


Google ha una funzione di trascrizione
Trascrivi in Google Documenti: Audio alla trascrizione del testo
Utilizzare lo snippet di codice di seguito per convertire un file video in un file audio utilizzando FFMPEG .
Trascrivi l’audio da un file video usando il discorso a testo
Questo tutorial mostra come trascrivere la traccia audio da un file video usando il discorso a testo.
I file audio possono provenire da molte fonti diverse. I dati audio possono provenire da un telefono (come la segreteria telefonica) o dalla colonna sonora inclusa in un file video.
Speech-to-text può usare uno dei numerosi apprendimento automatico Modelli Per trascrivere il tuo file audio, per abbinare al meglio la fonte originale dell’audio. Puoi ottenere risultati migliori dalla trascrizione del parlato specificando la fonte dell’audio originale. Ciò consente al parlato-te-text di elaborare i file audio utilizzando un modello di apprendimento automatico addestrato per dati simili al tuo file audio.
Obiettivi
- Invia una richiesta di trascrizione audio per un file video a Speech-to-Text.
Costi
- Discorso a testo
Per generare una stima dei costi in base all’utilizzo previsto, utilizzare il calcolatore dei prezzi. I nuovi utenti di Google Cloud potrebbero essere idonei per una prova gratuita.
Prima di iniziare
Questo tutorial ha diversi prerequisiti:
- Hai impostato un progetto vocale nella console di Google Cloud.
- Hai impostato il tuo ambiente utilizzando le credenziali predefinite dell’applicazione nella console di Google Cloud.
- Hai impostato l’ambiente di sviluppo per il linguaggio di programmazione prescelto.
- Hai installato la libreria client di Google Cloud per il linguaggio di programmazione scelto.
Preparare i dati audio
Prima di poter trascrivere l’audio da un video, è necessario estrarre i dati dal file video. Dopo aver estratto i dati audio, è necessario archiviarli in un secchio di archiviazione cloud o convertirlo in codifica di base64.
Nota: Se si utilizza una libreria client per la trascrizione, non è necessario archiviare o convertire i dati audio. Devi solo estrarre i dati audio dal file video prima di inviare una richiesta di trascrizione.
Estrai i dati audio
È possibile utilizzare qualsiasi strumento di conversione di file che gestisce file audio e video, come FFMPEG.
Utilizzare lo snippet di codice di seguito per convertire un file video in un file audio utilizzando FFMPEG .
FFMPEG -I Video-Input-File Audio-Output-File
Archiviare o convertire i dati audio
È possibile trascrivere un file audio memorizzato sul tuo computer locale o in un secchio di archiviazione cloud.
Utilizzare il seguente comando per caricare il tuo file audio su un bucket di archiviazione cloud esistente utilizzando lo strumento Gsutil.
Gsutil CP Audio-output-file Storage-Bucket-Uri
Se si utilizza un file locale e si prevede di inviare una richiesta utilizzando lo strumento Curl dalla riga di comando, è necessario convertire prima il file audio in dati codificati da base64.
Utilizzare il seguente comando per convertire un file audio in un file di testo.
Base64 Audio-Output-File -w 0> Audio-Data-text
Invia una richiesta di trascrizione
Utilizzare il seguente codice per inviare una richiesta di trascrizione a Speech-to-Text.
Richiesta di file locale
Protocollo
Fare riferimento al discorso: riconoscere l’endpoint API per i dettagli completi.
Per eseguire il riconoscimento vocale sincrono, fare una richiesta post e fornire l’organismo di richiesta appropriato. Di seguito mostra un esempio di richiesta post utilizzando Curl . L’esempio utilizza il token di accesso per un account di servizio impostato per il progetto utilizzando Google Cloud Google Cloud CLI. Per istruzioni sull’installazione della CLI GCloud, impostare un progetto con un account di servizio e ottenere un token di accesso, consultare QuickStart.
CURL -S -H "Content-Type: Application/JSON" \ -H "Autorizzazione: Bearer $ (Gcloud Auth Application-Default Print-Access-Token)" \ https: //.Googleapis.com/v1/discorso: riconoscere \ - -data ' < "config": < "encoding": "LINEAR16", "sampleRateHertz": 16000, "languageCode": "en-US", "Modello": "Video" >, "audio": < "uri": "gs://cloud-samples-tests/speech/Google_Gnome.wav" >> '
Vedere la documentazione di riferimento di riconoscimentoConfig per ulteriori informazioni sulla configurazione del corpo di richiesta.
Se la richiesta ha esito positivo, il server restituisce un codice di stato HTTP da 200 OK e la risposta in formato JSON:
Andare
Per autenticarsi in Speech-to-Text, impostare le credenziali predefinite dell’applicazione. Per ulteriori informazioni, consultare Autenticazione imposta per un ambiente di sviluppo locale.
Func ModelSelection (w io.Writer, Path String) Errore {ctx: = context.Sfondo () client, err: = discorso.NewClient (CTX) se err != nil {return fmt.ERRIRF ("NewClient: %W", err)} Defer Client.Close () // path = "../testdata/google_gnome.wav "dati, err: = ioutil.ReadFile (percorso) se err != nil {return fmt.ERRIRF ("ReadFile: %W", err)} req: = & SpeechPB.RiconoscereZerequest {config: & SpeechPb.RiconoscimentoConfig {codifica: SpeechPB.RiconoscimentoConfig_linear16, SamplerateHertz: 16000, LagingAgeCode: "En-US", Modello: "Video",}, Audio: & SpeechPB.RiconoscimentoAudio {audiosource: & SpeechPB.RiconoscimentoAudio_Content,},} resp, err: = client.Riconoscere (ctx, req) se err != nil {return fmt.Erroref ("Riconoscere: %w", err)} per i, risultato: = intervallo resp.Risultati {fmt.Fprintf (w, "%s \ n", stringhe.Ripeti ("-", 20)) fmt.Fprintf (w, "risultato %d \ n", i+1) per j, alternativa: = risultato di intervallo.Alternative {fmt.Fprintf (w, "alternativa %d: %s \ n", j+1, alternativa.Trascrizione)}} return nil} Giava
Per autenticarsi in Speech-to-Text, impostare le credenziali predefinite dell’applicazione. Per ulteriori informazioni, vedere Set U
Trascrivi in Google Documenti: Audio alla trascrizione del testo
Utilizzare lo snippet di codice di seguito per convertire un file video in un file audio utilizzando FFMPEG .
Trascrivi l’audio da un file video usando il discorso a testo
Questo tutorial mostra come trascrivere la traccia audio da un file video usando il discorso a testo.
I file audio possono provenire da molte fonti diverse. I dati audio possono provenire da un telefono (come la segreteria telefonica) o dalla colonna sonora inclusa in un file video.
Speech-to-text può usare uno dei numerosi apprendimento automatico Modelli Per trascrivere il tuo file audio, per abbinare al meglio la fonte originale dell’audio. Puoi ottenere risultati migliori dalla trascrizione del parlato specificando la fonte dell’audio originale. Ciò consente al parlato-te-text di elaborare i file audio utilizzando un modello di apprendimento automatico addestrato per dati simili al tuo file audio.
Obiettivi
- Invia una richiesta di trascrizione audio per un file video a Speech-to-Text.
Costi
- Discorso a testo
Per generare una stima dei costi in base all’utilizzo previsto, utilizzare il calcolatore dei prezzi. I nuovi utenti di Google Cloud potrebbero essere idonei per una prova gratuita.
Prima di iniziare
Questo tutorial ha diversi prerequisiti:
- Hai impostato un progetto vocale nella console di Google Cloud.
- Hai impostato il tuo ambiente utilizzando le credenziali predefinite dell’applicazione nella console di Google Cloud.
- Hai impostato l’ambiente di sviluppo per il linguaggio di programmazione prescelto.
- Hai installato la libreria client di Google Cloud per il linguaggio di programmazione scelto.
Preparare i dati audio
Prima di poter trascrivere l’audio da un video, è necessario estrarre i dati dal file video. Dopo aver estratto i dati audio, è necessario archiviarli in un secchio di archiviazione cloud o convertirlo in codifica di base64.
Nota: Se si utilizza una libreria client per la trascrizione, non è necessario archiviare o convertire i dati audio. Devi solo estrarre i dati audio dal file video prima di inviare una richiesta di trascrizione.
Estrai i dati audio
È possibile utilizzare qualsiasi strumento di conversione di file che gestisce file audio e video, come FFMPEG.
Utilizzare lo snippet di codice di seguito per convertire un file video in un file audio utilizzando FFMPEG .
ffmpeg -i Video-Input-File file audio-output
Archiviare o convertire i dati audio
È possibile trascrivere un file audio memorizzato sul tuo computer locale o in un secchio di archiviazione cloud.
Utilizzare il seguente comando per caricare il tuo file audio su un bucket di archiviazione cloud esistente utilizzando lo strumento Gsutil.
gsutil cp file audio-output Storage-Bucket-Uri
Se si utilizza un file locale e si prevede di inviare una richiesta utilizzando lo strumento Curl dalla riga di comando, è necessario convertire prima il file audio in dati codificati da base64.
Utilizzare il seguente comando per convertire un file audio in un file di testo.
Base64 file audio-output -W 0> text audio-data
Invia una richiesta di trascrizione
Utilizzare il seguente codice per inviare una richiesta di trascrizione a Speech-to-Text.
Richiesta di file locale
Protocollo
Fare riferimento al discorso: riconoscere l’endpoint API per i dettagli completi.
Per eseguire il riconoscimento vocale sincrono, fare una richiesta post e fornire l’organismo di richiesta appropriato. Di seguito mostra un esempio di richiesta post utilizzando Curl . L’esempio utilizza il token di accesso per un account di servizio impostato per il progetto utilizzando Google Cloud Google Cloud CLI. Per istruzioni sull’installazione della CLI GCloud, impostare un progetto con un account di servizio e ottenere un token di accesso, consultare QuickStart.
CURL -S -H "Content-Type: Application/JSON" \ -H "Autorizzazione: Bearer $ (Gcloud Auth Application-Default Print-Access-Token)" \ https: //.Googleapis.com/v1/discorso: riconoscere \ - -data ' < "config": < "encoding": "LINEAR16", "sampleRateHertz": 16000, "languageCode": "en-US", "Modello": "Video" >, "audio": < "uri": "gs://cloud-samples-tests/speech/Google_Gnome.wav" >> '
Vedere la documentazione di riferimento di riconoscimentoConfig per ulteriori informazioni sulla configurazione del corpo di richiesta.
Se la richiesta ha esito positivo, il server restituisce un codice di stato HTTP da 200 OK e la risposta in formato JSON:
Andare
Per autenticarsi in Speech-to-Text, impostare le credenziali predefinite dell’applicazione. Per ulteriori informazioni, consultare Autenticazione imposta per un ambiente di sviluppo locale.
Func ModelSelection (w io.Writer, Path String) Errore < ctx := context.Background() client, err := speech.NewClient(ctx) if err != nil < return fmt.Errorf("NewClient: %w", err) >Defer Client.Close () // path = "../testdata/google_gnome.wav "dati, err: = ioutil.ReadFile (percorso) se err != zero < return fmt.Errorf("ReadFile: %w", err) >Req: = & SpeechPb.Riconoscimento< Config: &speechpb.RecognitionConfig< Encoding: speechpb.RecognitionConfig_LINEAR16, SampleRateHertz: 16000, LanguageCode: "en-US", Model: "video", >, Audio: & SpeechPB.Riconoscimento< AudioSource: &speechpb.RecognitionAudio_Content, >, > resp, err: = client.Riconoscere (ctx, req) se err != zero < return fmt.Errorf("Recognize: %w", err) >per i, risultato: = gamma resp.Risultati < fmt.Fprintf(w, "%s\n", strings.Repeat("-", 20)) fmt.Fprintf(w, "Result %d\n", i+1) for j, alternative := range result.Alternatives < fmt.Fprintf(w, "Alternative %d: %s\n", j+1, alternative.Transcript) >> restituisce nil> Giava
Per autenticarsi in Speech-to-Text, impostare le credenziali predefinite dell’applicazione. Per ulteriori informazioni, consultare Autenticazione imposta per un ambiente di sviluppo locale.
/*** esegue la trascrizione del file audio dato in modo sincrono con il modello selezionato. * * @param filename Il percorso di un file audio per trascrivere */ public static void trascriceModElection (String FileName) genera un'eccezione < Path path = Paths.get(fileName); byte[] content = Files.readAllBytes(path); try (SpeechClient speech = SpeechClient.create()) < // Configure request with video media type RecognitionConfig recConfig = RecognitionConfig.newBuilder() // encoding may either be omitted or must match the value in the file header .setEncoding(AudioEncoding.LINEAR16) .setLanguageCode("en-US") // sample rate hertz may be either be omitted or must match the value in the file // header .setSampleRateHertz(16000) .setModel("video") .build(); RecognitionAudio recognitionAudio = RecognitionAudio.newBuilder().setContent(ByteString.copyFrom(content)).build(); RecognizeResponse recognizeResponse = speech.recognize(recConfig, recognitionAudio); // Just print the first result here. SpeechRecognitionResult result = recognizeResponse.getResultsList().get(0); // There can be several alternative transcripts for a given chunk of speech. Just use the // first (most likely) one here. SpeechRecognitionAlternative alternative = result.getAlternativesList().get(0); System.out.printf("Transcript : %s\n", alternative.getTranscript()); >>Nodo.js
Per autenticarsi in Speech-to-Text, impostare le credenziali predefinite dell’applicazione. Per ulteriori informazioni, consultare Autenticazione imposta per un ambiente di sviluppo locale.
// Importa la libreria client di Google Cloud per Beta API/** * Todo (sviluppatore): aggiorna la libreria client Importa per utilizzare la nuova * versione dell'API quando le funzionalità desiderate diventano disponibili */const Speech = requisite ('@Google-Cloud/Speech').v1p1beta1; const fs = requisito ('fs'); // crea un client client const = nuovo discorso.SpeechClient (); /*** TODO (sviluppatore): rimborso le seguenti righe prima di eseguire il campione. */ // const filename = 'percorso locale al file audio, e.G. /Path/to/audio.crudo'; // const model = 'modello da usare, e.G. Phone_Call, video, predefinito '; // const encoding = 'codifica del file audio, e.G. Linear16 '; // const samplerartertz = 16000; // const LagingAgeCode = 'BCP-47 Codice linguistico, E.G. en-us '; const config = < encoding: encoding, sampleRateHertz: sampleRateHertz, languageCode: languageCode, model: model, >; const audio = < content: fs.readFileSync(filename).toString('base64'), >; const richiedono = < config: config, audio: audio, >; // rileva il discorso nel file audio const [risposta] = attesa client.riconoscere (richiesta); trascrizione const = risposta.Risultati .mappa (risultato => risultato.alternative [0].trascrizione) .join ('\ n'); console.log ('trascrizione:', trascrizione);Pitone
Per autenticarsi in Speech-to-Text, impostare le credenziali predefinite dell’applicazione. Per ulteriori informazioni, consultare Autenticazione imposta per un ambiente di sviluppo locale.
DEF TRASCRIZIONE_MODEL_SELECTION (Speech_File, Modello): "" "Trascrivi il file audio dato in modo sincrono con il modello selezionato."" "Da Google.Cloud Import Speech Client = Speech.SpeechClient () con Open (Speech_File, "RB") come audio_file: content = audiio_file.leggi () audio = discorso.RiconoscimentoAudio (content = content) config = discorso.RiconoscimentoConfig (codifica = discorso.RiconoscimentoConfig.Audioencodifica.Linear16, campione_rate_hertz = 16000, lingua_code = "en-us", modello = modello,) risposta = client.riconoscere (config = config, audio = audio) per i, risulta enumerate (risposta.Risultati): alternativa = risultato.Alternatives [0] Print ("-" * 20) Print (F "Prima alternativa del risultato") Print (F "trascrizione:") Lingue aggiuntive
C#: Segui le istruzioni di configurazione C# nella pagina delle librerie client e quindi visitare la documentazione di riferimento del linguaggio a testo .NETTO.
PHP: Segui le istruzioni di configurazione PHP nella pagina delle librerie client e quindi visitare la documentazione di riferimento vocale per PHP.
Rubino: Segui le istruzioni di configurazione di Ruby sulla pagina delle librerie client e quindi visitare la documentazione di riferimento vocale per Ruby.
Richiesta di file remoto
Giava
Per autenticarsi in Speech-to-Text, impostare le credenziali predefinite dell’applicazione. Per ulteriori informazioni, consultare Autenticazione imposta per un ambiente di sviluppo locale.
/*** esegue la trascrizione del file audio remoto in modo asincrono con il modello selezionato. * * @param gcsuri Il percorso del file audio remoto da trascrivere. */ public static void trascrizioneModelSelectionGcs (String Gcsuri) genera un'eccezione < try (SpeechClient speech = SpeechClient.create()) < // Configure request with video media type RecognitionConfig config = RecognitionConfig.newBuilder() // encoding may either be omitted or must match the value in the file header .setEncoding(AudioEncoding.LINEAR16) .setLanguageCode("en-US") // sample rate hertz may be either be omitted or must match the value in the file // header .setSampleRateHertz(16000) .setModel("video") .build(); RecognitionAudio audio = RecognitionAudio.newBuilder().setUri(gcsUri).build(); // Use non-blocking call for getting file transcription OperationFutureresponse = speech.longRunningRecognizeAsync(config, audio); while (!response.isDone()) < System.out.println("Waiting for response. "); Thread.sleep(10000); >Elenco risultati = risposta.Ottenere().getResultSlist (); // basta stampare il primo risultato qui. Discorso di discorso di risultato = Risultati.ottenere (0); // Possono esserci diverse trascrizioni alternative per un dato pezzo di discorso. Basta usare quello // primo (molto probabilmente) qui. Alternativa internazionale del discorso = risultato.getALternativeSList ().ottenere (0); Sistema.fuori.printf ("trascrizione: %s \ n", alternativa.getTranScript ()); >>Nodo.js
Per autenticarsi in Speech-to-Text, impostare le credenziali predefinite dell’applicazione. Per ulteriori informazioni, consultare Autenticazione imposta per un ambiente di sviluppo locale.
// Importa la libreria client di Google Cloud per Beta API/** * Todo (sviluppatore): aggiorna la libreria client Importa per utilizzare la nuova * versione dell'API quando le funzionalità desiderate diventano disponibili */const Speech = requisite ('@Google-Cloud/Speech').v1p1beta1; // crea un client client const = nuovo discorso.SpeechClient (); /*** TODO (sviluppatore): rimborso le seguenti righe prima di eseguire il campione. */// const gcsuri = 'gs: // my-bucket/audio.crudo'; // const model = 'modello da usare, e.G. Phone_Call, video, predefinito '; // const encoding = 'codifica del file audio, e.G. Linear16 '; // const samplerartertz = 16000; // const LagingAgeCode = 'BCP-47 Codice linguistico, E.G. en-us '; const config = < encoding: encoding, sampleRateHertz: sampleRateHertz, languageCode: languageCode, model: model, >; const audio = < uri: gcsUri, >; const richiedono = < config: config, audio: audio, >; // rileva il discorso nel file audio. const [risposta] = attesa client.riconoscere (richiesta); trascrizione const = risposta.Risultati .mappa (risultato => risultato.alternative [0].trascrizione) .join ('\ n'); console.log ('trascrizione:', trascrizione);Pitone
Per autenticarsi in Speech-to-Text, impostare le credenziali predefinite dell’applicazione. Per ulteriori informazioni, consultare Autenticazione imposta per un ambiente di sviluppo locale.
def transscrice_model_selection_gcs (gcs_uri, modello): "" "trascrivi il file audio dato in modo asincrono con il modello selezionato."" "Da Google.Cloud Import Speech Client = Speech.SpeechClient () Audio = Speech.Riconoscimento Audio (Uri = GCS_URI) Config = Speech.RiconoscimentoConfig (codifica = discorso.RiconoscimentoConfig.Audioencodifica.Linear16, campione_rate_hertz = 16000, lingua_code = "en-us", modello = modello,) operazione = client.long_running_recognize (config = config, audio = audio) print ("in attesa dell'operazione da completare. ") Risposta = operazione.Risultato (timeout = 90) per i, risulta enumerate (risposta.Risultati): alternativa = risultato.Alternatives [0] Print ("-" * 20) Print (F "Prima alternativa del risultato") Print (F "trascrizione:") Lingue aggiuntive
C#: Segui le istruzioni di configurazione C# nella pagina delle librerie client e quindi visitare la documentazione di riferimento del linguaggio a testo .NETTO.
PHP: Segui le istruzioni di configurazione PHP nella pagina delle librerie client e quindi visitare la documentazione di riferimento vocale per PHP.
Rubino: Segui le istruzioni di configurazione di Ruby sulla pagina delle librerie client e quindi visitare la documentazione di riferimento vocale per Ruby.
Ripulire
Per evitare di incorrere in addebiti sul tuo account Google Cloud per le risorse utilizzate in questo tutorial, eliminare il progetto che contiene le risorse o mantenere il progetto ed eliminare le singole risorse.
Elimina il progetto
Il modo più semplice per eliminare la fatturazione è eliminare il progetto che hai creato per il tutorial.
- Tutto nel progetto è eliminato. Se hai usato un progetto esistente per questo tutorial, quando lo elimini, elimini anche qualsiasi altro lavoro che hai svolto nel progetto.
- Gli ID del progetto personalizzati sono persi. Quando hai creato questo progetto, potresti aver creato un ID progetto personalizzato che si desidera utilizzare in futuro. Per preservare gli URL che utilizzano l’ID progetto, come un AppSpot.com URL, elimina le risorse selezionate all’interno del progetto invece di eliminare l’intero progetto.
Attenzione: Eliminare un progetto ha i seguenti effetti:
Se prevedi di esplorare più tutorial e rapidi, riutilizzare i progetti può aiutarti a evitare di superare i limiti delle quote del progetto.
Elimina istanze
- Nella console di Google Cloud, vai al Istanze VM pagina. Vai alle istanze VM
- Seleziona la casella di controllo per l’istanza che si desidera eliminare.
- Per eliminare l’istanza, fare clic su più_vert Più azioni, clic Eliminare, e quindi seguire le istruzioni.
Elimina le regole del firewall per la rete predefinita
- Nella console di Google Cloud, vai al Firewall pagina. Vai al firewall
- Seleziona la casella di controllo per la regola del firewall che si desidera eliminare.
- Per eliminare la regola del firewall, fare clic su Elimina Eliminare.
Qual è il prossimo
- Scopri come ottenere timestamp per audio.
- Identifica diversi altoparlanti in un file audio.
Provalo da solo
Se sei nuovo a Google Cloud, crea un account per valutare come si esibisce in scenari nel mondo del mondo reale. I nuovi clienti ricevono anche $ 300 in crediti gratuiti per eseguire, testare e distribuire carichi di lavoro.
Invia feedback
Salvo quanto diversamente indicato, il contenuto di questa pagina è concesso in licenza ai sensi dell’attribuzione Creative Commons 4.0 Licenza e campioni di codice sono autorizzati ai sensi dell’Apache 2.0 licenza. Per i dettagli, consultare le politiche del sito degli sviluppatori di Google. Java è un marchio registrato di Oracle e/o delle sue affiliate.
Ultimo aggiornamento 2023-05-19 UTC.
Trascrivi in Google Documenti: Audio alla trascrizione del testo
Questo articolo esaminerà come trascrivere in Google Documenti utilizzando la funzione di digitazione vocale. Questo strumento di trascrizione gratuito è utile per molte attività oltre alla digitazione vocale regolare: puoi mettere le tue idee in forma scritta rapidamente, ottenere note approssimative dalle riunioni e creare script anche per i discorsi. Le trascrizioni sono utili per una serie di motivi: sono ricercabili, puoi usarle per creare sottotitoli e esso’è facile salvarli per riferimento futuro.
I documenti di Google possono trascrivere un file audio?
Non molte persone sanno che puoi utilizzare Google Documenti per trascrivere i file audio (anche se non noi’T lo consiglio! Invece, usa uno strumento di terze parti come SPF.io per ottenere trascrizioni accurate e rapide dai file audio). Ricorda che l’uso di uno strumento per qualcosa di diverso dal suo scopo principale ti darà risultati meno ideali. Se usi la digitazione vocale per ottenere trascrizioni gratuite dai file audio, la scrittura mancherà la punteggiatura, probabilmente ha parole errate o mancanti e necessita di una modifica sostanziale in seguito.
Questi sono alcuni vantaggi nell’uso della funzione di battitura vocale di Google Docs:
-GRATUITO: Google Docs non richiede commissioni per iniziare.
-Modificabile: il testo in un documento di Google è facile da modificare, commentare e utilizzare con i collaboratori che ti stanno aiutando
-Facilmente condivisibile: da quando tu’RE lavoro direttamente in Google Documenti, puoi utilizzare il
“condividere” Funzione per inviare la tua trascrizione ad amici e colleghi
Svantaggi per l’utilizzo di strumenti di trascrizione gratuiti come Google Documenti:
-Nessuna traduzione
-Nessun timestamp
-Nessuna punteggiatura automatica (puoi dire verbalmente “periodo” O “virgola,” Ma i documenti non trascriveranno con punteggiatura. Leggi di più sui comandi vocali qui).
-Nessun dizionario personalizzato o correzioni di ortografia automatica (se si desidera questa funzione, utilizzare SPF.io e crea il tuo database autoreplacement)
Come usare Google’S strumento text-to-spealch
Una volta che hai un file audio, segui questi passaggi per trascrivere in Google Documenti:
- Crea un nuovo doc:
Apri un nuovo file di Google Doc su https: // docs.Google.com/documento/
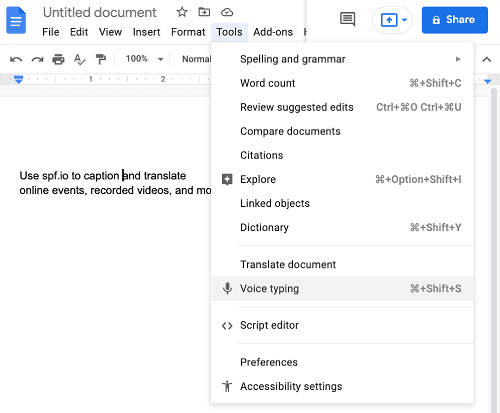
- Abilita il testo a discorso:
Sotto strumenti, seleziona “Digitazione vocale”
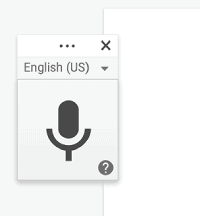
- Seleziona il tuo linguaggio di trascrizione:
Quando appare il microfono, è possibile utilizzare la freccia a discesa accanto alla lingua visualizzata (in questo caso, inglese (noi)) per selezionare la lingua. Quando trascrivi in Google Documenti per il lavoro bilingue, tu’Deve mettere in pausa e spegnere il microfono prima di passare a una nuova lingua ogni volta che vuoi parlarne una diversa.
- Inizia a trascrivere il tuo file audio:
Inizia a riprodurre il tuo file audio in una finestra diversa (assicurati che stia giocando sopra i tuoi altoparlanti, non attraverso un auricolare!). Fai clic sul microfono in Google Docs il prima possibile per catturare il suono. Il motivo per cui è necessario farlo in ordine è che se si fa clic sulla finestra di Google Docs, la trascrizione si fermerà. L’aspetto negativo è che tu’Perdi la prima parte del tuo file audio o video mentre fai clic su Google Docs per avviare la trascrizione.
- Modifica la tua trascrizione:
Questa è la parte più che richiede molto tempo di questo processo da quando hai vinto’T Ottieni una punteggiatura aggiunta automaticamente quando si trascrivi su Google Documenti. Nota che puoi’T Modifica il testo nel documento man mano che il tuo video/audio viene trascritto – La digitazione vocale aggiungerà il testo ovunque si inserisca il cursore.
Altri modi per utilizzare Google Docs Speech-to-Text:
- Scrivi più rapidamente
- Prendi appunti da una riunione
- Crea una sceneggiatura per un discorso
Trascrizioni audio/video facili e accurate con SPF.io
Sebbene il processo per trascrivere in Google Docs sia gratuito, può volerci molto tempo (che potrebbe finire per essere più costoso alla fine!). Si consiglia di utilizzare strumenti di terze parti come SPF.Io per ottenere trascrizioni accurate che richiedono un editing che richiede meno tempo rispetto agli strumenti gratuiti. Ciò è particolarmente necessario se hai molte ore di video/audio da trascrivere.
Con SPF.io, puoi persino usare la tua trascrizione per creare didascalie e sottotitoli. Dal momento che offriamo molte opzioni nel nostro strumento all-in-one, hai la libertà di tradurre il tuo testo in oltre 60 lingue! Offriamo anche sottotitoli in diretta per la maggior parte delle piattaforme come Zoom, Streamyard, YouTube e altro ancora.
Stanco di provare a trascrivere in Google Documenti? Semplifica il tuo processo e ottieni un preventivo da SPF.io per il tuo progetto di trascrizione!
Trascrizione di contenuti audio: risorse e how-to

Se vuoi trascrivere il contenuto audio, allora tu’Veni nel posto giusto. Sia che tu scelga di utilizzare un servizio di trascrizione di terze parti o fai-da-te (fallo da solo), esso’è importante valutare i pro e i contro e scegliere quale opzione funziona meglio per te.
Vantaggi dell’audio di trascrizione
- Crea un’esperienza utente migliore
- Aumenta le tue possibilità di essere citato e accreditato
- Aumenta l’ottimizzazione dei motori di ricerca (SEO)
- Migliora l’accessibilità per gli utenti che sono D/non udenti o con problemi di udito
Inoltre, molte aziende e organizzazioni lo sono Legalmente richiesto per creare trascrizioni per il loro contenuto Basato sull’American With Disabilities Act e nella sezione 504 e 508 della legge sulla riabilitazione. WCAG 2.0 è un insieme di linee guida messe in atto dal World Wide Web Consortium per rendere i contenuti digitali più accessibili agli utenti, compresi quelli con disabilità. WCAG 2.0 ha tre livelli di conformità: Livello A, AA e AAA. La sezione 508 è stata rivista per conformarsi a WCAG 2.0 Livello A e AA. Secondo il livello più basso, il livello A, le trascrizioni sono consigliate per il contenuto solo audio.
Noi’Fornisce le diverse risorse che tu’Deve trascrivere da un file audio e aiutarti a determinare la scelta più praticabile in base alle tue esigenze di budget, tempo e particolari. Buona fortuna e felice trascrizione!
Trascrizione fai -da -te
La trascrizione manuale dell’audio può essere un’attività scoraggiante, specialmente quando si dispone di forme di contenuto più lunghe. Di solito ci vogliono 5-6 volte il tempo effettivo del contenuto. Fortunatamente, ci sono molti strumenti gratuiti e a basso costo disponibili per semplificare il processo. Prima di iniziare a trascrivere, assicurati Cattura audio chiaro e forte. Ciò contribuirà a ridurre le bandiere rosse e i suoni impercettibili nella trascrizione.
Youtube

Se ospiti il tuo contenuto audio su YouTube, puoi utilizzare lo strumento di trascrizione video automatica gratuita. Questo strumento trascrive automaticamente l’audio nel testo, ma tieni presente che viene fornito molti errori. Trascrizioni prodotte da YouTube’S strumento è troppo impreciso per essere utilizzato da solo. Pertanto, esso’S Altamente raccomandato per ripulirli poiché possono Fai male alla tua accessibilità video e classifica sulle pagine dei risultati dei motori di ricerca (SERP).
Qui’S Come sfruttare YouTube’S trascrizione video automatica:
- Dal manager video, seleziona il video e fai clic su Modifica> sottotitoli e cc. Selezionare Aggiungi sottotitoli o CC E scegli la tua lingua.
- Selezionare Trascrivere e impostare i tempi, e digitare la trascrizione nello spazio fornito. YouTube metterà in pausa automaticamente il video mentre digiti in modo da poter trascrivere più rapidamente e in modo accurato.
- Una volta soddisfatto, seleziona Impostare i tempi. Questo sincronizzerà la tua trascrizione con il video.
Allo stesso modo, puoi creare una trascrizione in anticipo e caricarla su YouTube:
- Innanzitutto, crea una trascrizione con Youtube’S Raccomandazioni per la formattazione.
- Vai al video manager su YouTube e fai clic Modifica> sottotitoli e cc. Seleziona Aggiungi sottotitoli o CC e scegli la lingua.
- Scegliere Caricare un file, Selezionare Trascrizione, E scegli il tuo .file txt per il caricamento.
- Una volta caricata la trascrizione, fai clic su Impostare i tempi Per sincronizzare la trascrizione con il video e creare didascalie chiuse.
Puoi anche scaricare il file di trascrizione in seguito con i tempi come file di didascalie:
- Vai al video da cui desideri scaricare la trascrizione. Clicca sul Più azioni pulsante (3 punti orizzontali). Suggerimento: esso’S situato accanto al pulsante Condividi.
- Seleziona il Trascrizione opzione.
- Una trascrizione delle didascalie chiuse con i codici tempori genererà automaticamente.
Software ASR

Il riconoscimento vocale automatico, altrimenti noto come ASR, è una tecnologia che raccoglie il linguaggio umano e lo converte in testo. Puoi caricare i tuoi media su software ASR e trascriverà automaticamente l’audio nel testo. Questo metodo ha ancora molti errori, ma esso’è molto più facile e più veloce per ripulire una trascrizione inaccurata che iniziare da zero.
Esistono molte opzioni per il software di trascrizione che sono gratuiti o disponibili per un piccolo costo, come Express Scribe, EureScribe e Dragon naturalmente.
documenti Google
Google offre una funzionalità fantastica che ti consente di trasformare i documenti in software di trascrizione gratuito. Se indossi’t Avere un account Gmail, puoi registrarti gratuitamente. Se hai un account esistente, hai già accesso a una funzione chiamata documenti Google; Google Docs è uno strumento di elaborazione testi che ti consente di creare documenti di testo nel browser Web. Utilizzando la digitazione vocale, la trascrizione vocale di Google può creare trascrizioni di testo dall’audio. Come molti degli altri strumenti di trascrizione manuale, ci saranno errori, quindi assicurati di ripulirlo prima di usarlo.
Segui questi passaggi per creare la tua trascrizione:
- Utilizzando qualsiasi browser a tua scelta, vai al sito Web di Google Docs e Avvia un nuovo documento.
- Clicca su Utensili e seleziona Digitazione vocale. Abiliterà il riconoscimento vocale.
- Clicca il Microfono icona a sinistra per attivare Digitazione vocale. Google trascriverà tutto ciò che viene detto al documento Word.
iOS/Android

Un altro modo per trascrivere i contenuti audio è utilizzando il tuo smartphone. Simile a Google Documenti, il microfono raccoglierà l’audio e lo trascriverà nel testo. La trascrizione sul tuo smartphone tende a funzionare un po ‘meglio dei documenti di Google poiché il microfono sul telefono raccoglie meno rumore di fondo; Tuttavia, non lo fa ancora’T paragonati a un microfono di alta qualità. Registrazione sul tuo smartphone ha vinto’T Assicurati un alto tasso di precisione, quindi dovrai ripulire la trascrizione finale.
Ecco le istruzioni passo-passo su come trascrivere l’audio nel testo con il tuo smartphone:
- Apri a App di elaborazione testi Sul tuo smartphone.
- Sulla tastiera del tuo smartphone, seleziona il Microfono pulsante e inizierà a registrare.
- Tieni il telefono vicino al tuo computer o ad altro dispositivo e Riproduzione del video. Il tuo telefono trasformerà automaticamente l’audio in testo.
Pro vs. Contro di trascrizioni fai -da -te
Professionisti
- Più economico
- Buono per contenuti più brevi
Contro
- Che richiede tempo per creare
- Laburista
- Basso livello di precisione
Servizi di trascrizione
Un’altra opzione per trascrivere il contenuto audio al testo è utilizzare un servizio di trascrizione di terze parti. Se tu’REI alla ricerca di trascrizioni di alta qualità e accurate, questa è sicuramente la strada da percorrere!
3Play Media offre un Processo di trascrizione in 3 fasi che utilizza sia la tecnologia che i trascritisti umani, garantendo un 99.Tasso di precisione del 6%. Quando il file audio è costituito da contenuti difficili, ha rumore di fondo o contiene accenti, il tasso di accuratezza diminuisce. ASR in genere fornisce una precisione del 60-70%, quindi l’uso di trascrizioni umane distingue 3 Play da altre opzioni di trascrizione.
La nostra tecnologia brevettata utilizza ASR per produrre automaticamente una trascrizione approssimativa, utile per creare tempi accurati anche se le parole e la grammatica sono errate. Utilizzando il software proprietario, i nostri trascritisti passano e modificano la trascrizione. Tutti i nostri trascritisti subiscono un rigoroso processo di certificazione e hanno una forte comprensione della grammatica inglese, che è importante per comprendere tutte le sfumature dei tuoi contenuti. Dopo il processo di modifica, il tuo file passa attraverso una revisione finale chiamata Quality Assurance. Il tuo file viene esaminato dai nostri migliori editor, che assicurano che la tua trascrizione sia praticamente impeccabile.
Una caratteristica che offriamo anche è il Transcrizione interattiva 3 -Play. Questa funzione consente agli utenti di interagire con il tuo video cercando il video, navigando facendo clic su qualsiasi parola e leggendo insieme all’audio. Le trascrizioni interattive rendono i tuoi contenuti più accessibili e migliorano l’esperienza dell’utente.
Pro vs. Contro di un servizio di trascrizione
Professionisti
- Alto livello di precisione
- Più affidabile
- Gestisce grandi quantità di contenuto
- Accesso a strumenti unici
- Accesso al personale qualificato
Contro
- Più costoso
Best practice di trascrizione
Ora che hai una migliore comprensione della trascrizione manuale rispetto a un servizio di trascrizione, puoi prendere una decisione informata. Non importa quale opzione tu scelga, esso’è importante sapere come farlo sfruttare al massimo le tue trascrizioni.
- Grammatica e punteggiatura: Assicurati che non ci siano errori nella trascrizione in modo che sia facile da leggere.
- Identificazione degli altoparlanti: Usa etichette degli altoparlanti per identificare chi sta parlando, specialmente quando ci sono più altoparlanti.
- Suoni non diretti: Comunicare suoni non diretti nelle trascrizioni. Questi sono in genere indicati con [parentesi quadrate].
- Alla lettera: Trascrivi il contenuto il più vicino possibile alla lettera. Lascia fuori le parole di riempimento come “um” O “Piace” A meno che non siano’re intenzionalmente incluso nell’audio.
Voglio saperne di più?

Questo post è stato originariamente pubblicato da Samantha Sauld il 30 agosto 2018 e da allora è stato aggiornato.
Trascrivi il discorso al testo utilizzando la console di Google Cloud
Questo QuickStart ti introduce alla console vocale del cloud. In questo QuickStart, creerai e perfezionerà una trascrizione e imparerai come utilizzare questa configurazione con l’API Speech-to-Text per le proprie applicazioni.
Per imparare a inviare richieste e ricevere risposte utilizzando l’API RET anziché la console, consultare la pagina prima dell’inizio.
Prima di iniziare
Prima di poter iniziare a utilizzare la console Speech-to-Text, è necessario abilitare l’API nella console della piattaforma cloud di Google. I passaggi seguenti ti guidano attraverso le seguenti azioni:
- Abilita il discorso a testo su un progetto.
- Assicurarsi che la fatturazione sia abilitata per il discorso a testo.
Imposta il tuo progetto Google Cloud
- Accedi a Google Cloud Console
- Vai alla pagina Selettore del progetto puoi scegliere un progetto esistente o crearne uno nuovo. Per maggiori dettagli sulla creazione di un progetto, consultare la documentazione di Google Cloud Platform.
- Se crei un nuovo progetto, ti verrà richiesto di collegare un account di fatturazione a questo progetto. Se si utilizza un progetto preesistente, assicurati di avere la fatturazione abilitata. Scopri come confermare che la fatturazione è abilitata per il tuo progettoNota: È necessario consentire la fatturazione di utilizzare l’API Speech-to-Text, tuttavia non ti verrà addebitato a meno che tu non superi la quota gratuita. Vedi la pagina dei prezzi per maggiori dettagli.
- Una volta selezionato un progetto e lo hai collegato a un account di fatturazione, puoi abilitare l’API vocale. Vai al Cerca prodotti e risorse bar nella parte superiore della pagina e digita “discorso”.
- Seleziona il API del discorso a testo cloud Dall’elenco dei risultati.
- Per provare il discorso a testo senza collegarlo al tuo progetto, scegli il Prova questa API opzione. Per abilitare l’API vocale per l’uso con il progetto, fare clic su ABILITARE.
Crea una trascrizione
Utilizzare la console di Google Cloud per creare una nuova trascrizione:
Configurazione audio
- Apri il Discorso a testo Panoramica.

- Clic Crea trascrizione.
- Se è la prima volta che utilizza la console, ti verrà chiesto di scegliere dove in Cloud Storage per archiviare le configurazioni e le trascrizioni.
- Se è la prima volta che utilizza la console, ti verrà chiesto di scegliere dove in Cloud Storage per archiviare le configurazioni e le trascrizioni.
- Nel Crea trascrizione pagina, Carica un file audio di origine. Puoi scegliere un file che è già salvato in Cloud Storage o caricarne uno nuovo nella destinazione di archiviazione cloud specificata.
- Seleziona i file audio caricati Tipo di codifica.
- Specificare il suo frequenza di campionamento.
- Clic Continua. Sarai portato a Opzioni di trascrizione.
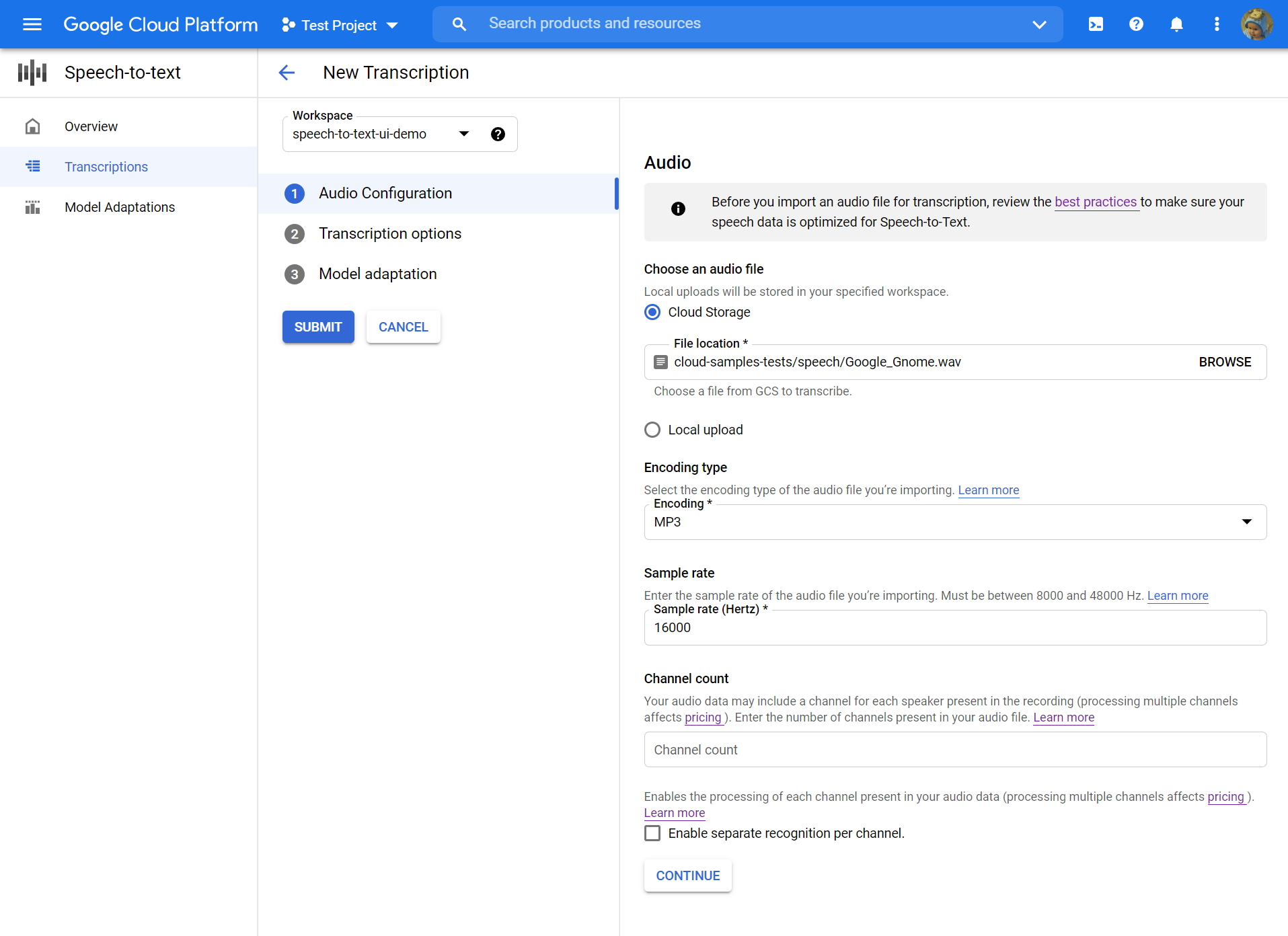
Opzioni di trascrizione

- Seleziona il Codice di lingua del tuo audio di origine. Questa è la lingua che viene parlata nella registrazione.
- Scegli il Modello di trascrizione vorresti usare sul file. L’opzione predefinita è preselezionata e, in generale, non è necessaria alcuna modifica, ma corrispondere al modello al tipo di audio può comportare una maggiore precisione. Si noti che i costi del modello variano.
- Clic Continua. Sarai portato a Adattamento del modello.
Adattamento del modello (opzionale)
Se l’audio di origine contiene cose come parole rare, nomi propri o termini proprietari e si riscontrano problemi con il riconoscimento, l’adattamento del modello può aiutare.

- Controllo Accendi l’adattamento del modello.
- Scegliere Risorsa di adattamento una tantum.
- Aggiungi pertinente frasi e dai loro un Aumenta il valore.
- Nella colonna sinistra, fare clic Invia Per creare la tua trascrizione.
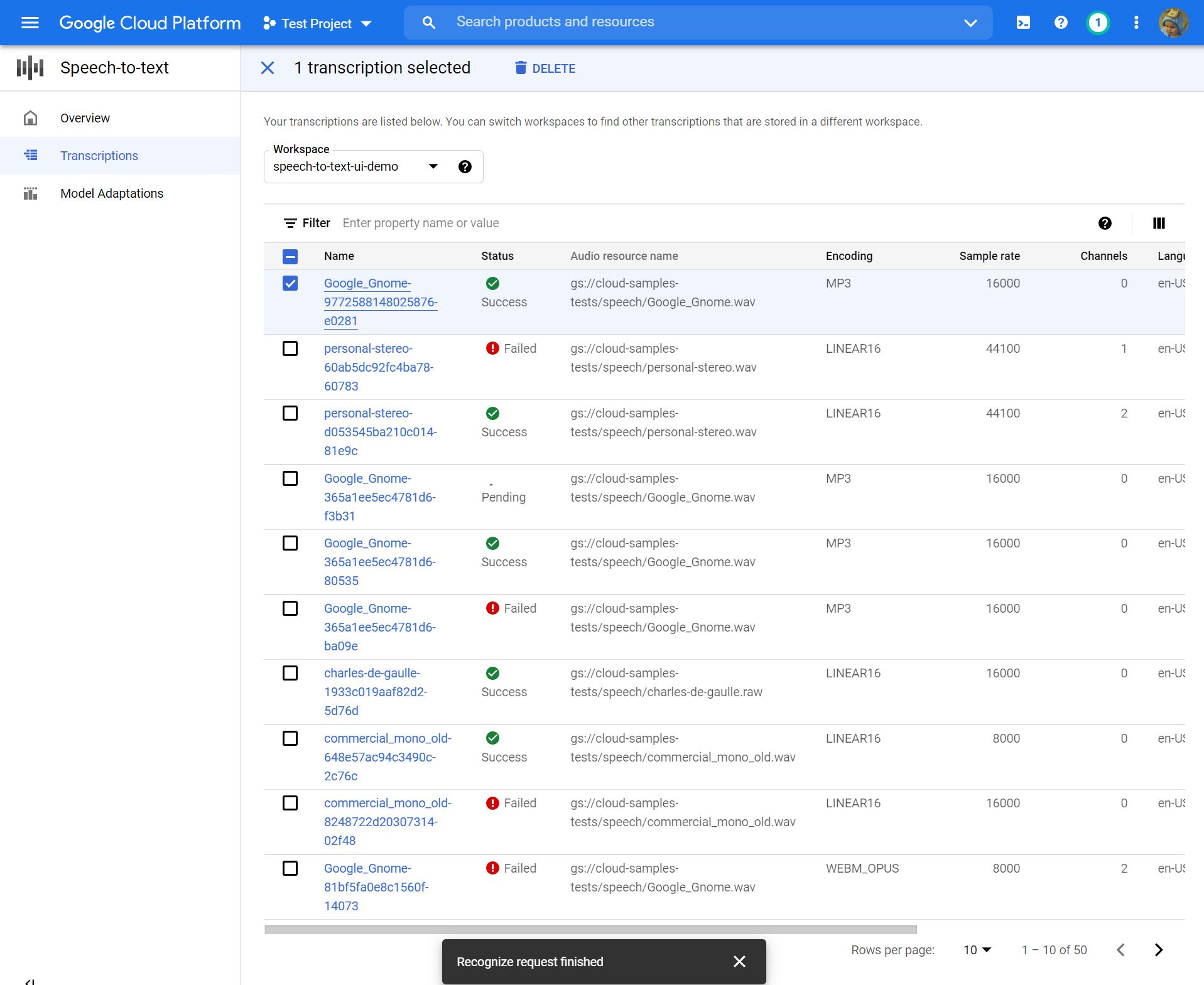
Rivedi la tua trascrizione
A seconda delle dimensioni del tuo file audio, una trascrizione può richiedere da minuti a ore per creare. Una volta creata la trascrizione, è pronta per la revisione. L’ordinamento della tabella per timestamp può aiutarti a individuare facilmente le tue recenti trascrizioni.
- Clicca sul Nome della trascrizione che desideri rivedere.
- Confronta il Trascrizione testo al file audio
- Se desideri apportare modifiche, fai clic Riutilizzare la configurazione. Questo ti porterà al Crea trascrizione fluire con le stesse opzioni preselezionate, permettendoti di cambiare alcune cose, creare una nuova trascrizione e confrontare i risultati.
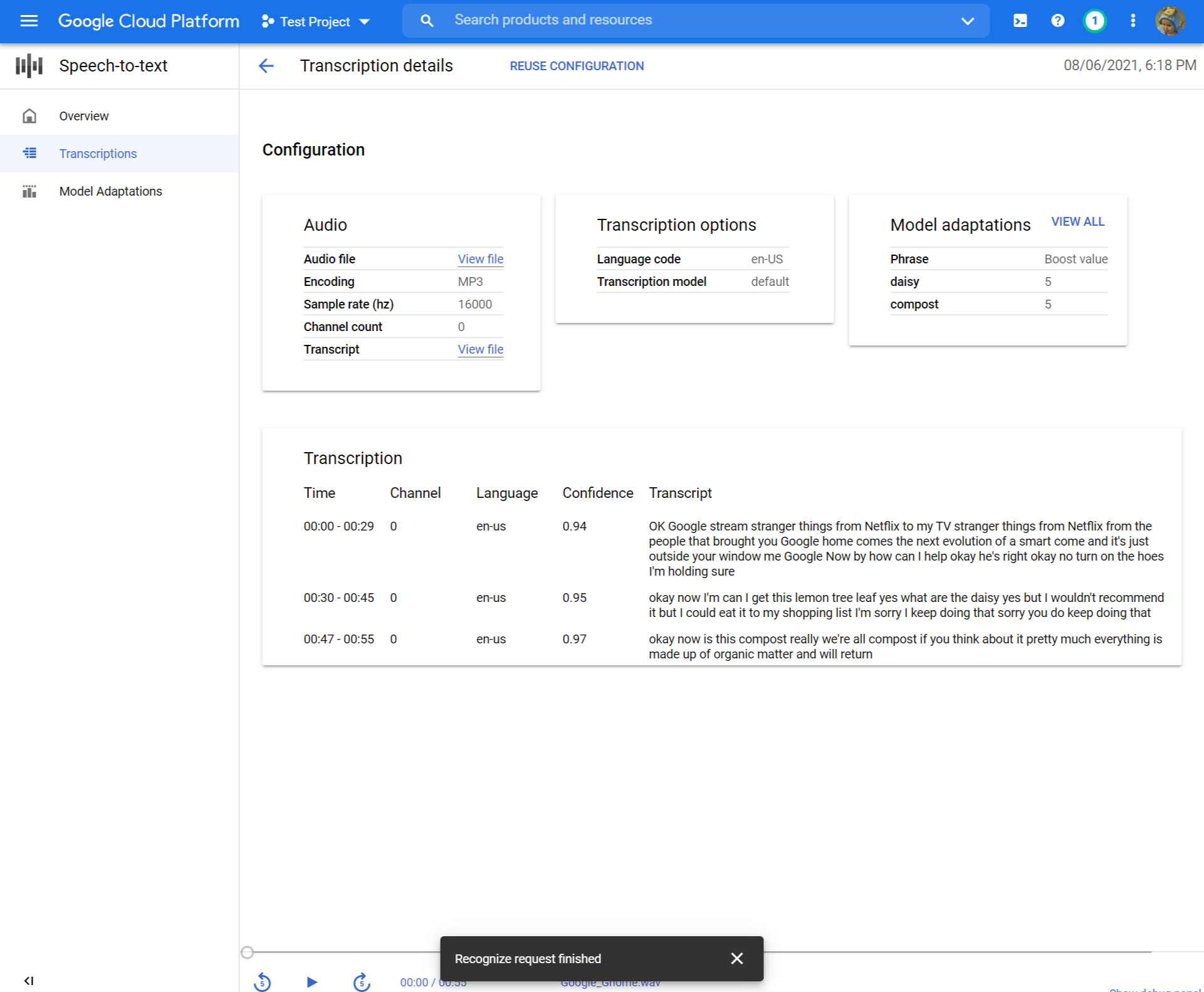
Qual è il prossimo
- Pratica trascrizione di brevi file audio.
- Scopri come batch a lunghi file audio per il riconoscimento vocale.
- Scopri come trascrivere l’audio di streaming come da un microfono.
- Inizia con il discorso a testo nella tua lingua preferita usando una libreria client vocale.
- Lavorare attraverso le applicazioni di esempio.
- Per le migliori prestazioni, precisione e altri suggerimenti, consultare la documentazione delle migliori pratiche.
Invia feedback
Salvo quanto diversamente indicato, il contenuto di questa pagina è concesso in licenza ai sensi dell’attribuzione Creative Commons 4.0 Licenza e campioni di codice sono autorizzati ai sensi dell’Apache 2.0 licenza. Per i dettagli, consultare le politiche del sito degli sviluppatori di Google. Java è un marchio registrato di Oracle e/o delle sue affiliate.
Ultimo aggiornamento 2023-05-16 UTC.