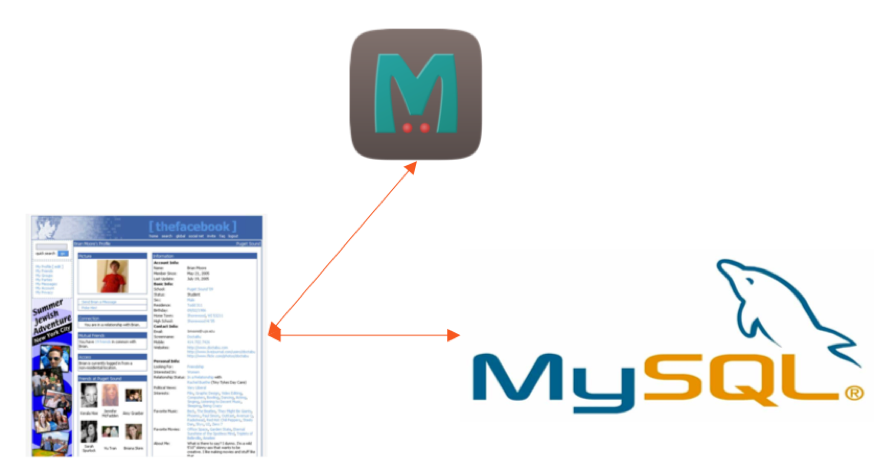
Architettura di database originale di Facebook
Nel modello di memorizzazione nella cache LookAside, l’applicazione prima richiede i dati dalla cache anziché dal database. Se i dati non vengono memorizzati nella cache, l’applicazione ottiene i dati dal database di supporto e li inserisce nella cache per le letture successive. Si noti che l’applicazione PHP accedeva direttamente a MySQL e Memcache senza alcun livello di astrazione dei dati intermedi.
Dolori crescenti
Perdita di agilità degli sviluppatori
Gli ingegneri dovevano lavorare con due negozi di dati con due modelli di dati molto diversi: una grande raccolta di MySQL
Facebook -134mg1q -webkit-align-se stesso: centrale-ms-flex-item-align: centro; allineare: centro; imbottitura: 0 10px; Visibilità: nascosto;. CSS-6VRLZM Border-RADIUS: 0! importante; Visualizza: iniziale! importante; Margine: iniziale! importante;. CSS-1L4S55V MARGIN-TOP-175PX; Posizione: assoluto; imbottitura-bottom: 2px;
Vedi Imposta un’app Facebook per informazioni sull’impostazione della tua app di Facebook e sulla ricerca del segreto dell’app .
Facebook usa MongoDB?
Об этой сттце
Ыы зарегистрировали подозритеstituire. С помощю ээй ст р ы ыы сможем о imperceде quello. Почему ээо мо л поззти?
Эта страница отображается в тех с лччч, когда автоматическиtal систе quisi которые наршают условия иполззования. Страница перестан scegliere. До этого момента для иполззования сжж google необходимо пхоходить поверку по по по по по.
” ылку запросов. Если ы и ипоеете общий доступ в интернет, проmma. Обратитесь к с ое системому администратору. Подробнеi.
Проверка по слову может также появляться, если вы вводите сложные запросы, обычно распространяемые автоматизированными системами, или же вводите запросы очень часто.
Autenticazione di Facebook
Il provider di autenticazione di Facebook consente agli utenti di accedere con il proprio account Facebook esistente tramite un’applicazione Facebook di accompagnamento. Quando un utente accede, Facebook fornisce servizi di app Atlas con OAuth 2.0 token di accesso
per l’utente. App Services utilizza il token per identificare l’utente e l’accesso ai dati approvati dall’API di Facebook per loro conto. Per ulteriori informazioni sul login di Facebook, consultare l’accesso a Facebook per le app
Il seguente diagramma mostra il flusso logico OAuth:
Configurazione
Il provider di autenticazione di Facebook ha le seguenti opzioni di configurazione:
Descrizione
configurazione.Identificativo cliente
Necessario. L’ID app dell’app Facebook.
Vedi Imposta un’app Facebook per informazioni sull’impostazione della tua app di Facebook e sulla ricerca dell’ID dell’app .
Segreto del cliente
Secret_config.CustomerCret
Necessario. Il nome di un segreto che memorizza l’app segreta dell’app Facebook.
Vedi Imposta un’app Facebook per informazioni sull’impostazione della tua app di Facebook e sulla ricerca del segreto dell’app .
Campi di metadati
metadata_fields
Opzionale. Un elenco di campi che descrivono l’utente autenticato che l’applicazione richiederà dall’API del grafico di Facebook .
Tutti i campi di metadati sono omessi per impostazione predefinita e possono essere richiesti su base per campo per campo. Gli utenti devono concedere esplicitamente l’autorizzazione dell’app per accedere a ciascun campo richiesto. Se è richiesto un campo di metadati ed esiste per un determinato utente, sarà incluso nel proprio oggetto utente.
Per richiedere un campo di metadati da un file di configurazione di importazione/esportazione, aggiungi una voce per il campo all’array Metadata_Fields. Ogni voce dovrebbe essere un documento del seguente modulo:
< nome: "", necessario: "" >
Facebook’S Database utente: è SQL o NOSQL?
Mai chiesto quale database usa Facebook (FB) per archiviare i profili dei suoi 2.3b+ utenti? È SQL o NOSQL? Come si è evoluta l’architettura del database FB negli ultimi 15 anni? Come ingegnere nel team di infrastrutture del database FB dal 2007 al 2013, ho avuto un posto in prima fila per assistere a questa evoluzione. Ci sono lezioni inestimabili da apprendere comprendendo meglio l’evoluzione del database nel mondo’S più grande social network, anche se la maggior parte di noi ha vinto’Afferrare esattamente le stesse sfide nel prossimo futuro. Questo perché i principi fondamentali che sono alla base di FB’L’architettura su scala Internet, distribuita a livello globale si applica oggi a molte app aziendali aziendali-critiche come SaaS multi-tenant, catalogo/checkout dei prodotti al dettaglio, prenotazioni di viaggi e classifiche di gioco.
Architettura iniziale
Come qualsiasi utente FB può facilmente comprendere, il suo profilo non è semplicemente un elenco di attributi come nome, e -mail, interessi e così via. È in effetti un ricco grafico sociale che memorizza tutte le relazioni, gruppi, check-in, mi piace, condivisioni e altro ancora amici/familiari. Data la flessibilità di modellazione dei dati di SQL e l’ubiquità di MySQL all’avvio di FB, questo grafico sociale è stato inizialmente creato come applicazione PHP alimentata da MySQL come database persistente e memcache come a “guardare oltre” cache.
Facebook’S Architettura di database originale
Nel modello di memorizzazione nella cache LookAside, l’applicazione prima richiede i dati dalla cache anziché dal database. Se i dati non vengono memorizzati nella cache, l’applicazione ottiene i dati dal database di supporto e li inserisce nella cache per le letture successive. Si noti che l’applicazione PHP accedeva direttamente a MySQL e Memcache senza alcun livello di astrazione dei dati intermedi.
Dolori crescenti
Fb’Il successo meteorico dal 2005 in poi ha messo a dura prova l’architettura del database semplicistico evidenziata nella sezione precedente. Seguendo alcuni dei dolori in crescita, gli ingegneri FB dovevano risolvere in un breve periodo di tempo.
Perdita di agilità degli sviluppatori
Gli ingegneri dovevano lavorare con due negozi di dati con due modelli di dati molto diversi: una vasta raccolta di coppie MySQL Master-Slave per archiviare i dati in modo persistente nelle tabelle relazionali e una altrettanto grande raccolta di server Memcache per archiviare e servire coppie a valore chiave piane. Lavorare con il livello del database ora è obbligatorio per prima acquisire una complessa conoscenza di come i due negozi hanno funzionato in combinazione tra loro. Il risultato netto è stato perdita nell’agilità degli sviluppatori.
Famardo del database a livello di applicazione
L’incapacità di MySQL di ridimensionare le richieste di scrittura oltre un nodo è diventata un problema killer quando i volumi dei dati sono cresciuti a passi da gigante. Mysql’L’architettura monolitica S essenzialmente forzata a livello di applicazione che si shard molto presto. Ciò significava che l’applicazione ora monitorava quale istanza MySQL è responsabile della memorizzazione di quale utente’profilo s. Lo sviluppo e la complessità operativa crescono esponenzialmente quando il numero di tali istanze cresce da 1 a 100 e successivamente esplodono in 1000. Si noti che l’adesione a tale architettura significava che l’applicazione non utilizza più il database per eseguire eventuali giunti e transazioni, rinunciando così alla piena potenza di SQL (come linguaggio di query flessibile) per scalare in orizzontale.
Replicazione multfatacenter, geo-ridondante
La gestione dei guasti del datacenter è diventato anche una preoccupazione fondamentale che significava archiviare gli schiavi MySQL (e le corrispondenti istanze di Memcache) in più data center geo-ridondanti. Perfecting and Operations Failovers non è stato un’impresa facile in sé, ma data la replica asincrona di Master-Slave, i dati recentemente impegnati sarebbero ancora scomparsi ogni volta che veniva intrapreso tale failover.
Perdita di coerenza tra cache e db
La memcache di fronte a uno schiavo mysql regionale remota non può servire immediatamente letture coerenti fortemente (aka read-after-write) a causa della replicazione asincrona tra il maestro e lo schiavo. E le letture stantii risultanti nella regione remota possono facilmente portare a utenti confusi. E.G. Una richiesta di amicizia può presentarsi come accettato a un amico mentre si presenta come ancora in attesa all’altro.
Immettere tao, un’API grafica NoSQL su SHARDED SQL
All’inizio del 2009 FB ha iniziato a costruire TAO, un’API grafica NOSQL specifica per FB costruita per funzionare su Mysql sharded. L’obiettivo era risolvere i problemi evidenziati nella sezione precedente. Tao sta per “Le associazioni e gli oggetti”. Anche se il design per TAO è stato pubblicato per la prima volta come documento nel 2013, l’implementazione per TAO non è mai stata aperta data la natura proprietaria del grafico sociale FB.
Tao rappresentava elementi di dati come nodi (oggetti) e relazioni tra loro come bordi (associazioni). Gli sviluppatori di applicazioni FB adoravano l’API perché ora potevano facilmente gestire gli aggiornamenti e le domande del database necessarie per la loro logica dell’applicazione senza alcuna conoscenza diretta di MySQL o persino Memcache.
Architettura
Come mostrato nella figura seguente, Tao ha essenzialmente convertito FB’s 1000 esistenti di coppie di master-slave MySQL con proiezione manualmente a un cluster di database altamente scalabile, con ardori automatico e geo-distribuito. Tutti gli oggetti e le associazioni nello stesso frammento sono conservati in modo persistente nella stessa istanza MySQL e sono memorizzati nella cache sullo stesso set di server in ciascun cluster di memorizzazione nella cache. Il posizionamento di singoli oggetti e associazioni può essere diretto a frammenti specifici al momento della creazione quando necessario. Il controllo del grado di collocazione dei dati si è rivelato un’importante tecnica di ottimizzazione per fornire accesso ai dati a bassa latenza.
I modelli di accesso basati su SQL come le transazioni di acido e i join trasversali sono stati vietati in TAO come mezzo per preservare così tali garanzie di latenza a bassa latenza. Tuttavia, ha supportato le scritture a due precedenti non atomiche nel contesto di un aggiornamento dell’associazione (i cui due oggetti possono essere in due diversi frammenti). In caso di guasti dopo un aggiornamento del frammento ma prima del secondo aggiornamento del frammento, un lavoro di riparazione asincrono pulirebbe il “sospeso” Associazione in un secondo momento.
I frammenti possono essere migrati o clonati su un server diverso nello stesso cluster per bilanciare il carico e levigare i picchi di carico. I picchi di carico erano comuni e si verificano quando una manciata di oggetti o associazioni diventa estremamente popolare in quanto appaiono nei feed di notizie di decine di milioni di utenti contemporaneamente.
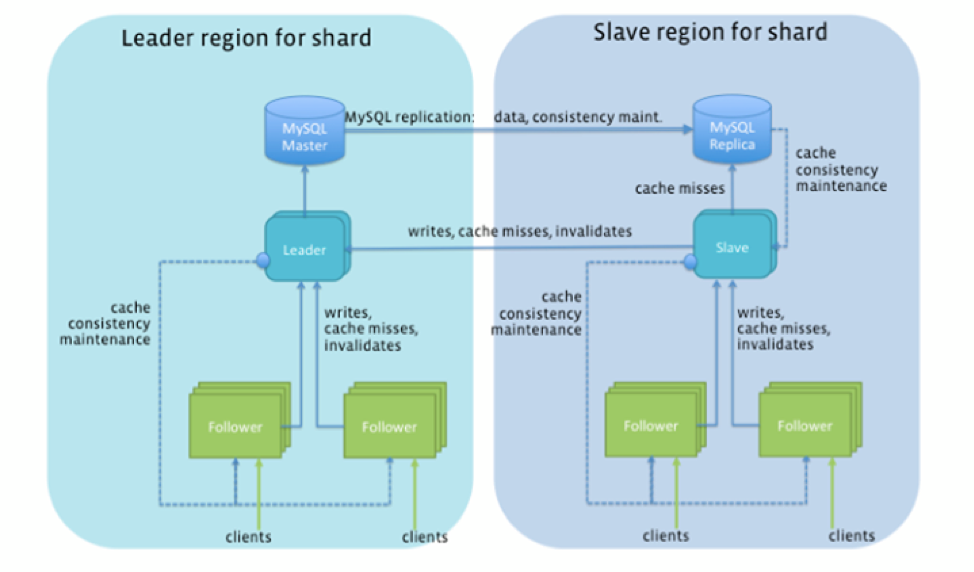
Esiste una soluzione aziendale per scopi generici?
FB non aveva altra scelta che ridimensionare in modo massiccio il livello di database MySQL responsabile del suo utente’S social grafico. Né Mysql né gli altri database SQL disponibili in quel momento potrebbero risolvere questo problema da soli. Quindi, FB ha utilizzato la sua significativa potenza ingegneristica per creare essenzialmente un livello di query di database personalizzato che ha astratto i database MySQL frammenti sottostanti. In tal modo, ha costretto i suoi sviluppatori a rinunciare completamente a SQL come API di query flessibile e adottare Tao’s personalizzato NOSQL API.
La maggior parte di noi nel mondo aziendale non ha problemi su scala di Facebook, ma comunque vogliono ridimensionare i database SQL su richiesta. Adoriamo SQL per la sua flessibilità e ubiquità, il che significa che vogliamo ridimensionare senza rinunciare a SQL. Esiste una soluzione generale per le aziende come noi? La risposta è si!
Ciao SQL distribuito!
I database monolitici SQL hanno cercato di distribuire da oltre 10 anni per risolvere il problema di ridimensionamento orizzontale. COME “Aumento di database SQL distribuiti a livello globale” Highlights, la prima ondata di tali database è stata chiamata Newsql e includevano database come Clussox, NuodB, Citus e Vitess. Questi hanno avuto un successo limitato nello spostamento di database SQL ridotti manualmente. Il motivo è che il nuovo valore creato non è sufficiente per semplificare radicalmente lo sviluppatore e l’esperienza delle operazioni. CLUSTRIX e NUODB MANDATE INFRASTRUTTURE DATICENTE SPECIAZIONE, ALTENTE ASSERITARI. Citus e Vitess semplificano l’esperienza operativa in una certa misura ponendo automatico il database ma quindi handicap lo sviluppatore non dandogli un singolo database SQL distribuito logico.
Siamo ora nella seconda generazione di database SQL distribuiti in cui la scalabilità enorme e la distribuzione globale dei dati sono integrate nel livello del database rispetto a 10 anni fa quando Facebook ha dovuto creare queste funzionalità nel livello dell’applicazione.
Ispirato da Google Spanner
Mentre FB stava costruendo TAO, Google stava costruendo Spanner, un database completamente nuovo a livello globale per risolvere sfide molto simili. Spanner’Il modello di dati S era meno di un grafico sociale ma più di un carico di lavoro OLTP tradizionale ad accesso casuale che gestisce Google’S utenti, organizzazioni clienti, crediti AdWords, preferenze Gmail e altro ancora. Spanner è stato introdotto per la prima volta nel mondo sotto forma di un documento di design nel 2012. È iniziato nel 2007 come negozio di valore chiave transazionale ma poi si è evoluto in un database SQL. Il passaggio a SQL come unica lingua dei clienti accelerata poiché gli ingegneri di Google si sono resi conto che SQL ha tutti i costrutti giusti per lo sviluppo di app Agile, specialmente nell’era nativa cloud in cui l’infrastruttura è molto più dinamica e soggetta a fallimenti rispetto ai dati privati altamente affidabili del passato del passato. Oggi più database moderni (incluso YugaBytedB) hanno dato vita a Google Spanner Design completamente in open source.
Gestione del volume dei dati su scala Internet con facilità
Sharding è completamente automatico nell’architettura Spanner. Inoltre, i frammenti diventano bilanciati automaticamente su tutti i nodi disponibili man mano che vengono aggiunti nuovi nodi o vengono rimossi i nodi esistenti. I microservizi che necessitano di una massiccia scalabilità della scrittura possono ora fare affidamento sul database direttamente invece di aggiungere nuovi livelli di infrastruttura simili a quelli che abbiamo visto nell’architettura FB. Non è necessario una cache in memoria (che scarica le richieste di lettura dal database, liberandolo così per servire le richieste di scrittura) e anche non è necessario un livello di applicazione simile a TAO che esegue la gestione dei frammenti.
Estrema resilienza contro i fallimenti
Una differenza chiave tra Spanner e le database di notizie legacy che abbiamo esaminato nella sezione precedente è Spanner’S Uso del consenso distribuito per shard per garantire che ogni frammento (e non semplicemente ogni istanza) rimanga altamente disponibile in presenza di guasti. Simile a TAO, gli errori di infrastruttura influiscono sempre solo un sottoinsieme di dati (solo quei frammenti i cui leader vengono divisiti) e mai l’intero cluster. E, data la capacità delle restanti repliche di frammenti di segnare automaticamente un nuovo leader in pochi secondi, il cluster mostra caratteristiche di auto-guarigione se soggetto a guasti. L’applicazione rimane trasparente a queste modifiche alla configurazione del cluster e continua a funzionare normalmente senza interruzioni o rallentamenti.
Replica senza soluzione di continuità in tutto il mondo
Il vantaggio di un’architettura di database cotta a livello globale è che i microservizi che necessitano di dati assolutamente corretti in scenari di scrittura multi-zone e multi-regione possono finalmente fare affidamento sul database direttamente. Non si verificano conflitti e perdita di dati osservati nelle tipiche distribuzioni multi-master del passato. Caratteristiche come il geo-partizionamento a livello di tabella e a livello di riga assicurano che i dati rilevanti per la regione locale rimangono conduciti nella stessa regione. Ciò garantisce che il percorso di lettura fortemente coerente non sostenga mai la latenza cross-region/wan.
Full Power of SQL e Transazioni di acido distribuito
A differenza dei database di notizie legacy, le transazioni SQL e Acid nella loro forma completa possono essere supportate nell’architettura Spanner. Le operazioni a chiave singola sono di default fortemente coerenti e transazionali (il termine tecnico è linearizzabile). Le transazioni single-shard per definizione sono guidate in un singolo frammento e quindi possono essere impegnate senza l’uso di un gestore delle transazioni distribuito. Le transazioni acido multi-rastre (aka distribuite) comportano un commit in due fasi utilizzando un gestore delle transazioni distribuito che tiene traccia anche di clock inclinati attraverso i nodi. I join a più rastre sono gestiti in modo simile interrogando i dati attraverso i nodi. La chiave qui è che tutte le operazioni di accesso ai dati sono trasparenti per lo sviluppatore che utilizza semplicemente normali costrutti SQL per interagire con il database.
Riepilogo
Le storie di ridimensionamento dell’infrastruttura di dati in uno qualsiasi dei giganti della tecnologia, tra cui FB e Google, crea un ottimo apprendimento ingegneristico. In FB, abbiamo preso la strada della costruzione di Tao che ci ha permesso di preservare il nostro investimento esistente in Mysql sharded. I nostri ingegneri delle applicazioni hanno perso la possibilità di utilizzare SQL ma hanno guadagnato un sacco di altri vantaggi. Gli ingegneri di Google hanno dovuto affrontare sfide simili ma hanno scelto un percorso diverso creando Spanner, un database SQL completamente nuovo che può scalare in orizzontale, replicata perfettamente e tollerare facilmente i guasti infrastrutturali. FB e Google sono entrambe storie di successo incredibili, quindi non possiamo dire che un percorso fosse migliore dell’altro. Tuttavia, quando espandiamo l’orizzonte in architetture aziendali per lo scopo generale, Spanner arriva davanti a TAO a causa di tutti i motivi evidenziati in questo post. Costruendo YugabytedB’S Articolo di archiviazione sull’architettura Spanner, crediamo di poter portare l’agilità degli sviluppatori dei giganti della tecnologia alle imprese di oggi.
Aggiornato marzo 2019.
Che cosa’S il prossimo?
- Confronta lo yugabytedb in profondità con database come cockroachdb, Google Cloud Spanner e MongoDB.
- Inizia con YugaBytedB su MacOS, Linux, Docker e Kubernetes.
- Contattaci per saperne di più sulle licenze, sui prezzi o per programmare una panoramica tecnica.
Collegare
Facebook lead
a MongodB
Dopo aver effettuato l’integrazione con MongoDB, saranno disponibili le seguenti opzioni: ora hai la possibilità di automatizzare il trasferimento di lead da Facebook a MongoDB. In questo modo, puoi automatizzare i tuoi processi aziendali e risparmiare tempo.
Vota per creare un’integrazione con MongoDB
Sync Facebook porta a MongoDB
Vuoi trasferire automaticamente le lead da Facebook? Al momento non abbiamo un’integrazione pronta con il MongoDB, ma i nostri sviluppatori stanno lavorando a questa integrazione.
Dopo aver completato l’integrazione, non dovrai scaricare manualmente le lead da Facebook a MongoDB. Il nostro sistema controllerà nuovi lead 24 ore al giorno, 7 giorni alla settimana. Senza giorni liberi e vacanze.
Prossimamente

Integrare in 1 clic
Integrare gli annunci di lead di Facebook con MongoDB
Come funzionerà?
- Savemyleads monitora costantemente informazioni sui nuovi lead su Facebook
- Non appena è apparso un nuovo lead, il nostro servizio prenderà automaticamente tutti i dati sul lead e li trasferirà sul MongoDB.
Di cosa hai bisogno per iniziare?
- Connetti l’account ADS lead Facebook
- Connetti l’account MongoDB
- Abilita il trasferimento di lead da Facebook a MongoDB
Vota per l’integrazione con il mongodb. Più voti, più velocemente faremo l’integrazione. Il modulo di voto è in cima alla pagina.
Domande e risposte su Connect & Sync Facebook lead con MongoDB
Come integrare i lead di Facebook e MongoDB?
Dopo aver completato l’integrazione:
- È necessario registrarsi in Savemyleads
- Scegli quali dati trasferiscono da Facebook a MongoDB
- Accendi auto-aggiornamenti
- Ora i dati verranno trasferiti automaticamente da Facebook a MongoDB
Quanto tempo ci vuole per integrare Facebook porta a MongoDB?
A seconda del sistema con il quale si integrerai, il tempo di configurazione può variare e variare da 5 a 30 minuti. In media, la configurazione richiede 10-15 minuti.
Quanto costa integrare Facebook con MongoDB?
Offriamo piani per diversi volumi di compiti. Vai al “Prezzi” sezione e scegli l’insieme di funzionalità che si adatta meglio alle tue esigenze. Inoltre, hai l’opportunità di testare il servizio gratuitamente per 14 giorni.
Quanti servizi pronti per l’integrazione e inviare lead da FB?
Avremo pronto oltre 40 integrazioni.
Cos’è MongoDB?
MongoDB è un sistema di gestione del database. Non richiede una descrizione dello schema della tabella ed è un classico esempio di sistema NoSQL. La piattaforma è scritta in C ++. Utilizzato nella programmazione, supporta le richieste ad hoc. Implementa una ricerca tra espressioni regolari e puoi anche personalizzare le query per restituire serie casuali di risultati. Supporta gli indici e sa come lavorare con i set di replica, ovvero puoi salvare 2 o più copie di dati su nodi diversi. Ogni copia può fungere da replica primaria o secondaria. Le leggi le scritture sono fatte dalla copia principale. Gli ausiliari mantengono aggiornati i dati. Se la copia principale non funziona, il sistema sceglie quale copia diventa il master.
Il ridimensionamento del sistema è orizzontale in base alle regole per la segmentazione dei database con distribuzione in parti su diversi nodi del cluster. La chiave di emulazione è determinata dall’amministratore, nonché il criterio in base al quale i dati saranno diffusi negli angoli. Il carico è bilanciato perché le richieste possono essere accettate da tutti i nodi nel cluster. MongoDB può essere utilizzato per archiviare i file. Il sistema divide i file in parti e memorizza ciascuno di essi come documento indipendente.
Dal 2018, la versione 4 ha aggiunto supporto per le transazioni che soddisfano le normative acide. I conducenti ufficiali sono forniti per tutti i principali linguaggi di programmazione. Inoltre, è stato sviluppato un numero enorme di driver non ufficiali, che vengono rilasciati da sviluppatori di terze parti. Sono supportati dalla comunità e possono essere utilizzati per altre lingue e quadri. L’interfaccia del database è stata fornita dal wrapper MongoDB, ma tutte le versioni più vecchie della terza bussola MongoDB hanno ricevuto invece.
Se si desidera connetterti, integrare o sincronizzare gli annunci di lead Facebook con MongoDB – cantare ora e in 5 minuti nuovi lead verranno inviati automaticamente a MongoDB. Prova una prova gratuita!