


Netflix usa kafka?
Con Apache Kafka nel mondo dello studio e delle finanze Netflix
Riepilogo:
In Netflix, la maggior parte delle applicazioni utilizza la libreria client Java per produrre dati sulla pipeline Keystone. La pipeline consiste nel fronteggiare i cluster Kafka, responsabili della raccolta e del buffering di dati e dei cluster Kafka consumatori, contenenti argomenti per i consumatori in tempo reale. Netflix gestisce un totale di 36 cluster Kafka che gestiscono oltre 700 miliardi di messaggi al giorno. Per ottenere una consegna senza perdita, la pipeline consente un tasso di perdita di dati inferiore a 0.01%. I produttori e i broker sono configurati per garantire la disponibilità e una buona esperienza utente.
Punti chiave:
- Le applicazioni Netflix utilizzano la libreria client Java per produrre dati per la pipeline Keystone
- Esistono più produttori di Kafka su ogni istanza dell’applicazione
- Attraversare i cluster kafka raccolgono e buffer messaggi
- I cluster di consumatore Kafka contengono argomenti per i consumatori in tempo reale
- Netflix gestisce 36 cluster Kafka con oltre 700 miliardi di messaggi al giorno
- Il tasso di perdita dei dati è inferiore a 0.01%
- Produttori e broker sono configurati per garantire la disponibilità
- I produttori usano la configurazione dinamica per il routing degli argomenti e l’isolamento del lavandino
- Le applicazioni non java possono inviare eventi agli endpoint di riposo Keystone
- L’ordinamento dei messaggi è stabilito nell’elaborazione batch o nel livello di routing
Domande:
- In che modo le applicazioni Netflix producono dati per la pipeline Keystone?
- Quali sono i ruoli di accompagnare i cluster Kafka?
- Quali tipi di cluster Kafka esistono nella conduttura di Keystone?
- Quanti cluster Kafka opera Netflix?
- Qual è il tasso medio di ingestione dei dati per Netflix?
- Qual è la versione attuale di Kafka utilizzata da Netflix?
- In che modo Netflix raggiunge la consegna senza perdita?
- Qual è la configurazione per produttori e broker per garantire la disponibilità?
- Come viene mantenuto l’ordinamento dei messaggi?
- Perché le applicazioni client non consumano direttamente dal fronte di cluster Kafka?
- Quali sfide sorgono quando si esegue Kafka nel cloud?
- In che modo la replica influisce sulla disponibilità di Kafka?
- Ciò che ha fatto Netflix per affrontare gli incidenti e mantenere la stabilità del cluster?
- Qual è la strategia di distribuzione di Netflix per i cluster Kafka?
La maggior parte delle applicazioni Netflix utilizza la libreria client Java per produrre dati sulla pipeline Keystone. Ogni istanza dell’applicazione ha più produttori di Kafka.
Dare i cluster Kafka raccolgono e buffer i messaggi dai produttori. Servono come gateway per l’iniezione di messaggi.
Il gasdotto Keystone consiste nel fronteggiare i cluster Kafka e i cluster di consumatore Kafka.
Netflix gestisce 36 cluster Kafka.
Netflix ingerisce oltre 700 miliardi di messaggi al giorno.
Netflix sta passando dalla versione Kafka 0.8.2.1 a 0.9.0.1.
Contabilita per un enorme volume di dati, Netflix ha lavorato con i team per accettare una quantità accettabile di perdita di dati, con conseguente tasso di perdita di dati giornaliera inferiore a 0.01%.
I produttori e i broker sono configurati con blocco “ACKS = 1”, “.SU.respingente.full = false “e” impuro.capo.elezione.abilita = true “.
I produttori non utilizzano messaggi chiave e l’ordinamento dei messaggi viene ristabilito nel livello di elaborazione batch o nel livello di routing.
Le applicazioni del client non sono autorizzate a consumare direttamente dallorare i cluster Kafka per garantire un carico e la stabilità prevedibili.
L’esecuzione di kafka nel cloud pone sfide come il ciclo di vita di istanza imprevedibile, problemi di networking transitorio e valori anomali che causano problemi di prestazione.
La replica migliora la disponibilità, ma un broker outlier può causare effetti a cascata e calo dei messaggi a causa del ritardo di replica e dell’esaurimento del tampone.
Netflix ha ridotto lo stato e la complessità, ha implementato il rilevamento del valore anomalo e ha sviluppato misure per recuperare rapidamente dagli incidenti.
Netflix favorisce più piccoli cluster Kafka su un cluster gigante per ridurre le dipendenze e migliorare la stabilità.
Kafka all’interno del gasdotto Keystone
Abbiamo due set di cluster kafka in cantiere Keystone: fronte di kafka e consumatore kafka. Frontare i cluster kafka sono responsabili di ricevere i messaggi dai produttori che sono praticamente ogni istanza dell’applicazione in Netflix. I loro ruoli sono la raccolta dei dati e il buffering per i sistemi a valle. I cluster di consumatore Kafka contengono un sottoinsieme di argomenti instradati da Samza per i consumatori in tempo reale.
Attualmente gestiamo 36 cluster kafka costituiti da oltre 4.000 istanze di broker sia per la fronte di Kafka che per il consumatore Kafka. Più di 700 miliardi di messaggi vengono ingeriti in un giorno medio. Attualmente stiamo passando dalla versione Kafka 0.8.2.1 a 0.9.0.1.
Principi di progettazione
Data l’attuale architettura Kafka e il nostro enorme volume di dati, per raggiungere la consegna senza perdita per la nostra pipeline di dati è proibitivo in AWS EC2. Tenendo conto di questo, noi’VE ha lavorato con team che dipendono dalla nostra infrastruttura per arrivare a una quantità accettabile di perdita di dati, mentre bilancia il costo. Noi’VE ha raggiunto un tasso di perdita di dati giornaliera inferiore a 0.01%. Le metriche sono raccolte per i messaggi abbandonati in modo da poter agire se necessario.
La pipeline Keystone produce messaggi in modo asincrono senza bloccare le applicazioni. Nel caso in cui un messaggio non possa essere consegnato dopo i tentativi, verrà eliminato dal produttore per garantire la disponibilità dell’applicazione e la buona esperienza dell’utente. Questo è il motivo per cui abbiamo scelto la seguente configurazione per il nostro produttore e broker:
- Acks = 1
- bloccare.SU.respingente.pieno = false
- impuro.capo.elezione.abilita = true
La maggior parte delle applicazioni in Netflix utilizza la nostra libreria client Java per produrre per la pipeline Keystone. Su ogni istanza di tali applicazioni, ci sono più produttori di kafka, con ciascuno che produce un cluster Kafka per l’isolamento del livello di lavandino. I produttori hanno una configurazione flessibile di routing e lavandino che sono guidati tramite configurazione dinamica che può essere modificata in fase di esecuzione senza dover riavviare il processo di applicazione. Questo rende possibile per cose come reindirizzare il traffico e migrare gli argomenti tra i cluster Kafka. Per le applicazioni non java, possono scegliere di inviare eventi agli endpoint di riposo Keystone che trasmettono i messaggi per affrontare i cluster Kafka.
Per una maggiore flessibilità, i produttori non utilizzano messaggi chiave. L’ordinamento approssimativo dei messaggi viene ristabilito nel livello di elaborazione batch (Hive / Elasticsearch) o nel livello di routing per lo streaming dei consumatori.
Mettiamo la stabilità dei nostri cluster Kafka con un’alta priorità perché sono il gateway per l’iniezione di messaggi. Pertanto non consentiamo alle applicazioni client di consumare direttamente da esse per assicurarsi che abbiano un carico prevedibile.
Sfide della gestione di kafka nel cloud
Kafka è stato sviluppato con il data center come obiettivo di distribuzione su LinkedIn. Abbiamo fatto notevoli sforzi per far funzionare meglio Kafka nel cloud.
Nel cloud, le istanze hanno un ciclo di vita imprevedibile e possono essere terminate in qualsiasi momento a causa di problemi di hardware. Sono previsti problemi di networking transitorio. Questi non sono problemi per i servizi apolidi, ma rappresentano una grande sfida per un servizio statale che richiede Zookeeper e un singolo controller per il coordinamento.
La maggior parte dei nostri problemi inizia con i broker anomali. Un outlier può essere causato da un carico di lavoro irregolare, problemi hardware o il suo ambiente specifico, ad esempio, vicini rumorosi a causa della multi-tenancy. Un broker outlier può avere risposte lente a richieste o frequenti timeout/ritrasmissioni TCP. I produttori che inviano eventi a un tale broker avranno buone possibilità di esaurire i loro buffer locali in attesa di risposte, dopo di che il calo del messaggio diventa certezza. L’altro fattore che contribuisce all’esaurimento tampone è che Kafka 0.8.2 produttore non lo fa’t Timeout di supporto per i messaggi in attesa nel buffer.
Kafka’S Replication migliora la disponibilità. Tuttavia, la replicazione porta a inter-dipendenze tra i broker in cui un outlier può causare effetto a cascata. Se un outlier rallenta la replica, il ritardo della replica può accumularsi e infine far leggere i leader della partizione dal disco per servire le richieste di replica. Ciò rallenta i broker interessati e alla fine si traduce in produttori che fanno cadere i messaggi a causa di un buffer esausto, come spiegato nel caso precedente.
Durante i nostri primi giorni di gestione di Kafka, abbiamo vissuto un incidente in cui i produttori stavano lasciando cadere una quantità significativa di messaggi a un cluster Kafka con centinaia di istanze a causa di un problema di zookeeper mentre c’era poco che potevamo fare. Problemi di debug come questo in una piccola finestra temporale con centinaia di broker semplicemente non sono realistici.
A seguito dell’incidente, sono stati fatti sforzi per ridurre lo stato e la complessità per i nostri cluster Kafka, rilevare gli outlier e trovare un modo per ricominciare rapidamente con uno stato pulito quando si verifica un incidente.
Strategia di distribuzione di Kafka
Quelle che segue sono le strategie chiave che abbiamo usato per distribuire cluster Kafka:
- Favorire più piccoli cluster Kafka rispetto a un cluster gigante. Ciò riduce le dipendenze e migliora la stabilità.
- Implementare i meccanismi di rilevamento del valore anomalo per identificare e gestire i broker problematici.
- Sviluppare misure per riprendersi rapidamente dagli incidenti e iniziare con uno stato pulito.
Con Apache Kafka nel mondo dello studio e delle finanze Netflix
La maggior parte delle applicazioni in Netflix utilizza la nostra libreria client Java per produrre per la pipeline Keystone. Su ogni istanza di tali applicazioni, ci sono più produttori di kafka, con ciascuno che produce un cluster Kafka per l’isolamento del livello di lavandino. I produttori hanno una configurazione flessibile di routing e lavandino che sono guidati tramite configurazione dinamica che può essere modificata in fase di esecuzione senza dover riavviare il processo di applicazione. Questo rende possibile per cose come reindirizzare il traffico e migrare gli argomenti tra i cluster Kafka. Per le applicazioni non java, possono scegliere di inviare eventi agli endpoint di riposo Keystone che trasmettono i messaggi per affrontare i cluster Kafka.
Kafka all’interno del gasdotto Keystone
Abbiamo due set di cluster kafka in cantiere Keystone: fronte di kafka e consumatore kafka. Frontare i cluster kafka sono responsabili di ricevere i messaggi dai produttori che sono praticamente ogni istanza dell’applicazione in Netflix. I loro ruoli sono la raccolta dei dati e il buffering per i sistemi a valle. I cluster di consumatore Kafka contengono un sottoinsieme di argomenti instradati da Samza per i consumatori in tempo reale.
Attualmente gestiamo 36 cluster kafka costituiti da oltre 4.000 istanze di broker sia per la fronte di Kafka che per il consumatore Kafka. Più di 700 miliardi di messaggi vengono ingeriti in un giorno medio. Attualmente stiamo passando dalla versione Kafka 0.8.2.1 a 0.9.0.1.
Principi di progettazione
Data l’attuale architettura Kafka e il nostro enorme volume di dati, per raggiungere la consegna senza perdita per la nostra pipeline di dati è proibitivo in AWS EC2. Tenendo conto di questo, noi’VE ha lavorato con team che dipendono dalla nostra infrastruttura per arrivare a una quantità accettabile di perdita di dati, mentre bilancia il costo. Noi’VE ha raggiunto un tasso di perdita di dati giornaliera inferiore a 0.01%. Le metriche sono raccolte per i messaggi abbandonati in modo da poter agire se necessario.
La pipeline Keystone produce messaggi in modo asincrono senza bloccare le applicazioni. Nel caso in cui un messaggio non possa essere consegnato dopo i tentativi, verrà eliminato dal produttore per garantire la disponibilità dell’applicazione e la buona esperienza dell’utente. Questo è il motivo per cui abbiamo scelto la seguente configurazione per il nostro produttore e broker:
- Acks = 1
- bloccare.SU.respingente.pieno = false
- impuro.capo.elezione.abilita = true
La maggior parte delle applicazioni in Netflix utilizza la nostra libreria client Java per produrre per la pipeline Keystone. Su ogni istanza di tali applicazioni, ci sono più produttori di kafka, con ciascuno che produce un cluster Kafka per l’isolamento del livello di lavandino. I produttori hanno una configurazione flessibile di routing e lavandino che sono guidati tramite configurazione dinamica che può essere modificata in fase di esecuzione senza dover riavviare il processo di applicazione. Questo rende possibile per cose come reindirizzare il traffico e migrare gli argomenti tra i cluster Kafka. Per le applicazioni non java, possono scegliere di inviare eventi agli endpoint di riposo Keystone che trasmettono i messaggi per affrontare i cluster Kafka.
Per una maggiore flessibilità, i produttori non utilizzano messaggi chiave. L’ordinamento approssimativo dei messaggi viene ristabilito nel livello di elaborazione batch (Hive / Elasticsearch) o nel livello di routing per lo streaming dei consumatori.
Mettiamo la stabilità dei nostri cluster Kafka con un’alta priorità perché sono il gateway per l’iniezione di messaggi. Pertanto non consentiamo alle applicazioni client di consumare direttamente da esse per assicurarsi che abbiano un carico prevedibile.
Sfide della gestione di kafka nel cloud
Kafka è stato sviluppato con il data center come obiettivo di distribuzione su LinkedIn. Abbiamo fatto notevoli sforzi per far funzionare meglio Kafka nel cloud.
Nel cloud, le istanze hanno un ciclo di vita imprevedibile e possono essere terminate in qualsiasi momento a causa di problemi di hardware. Sono previsti problemi di networking transitorio. Questi non sono problemi per i servizi apolidi, ma rappresentano una grande sfida per un servizio statale che richiede Zookeeper e un singolo controller per il coordinamento.
La maggior parte dei nostri problemi inizia con i broker anomali. Un outlier può essere causato da un carico di lavoro irregolare, problemi hardware o il suo ambiente specifico, ad esempio, vicini rumorosi a causa della multi-tenancy. Un broker outlier può avere risposte lente a richieste o frequenti timeout/ritrasmissioni TCP. I produttori che inviano eventi a un tale broker avranno buone possibilità di esaurire i loro buffer locali in attesa di risposte, dopo di che il calo del messaggio diventa certezza. L’altro fattore che contribuisce all’esaurimento tampone è che Kafka 0.8.2 produttore non lo fa’t Timeout di supporto per i messaggi in attesa nel buffer.
Kafka’S Replication migliora la disponibilità. Tuttavia, la replicazione porta a inter-dipendenze tra i broker in cui un outlier può causare effetto a cascata. Se un outlier rallenta la replica, il ritardo della replica può accumularsi e infine far leggere i leader della partizione dal disco per servire le richieste di replica. Ciò rallenta i broker interessati e alla fine si traduce in produttori che fanno cadere i messaggi a causa di un buffer esausto, come spiegato nel caso precedente.
Durante i nostri primi giorni di gestione di Kafka, abbiamo vissuto un incidente in cui i produttori stavano lasciando cadere una quantità significativa di messaggi a un cluster Kafka con centinaia di istanze a causa di un problema di zookeeper mentre c’era poco che potevamo fare. Problemi di debug come questo in una piccola finestra temporale con centinaia di broker semplicemente non sono realistici.
A seguito dell’incidente, sono stati fatti sforzi per ridurre lo stato e la complessità per i nostri cluster Kafka, rilevare gli outlier e trovare un modo per ricominciare rapidamente con uno stato pulito quando si verifica un incidente.
Strategia di distribuzione di Kafka
Le seguenti sono le strategie chiave che abbiamo usato per distribuire cluster Kafka
- Favorire più piccoli cluster Kafka rispetto a un cluster gigante. Ciò riduce la complessità operativa per ogni cluster. Il nostro cluster più grande ha meno di 200 broker.
- Limitare il numero di partizioni in ciascun cluster. Ogni cluster ha meno di 10.000 partizioni. Ciò migliora la disponibilità e riduce la latenza per richieste/risposte che sono legate al numero di partizioni.
- Sforzati anche per la distribuzione delle repliche per ogni argomento. Anche il carico di lavoro è più facile per la pianificazione della capacità e il rilevamento dei valori anomali.
- Utilizzare il cluster di zookeeper dedicato per ciascun cluster Kafka per ridurre l’impatto dei problemi di zookeeper.
La tabella seguente mostra le nostre configurazioni di distribuzione.
KAFKA SILLAGE
Abbiamo automatizzato un processo in cui possiamo failover sia il traffico produttore che per il router (router) verso un nuovo cluster Kafka quando il cluster principale è nei guai. Per ogni cluster Kafka di fronte, c’è un cluster di standby freddo con la configurazione di lancio desiderata ma una capacità iniziale minima. Per garantire uno stato pulito per iniziare, il cluster di failover non ha argomenti creati e non condivide il cluster di zookeeper con il cluster Kafka primario. Il cluster di failover è inoltre progettato per avere il fattore di replica 1 in modo che sia libero da eventuali problemi di replica che il cluster originale potrebbe avere.
Quando si verifica il failover, vengono prese le seguenti fasi per deviare il traffico del produttore e del consumatore:
- Ridimensiona il cluster di failover sulla dimensione desiderata.
- Crea argomenti su e lancia i lavori di routing per il cluster di failover in parallelo.
- (Facoltativamente) Attendere che il controller sia stabilito dai leader delle partizioni per ridurre al minimo il calo del messaggio iniziale durante la produzione.
- Modifica dinamicamente la configurazione del produttore per passare il traffico del produttore al cluster di failover.
Lo scenario di failover può essere rappresentato dal seguente grafico:
Con la completa automazione del processo, possiamo eseguire il failover in meno di 5 minuti. Una volta che il failover è stato completato correttamente, possiamo eseguire il debug dei problemi con il cluster originale usando registri e metriche. È anche possibile distruggere completamente il cluster e ricostruire con nuove immagini prima di tornare indietro il traffico. In effetti, usiamo spesso la strategia di failover per deviare il traffico mentre facciamo manutenzione offline. Questo è il modo in cui stiamo aggiornando i nostri cluster Kafka alla nuova versione di Kafka senza dover eseguire l’aggiornamento a rotazione o impostare la versione del protocollo di comunicazione inter-broker.
Sviluppo per Kafka
Abbiamo sviluppato molti strumenti utili per Kafka. Ecco alcuni dei punti salienti:
Produttore Partizionatore appiccicoso
Questo è uno speciale partizionatore personalizzato che abbiamo sviluppato per la nostra biblioteca di produttori Java. Come suggerisce il nome, si attacca a una determinata partizione per la produzione per un periodo di tempo configurabile prima di scegliere casualmente la partizione successiva. Abbiamo scoperto che l’uso del partizionatore appiccicoso insieme al persistente aiuta a migliorare il batching dei messaggi e ridurre il carico per il broker. Ecco il tavolo per mostrare l’effetto del partizionatore appiccicoso:
Assegnazione di replica a conoscenza del rack
Tutti i nostri cluster Kafka si estendono in tre zone di disponibilità AWS. Una zona di disponibilità AWS è concettualmente un rack. Per garantire la disponibilità nel caso in cui una zona diminuisca, abbiamo sviluppato l’assegnazione replica a conoscenza del rack (zona) in modo che le repliche per lo stesso argomento siano assegnate a zone diverse. Ciò non solo aiuta a ridurre il rischio di un’interruzione di una zona, ma migliora anche la nostra disponibilità quando più broker si localizzano nello stesso host fisico sono terminati a causa di problemi host. In questo caso, abbiamo una migliore tolleranza agli errori di Kafka’s n – 1 dove n è il fattore di replica.
Il lavoro è contribuito alla comunità di Kafka in KIP-36 e Apache Kafka Github Pull Responsabile #132.
Visualizzatore dei metadati Kafka
Kafka’S Metadata è conservato in Zookeeper. Tuttavia, la visione dell’albero fornita dall’espositore è difficile da navigare ed richiede tempo per trovare e correlare le informazioni.
Abbiamo creato la nostra interfaccia utente per visualizzare i metadati. Fornisce sia la carta e le viste tabulari e utilizza schemi di colore ricchi per indicare lo stato ISR. Le caratteristiche chiave sono le seguenti:
- Scheda individuale per viste per broker, argomenti e cluster
- La maggior parte delle informazioni è ordinabile e ricercabile
- Alla ricerca di argomenti tra i cluster
- Mappatura diretta dall’ID broker a ID istanza AWS
- Correlazione dei broker da parte della relazione leader-dolower
I seguenti sono gli screenshot dell’interfaccia utente:
Monitoraggio
Abbiamo creato un servizio di monitoraggio dedicato per Kafka. È responsabile del monitoraggio:
- Stato del broker (in particolare, se è offline da Zookeeper)
- Broker’s capacità di ricevere messaggi dai produttori e consegnare messaggi ai consumatori. Il servizio di monitoraggio funge da produttore e consumatore per i messaggi di battito cardiaco continui e misura la latenza di questi messaggi.
- Per i vecchi consumatori a base di zookeeper, monitora il conteggio delle partizioni per il gruppo di consumatori per assicurarsi che ogni partizione sia consumata.
- Per i router Keystone Samza, monitora gli offset checkpoint e confronta con il broker’s Offset per assicurarsi che non siano bloccati e non abbiano un ritardo significativo.
Inoltre, abbiamo dashboard estesi per monitorare il flusso di traffico fino a un livello di argomento e la maggior parte del broker’metriche.
Piano futuro
Attualmente stiamo migrando a Kafka 0.9, che ha alcune caratteristiche che vogliamo utilizzare tra cui nuove API dei consumatori, timeout del messaggio produttore e quote. Sposteremo anche i nostri cluster Kafka su AWS VPC e crediamo che il suo miglior networking (rispetto a EC2 Classic) ci darà un vantaggio per migliorare la disponibilità e l’utilizzo delle risorse.
Presenteremo uno SLA a più livelli per gli argomenti. Per argomenti che possono accettare perdite minori, stiamo prendendo in considerazione l’utilizzo di una replica. Senza replica, non solo salviamo enorme sulla larghezza di banda, ma minimizziamo anche i cambiamenti di stato che devono dipendere dal controller. Questo è un altro passo per rendere Kafka meno stato in un ambiente che favorisce i servizi apolidi. L’aspetto negativo è la potenziale perdita dei messaggi quando un broker scompare. Tuttavia, sfruttando il timeout del messaggio del produttore in 0.9 Rilascio e possibilmente volume EBS AWS, possiamo mitigare la perdita.
Resta sintonizzato per i futuri blog Keystone sulla nostra infrastruttura di routing, gestione dei container, elaborazione dello streaming e altro ancora!
Con Apache Kafka nel mondo dello studio e delle finanze Netflix
Netflix ha speso circa 15 miliardi di dollari per produrre contenuti originali di livello mondiale nel 2019. Quando le quote sono così elevate, è fondamentale consentire alla nostra attività con approfondimenti critici che aiutano a pianificare, determinare la spesa e tenere conto di tutti i contenuti Netflix. Queste intuizioni possono includere:
- Quanto dovremmo spendere nel prossimo anno in film e serie internazionali?
- Stiamo tendendo per esaminare il nostro budget di produzione e chiunque deve intervenire per mantenere le cose in pista?
- Come programiamo un catalogo anni in anticipo con dati, intuizione e analisi per aiutare a creare la migliore lista possibile?
- Come produciamo finanziamenti per i contenuti in tutto il mondo e riferiamo a Wall Street?
Simile a come VCS sintonizzano rigorosamente l’occhio per buoni investimenti, il team di ingegneria dei contenuti finanziari’S Carter è di aiutare Netflix a investire, seguire e apprendere dalle nostre azioni in modo da fare costantemente investimenti migliori in futuro.
Abbraccia eventi
Dal punto di vista ingegneristico, ogni applicazione finanziaria è modellata e implementata come microservizio. Netflix abbraccia la governance distribuita e incoraggia un approccio guidato dai microservizi alle applicazioni, che aiuta a raggiungere il giusto equilibrio tra astrazione e velocità dei dati man mano che la società si ridimensiona. In un mondo semplice, i servizi possono interagire tramite HTTP perfettamente, ma man mano che ridimensioniamo, si evolve in un grafico complesso di interazioni sincroni basate su richieste che possono potenzialmente portare a un cervello diviso/stato e interrompere la disponibilità.
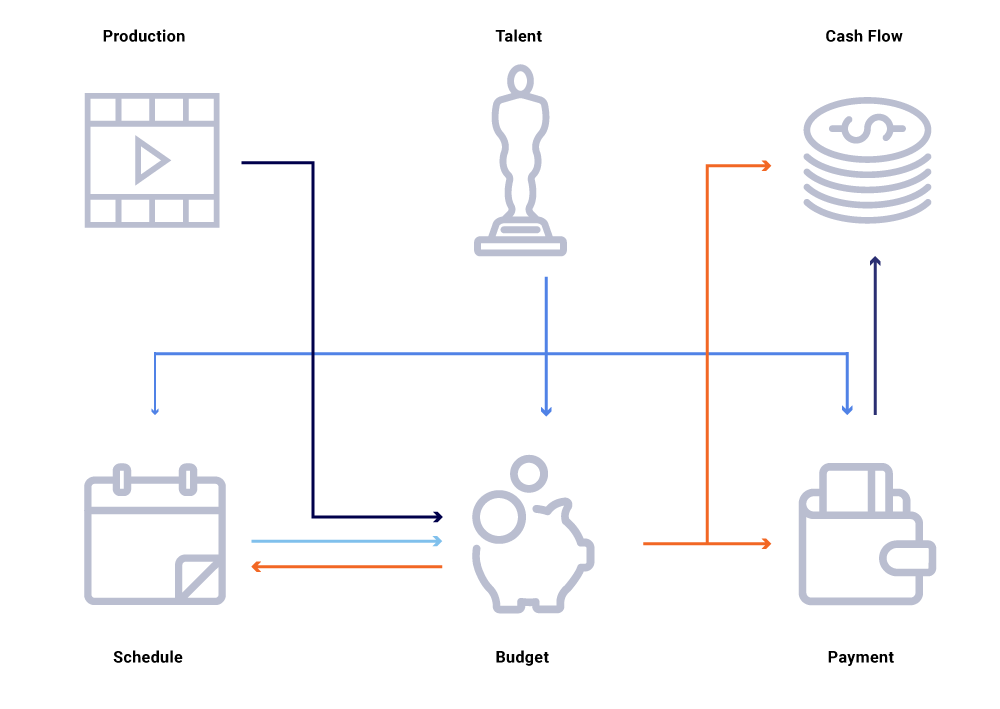
Considera nel grafico sopra delle entità correlate, una modifica nella data di produzione di uno spettacolo. Ciò influisce sulla nostra lista di programmazione, che a sua volta influenza i progetti del flusso di cassa, i pagamenti dei talenti, i budget per l’anno, ecc. Spesso in un’architettura a microservizio, è accettabile una certa percentuale di fallimento. Tuttavia, un fallimento in una delle richieste di microservizio per l’ingegneria della finanza dei contenuti porterebbe a una pletora di calcoli non sincronizzati e potrebbe comportare che i dati siano spenti di milioni di dollari. Parerebbe anche problemi di disponibilità mentre il grafico delle chiamate si estende e causerebbe punti ciechi mentre cerca di rintracciare e rispondere a domande aziendali, come ad esempio: perché le proiezioni del flusso di cassa si discostano dal nostro programma di lancio? Perché la previsione per l’anno in corso non tiene conto degli spettacoli che sono nello sviluppo attivo? Quando possiamo aspettarci che i nostri rapporti sui costi riflettano accuratamente le modifiche a monte?
Ripensare le interazioni del servizio come flussi di scambi di eventi, al contrario di una sequenza di richieste sincrine, ci consente di costruire infrastrutture intrinsecamente asincrona. Promuove il disaccoppiamento e fornisce tracciabilità come cittadino di prima classe in una rete di transazioni distribuite. Gli eventi sono molto più che scatenanti e aggiornamenti. Diventano il flusso immutabile da cui possiamo ricostruire l’intero stato di sistema.
Spostarsi verso un modello di pubblicazione/iscrizione consente a ogni servizio di pubblicare le sue modifiche come eventi in un bus di messaggi, che può quindi essere consumato da un altro servizio di interesse che deve adeguare il suo stato del mondo. Un tale modello ci consente di monitorare se i servizi sono sincronizzati rispetto alle modifiche allo stato e, in caso contrario, quanto tempo prima di poter essere sincronizzati. Queste intuizioni sono estremamente potenti quando si utilizza un grande grafico di servizi dipendenti. La comunicazione basata su eventi e il consumo decentralizzato ci aiutano a superare i problemi che di solito vediamo in grandi grafici di chiamate sincroni (come menzionato sopra).
Netflix abbraccia Apache Kafka ® come standard Defacto per le sue esigenze di elaborazione di eventi, messaggi e flusso. Kafka funge da ponte per tutte le comunicazioni Wide Point-to-Point e Netflix Studio. Ci fornisce l’elevata durata e l’architettura multi-tenant linearmente scalabile richiesta per i sistemi operativi su Netflix. Il nostro Kafka interno come offerta di servizi fornisce tolleranza ai guasti, osservabilità, distribuzioni multi-regioni e self-service. Ciò rende più facile per il nostro intero ecosistema di microservizi produrre e consumare facilmente eventi significativi e scatenare il potere della comunicazione asincrona.
Un tipico scambio di messaggi all’interno di Netflix Studio Ecosystem sembra questo:
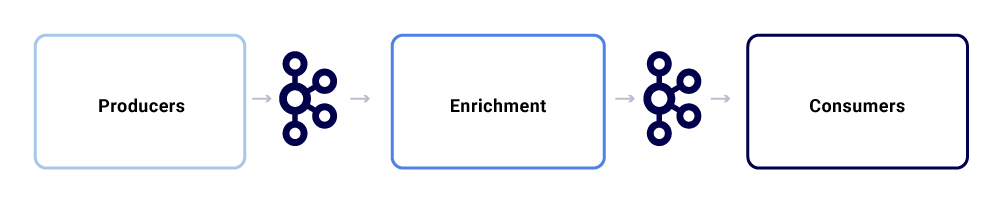
Possiamo romperli come tre sottocomponenti principali.
Produttori
Un produttore può essere qualsiasi sistema che desidera pubblicare il suo intero stato o suggerire che un pezzo critico del suo stato interno è cambiato per una particolare entità. Oltre al payload, un evento deve aderire a un formato normalizzato, il che rende più facile tracciare e capire. Questo formato include:
- Uuid: Identificatore universalmente univoco
- Tipo: Uno dei tipi di creazione, lettura, aggiornamento o elimina (CRUD)
- TS: Timestamp dell’evento
Gli strumenti di modifica dei dati cattura (CDC) sono un’altra categoria di produttori di eventi che derivano eventi fuori dal database modifiche. Questo può essere utile quando si desidera apportare le modifiche al database a più consumatori. Utilizziamo anche questo modello per replicare gli stessi dati tra i datacenter (per database master singoli). Un esempio è quando abbiamo dati in MySQL che devono essere indicizzati in Elasticsearch o Apache Solr ™. Il vantaggio dell’utilizzo di CDC è che non impone un carico aggiuntivo sull’applicazione di origine.
Per gli eventi CDC, il campo di tipo nel formato dell’evento semplifica l’adattamento e la trasformazione degli eventi come richiesto dai rispettivi lavandini.
Arricher
Una volta che esistono dati in Kafka, possono essere applicati vari modelli di consumo. Gli eventi vengono utilizzati in molti modi, inclusi i fattori scatenanti per i calcoli di sistema, il trasferimento del payload per la comunicazione quasi in tempo reale e i segnali per arricchire e materializzare le viste in memoria dei dati.
L’arricchimento dei dati sta diventando sempre più comune laddove i microservizi necessitano della visione completa di un set di dati, ma parte dei dati provengono da un altro servizio’set di dati S. Un set di dati uniti può essere utile per migliorare le prestazioni delle query o fornire una visione quasi in tempo reale dei dati aggregati. Per arricchire i dati degli eventi, i consumatori leggono i dati da Kafka e chiamano altri servizi (utilizzando metodi che includono GRPC e GraphQL) per costruire il set di dati uniti, che successivamente vengono alimentati ad altri argomenti di Kafka.
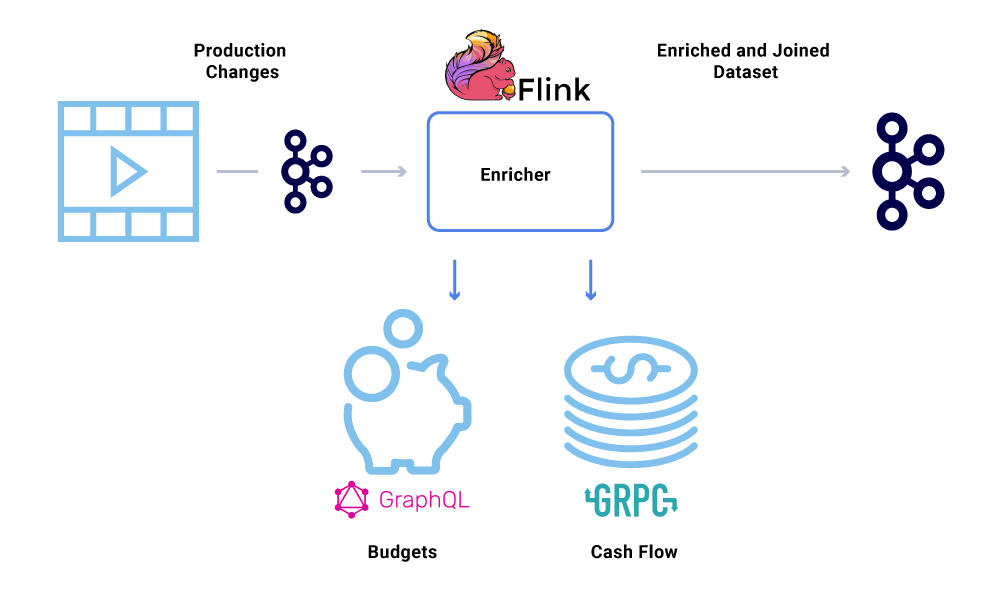
L’arricchimento può essere eseguito come un microservizio separato in sé che è responsabile del fatto di fare il ventilatore e di materializzare set di dati. Ci sono casi in cui vogliamo fare un elaborazione più complessa come finestre, sessioni e gestione dello stato. Per tali casi, si consiglia di utilizzare un motore di elaborazione del flusso maturo in cima a Kafka per costruire la logica aziendale. In Netflix, utilizziamo Apache Flink ® e Rocksdb per fare elaborazione in streaming. Noi’Riprendendo anche KSQLDB per scopi simili.
Ordine degli eventi
Uno dei requisiti chiave all’interno di un set di dati finanziari è il rigoroso ordinamento degli eventi. Kafka ci aiuta a raggiungere questo obiettivo è inviando messaggi chiave. Qualsiasi evento o messaggio inviato con la stessa chiave, avrà un ordine garantito poiché vengono inviati alla stessa partizione. Tuttavia, i produttori possono ancora rovinare l’ordinamento degli eventi.
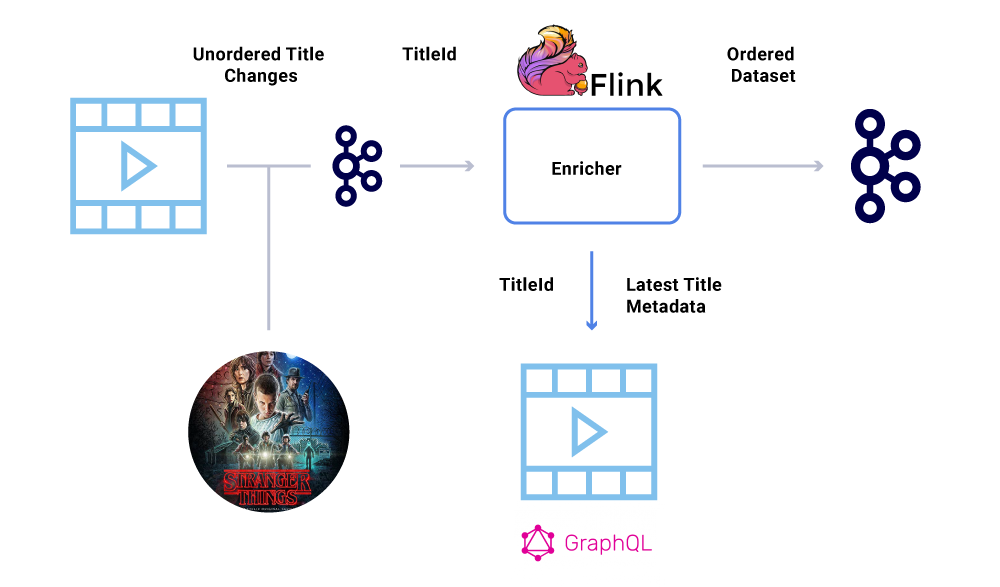
Ad esempio, la data di lancio di “Cose più strane” è stato originariamente trasferito da luglio a giugno ma poi tornante da giugno a luglio. Per una serie di motivi, questi eventi potrebbero essere scritti nell’ordine sbagliato a Kafka (timeout di rete quando il produttore ha cercato di raggiungere Kafka, un bug di concorrenza nel codice del produttore, ecc. Un Hiccup di ordinazione avrebbe potuto influire fortemente vari calcoli finanziari.
Per aggirare questo scenario, i produttori sono incoraggiati a inviare solo l’ID principale dell’entità che è cambiato e non il payload completo nel messaggio Kafka. Il processo di arricchimento (descritto nella sezione sopra) interroga il servizio di origine con l’ID dell’entità per ottenere lo stato/payload più aggiornato, fornendo così un modo elegante di eludere il problema fuori ordine. Ci riferiamo a questo come Materializzazione ritardata, e garantisce set di dati ordinati.
Consumatori
Utilizziamo Spring Boot per implementare molti dei microservizi consumanti che leggono dagli argomenti di Kafka. Spring Boot offre grandi consumatori Kafka integrati chiamati connettori Spring Kafka, che rendono i consumi senza soluzione di continuità, fornendo modi semplici per correre le annotazioni per il consumo e la deserializzazione dei dati.
Un aspetto dei dati che non abbiamo’T discusso ancora sono contratti. Mentre ridimensioniamo il nostro uso di flussi di eventi, finiamo con un vario gruppo di set di dati, alcuni dei quali sono consumati da un gran numero di applicazioni. In questi casi, la definizione di uno schema sull’output è l’ideale e aiuta a garantire la compatibilità all’indietro. Per fare ciò, sfruttiamo il registro degli schemi confluenti e Apache Avro ™ per costruire i nostri flussi schematizzati per il controllo dei flussi di dati.
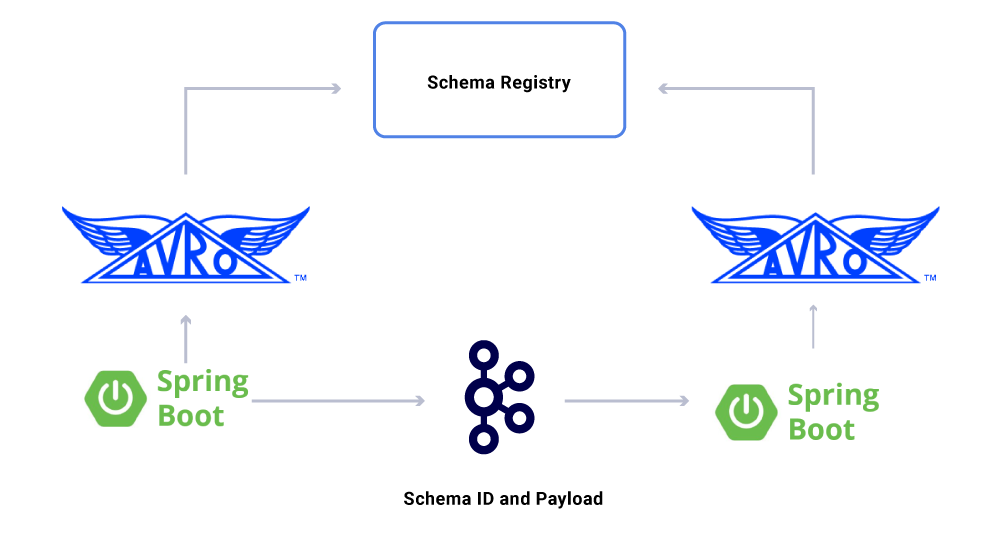
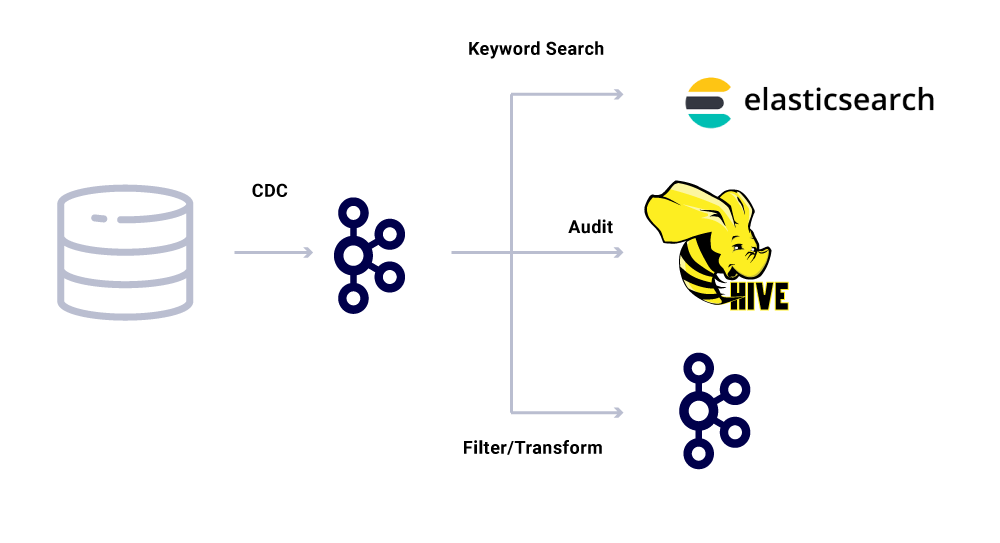
Oltre ai consumatori di microservizi dedicati, abbiamo anche lavandini CDC che indicizzano i dati in una varietà di negozi per ulteriori analisi. Questi includono ElaSticSearch per la ricerca di parole chiave, Apache Hive ™ per l’auditing e il kafka stesso per ulteriori elaborazioni a valle. Il payload per tali lavandini deriva direttamente dal messaggio Kafka utilizzando il campo ID come chiave primaria e tipo per identificare le operazioni CRUD.
Garanzie di consegna dei messaggi
Garantire esattamente una volta che la consegna in un sistema distribuito non è banale a causa delle complessità coinvolte e di una pletora di parti in movimento. I consumatori dovrebbero avere un comportamento idoneo per tenere conto di qualsiasi potenziale infrastruttura e incidenti da produttori.
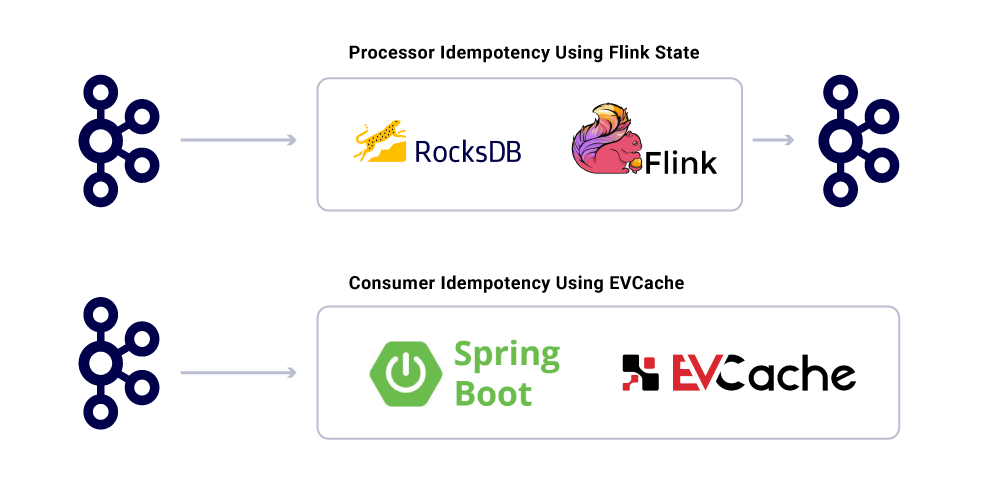
Nonostante il fatto che le applicazioni siano ideenti, non dovrebbero ripetere le operazioni di calcolo per messaggi già elaborati. Un modo popolare per garantire questo è quello di tenere traccia dell’UUID dei messaggi consumati da un servizio in una cache distribuita con ragionevole scadenza (definita in base agli accordi a livello di servizio (SLA). Ogni volta che lo stesso UUID viene riscontrato nell’intervallo di scadenza, l’elaborazione viene saltata.
L’elaborazione su Flink fornisce questa garanzia utilizzando la sua gestione statale interna basata su Rocksdb, con la chiave l’UUID del messaggio. Se vuoi farlo puramente usando Kafka, Kafka Streams offre anche un modo per farlo. Consumo di applicazioni in base all’obiettivo a molla usa EVCAche per raggiungere questo obiettivo.
Monitoraggio dei livelli di servizio delle infrastrutture
Esso’È cruciale che Netflix abbia una visione in tempo reale dei livelli di servizio all’interno della sua infrastruttura. Netflix ha scritto Atlas per gestire i dati delle serie temporali dimensionali, da cui pubblichiamo e visualizzamo le metriche. Usiamo una varietà di metriche pubblicate da produttori, processori e consumatori per aiutarci a costruire un quadro quasi in tempo reale dell’intera infrastruttura.
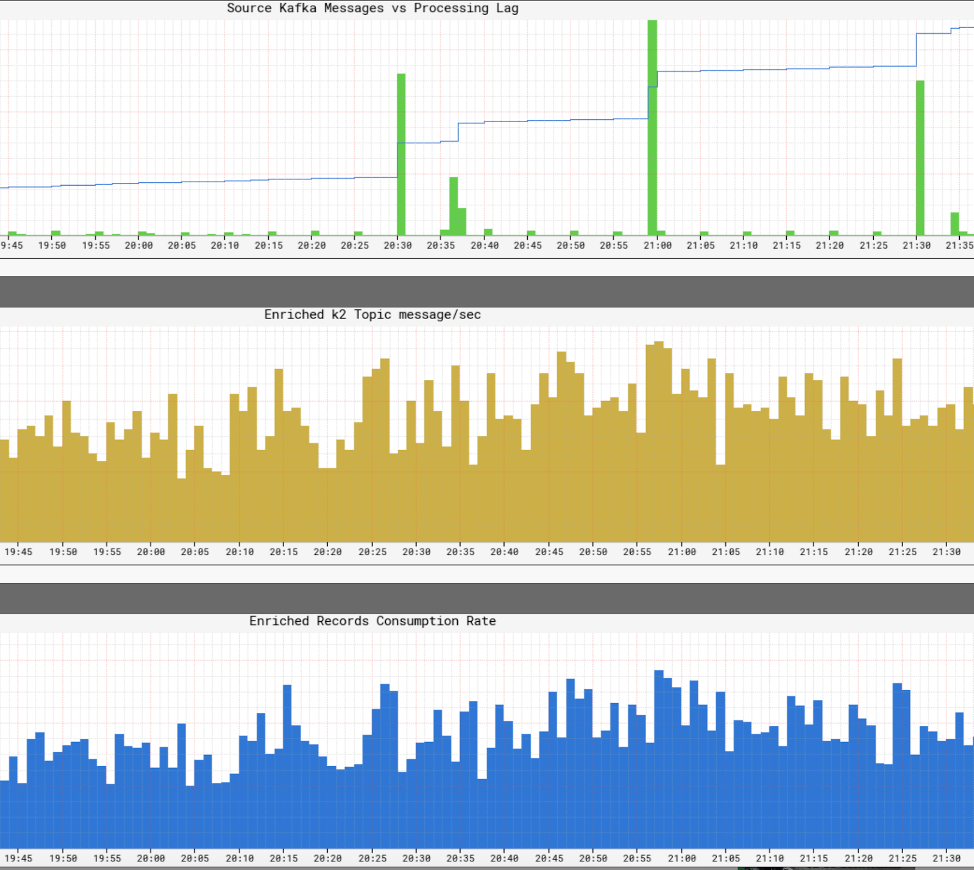
Alcuni degli aspetti chiave che monitoriamo sono:
- Freschezza sla
- Qual è la fine del tempo alla produzione di un evento fino a raggiungere tutti i lavandini?
- Qual è il ritardo di elaborazione per ogni consumatore?
- Quanto è grande un carico utile in grado di inviare?
- Dovremmo comprimere i dati?
- Stiamo utilizzando in modo efficiente le nostre risorse?
- Possiamo consumare più velocemente?
- Siamo in grado di creare un checkpoint per il nostro stato e riprendere in caso di guasti?
- Se non siamo in grado di tenere il passo con l’evento Firehose, possiamo applicare la contropressione alle fonti corrispondenti senza schiantare la nostra applicazione?
- Come affrontiamo gli scoppi di eventi?
- Siamo sufficientemente forniti per soddisfare lo SLA?
Sinossi
Il team di Netflix Studio Productions and Finance abbraccia la governance distribuita come modo di architelare. Usiamo Kafka come piattaforma preferita per lavorare con eventi, che sono un modo immutabile per registrare e derivare lo stato di sistema. Kafka ci ha aiutato a raggiungere maggiori livelli di visibilità e disaccoppiamento nella nostra infrastruttura, aiutandoci a ridimensionare le operazioni organicamente. È al centro della rivoluzionamento dell’infrastruttura dello studio Netflix e con essa, l’industria cinematografica.
Interessato a di più?
Se tu’D mi piace saperne di più, puoi visualizzare la registrazione e le diapositive della presentazione di Eventing di San Francisco di San Francisco – un originale Netflix!
Netflix: come Apache Kafka trasforma i dati da milioni di persone in intelligenza
Netflix ha speso $ 16 miliardi per la produzione di contenuti nel 2020. Nel gennaio 2021, l’app mobile Netflix (iOS e Android) è stata scaricata 19 milioni di volte e un mese dopo, la società ha annunciato di aver colpito 203.66 milioni di abbonati in tutto il mondo. Esso’è sicuro di presumere che la scala dei dati che l’azienda raccoglie e i processi sia enorme. La domanda è –
In che modo Netflix elabora miliardi di record di dati ed eventi per prendere decisioni aziendali critiche?
Con un budget annuale del contenuto del valore di $ 16 miliardi, i decisori di Netflix Aren’che prenderà decisioni relative al contenuto basate sull’intuizione. Invece, i loro curatori di contenuti usano la tecnologia all’avanguardia per dare un senso a enormi quantità di dati sul comportamento degli abbonati, preferenze sui contenuti dell’utente, costi di produzione dei contenuti, tipi di contenuti che funzionano, ecc. Questo elenco continua.
Gli utenti di Netflix spendono in media 3.2 ore al giorno sulla loro piattaforma e sono costantemente alimentati con le ultime consigli di Netflix’S Proprietario motore di raccomandazione. Ciò garantisce che gli abbonati Churn siano bassi e attiri nuovi abbonati a registrarsi. La consegna dei contenuti basata sui dati è al centro e al centro di questo.
Quindi, ciò che sta sotto il cofano dal punto di vista dell’elaborazione dei dati?
In altre parole, in che modo Netflix ha costruito una spina dorsale tecnologica che ha consentito il processo decisionale guidato dai dati su una scala così enorme? Come si ottiene un senso del comportamento dell’utente di 203 milioni di abbonati?
Netflix utilizza ciò che chiama la pipeline di dati Keystone. Nel 2016, questa pipeline stava elaborando 500 miliardi di eventi al giorno. Questi eventi includevano registri degli errori, attività di visualizzazione degli utenti, attività dell’interfaccia utente, eventi di risoluzione dei problemi e molti altri set di dati preziosi.
Secondo Netflix, come pubblicato nel suo blog tecnologico:
La pipeline di Keystone è un evento unificato di pubblicazione, raccolta e infrastruttura di routing sia per l’elaborazione batch e flusso.
I cluster Kafka sono una parte fondamentale della pipeline di dati Keystone a Netflix. Nel 2016, la pipeline Netflix ha utilizzato 36 cluster Kafka per elaborare miliardi di messaggi al giorno.
Quindi, cos’è Apache Kafka? E perché è diventato così popolare?
Apache Kafka è una piattaforma di streaming open source che consente lo sviluppo di applicazioni che ingeriscono un volume elevato di dati in tempo reale. È stato originariamente costruito dai geni di LinkedIn ed è ora utilizzato su Netflix, Pinterest e Airbnb per citarne alcuni.
Kafka fa specificamente quattro cose:
- Consente alle applicazioni di pubblicare o iscriversi a flussi di dati o eventi
- Memorizza i record di dati accuratamente ed è altamente tollerante ai guasti
- È in grado di elaborazione dei dati ad alto volume in tempo reale.
- È in grado di accettare ed elaborare trilioni di record di dati al giorno, senza problemi di prestazioni
I team di sviluppo del software sono in grado di sfruttare Kafka’Capabili S con le seguenti API:
- API produttore: questa API consente a un microservizio o applicazione di pubblicare un flusso di dati su un particolare argomento di Kafka. Un argomento Kafka è un registro che memorizza i record di dati ed eventi nell’ordine in cui si sono verificati.
- API del consumatore: questa API consente a un’applicazione di iscriversi ai flussi di dati da un argomento Kafka. Utilizzando l’API del consumatore, le applicazioni possono ingerire ed elaborare il flusso di dati, che fungerà da input per l’applicazione specificata.
- Streams API: questa API è fondamentale per sofisticate applicazioni di streaming di eventi. In sostanza, consuma flussi di dati da vari argomenti di Kafka ed è in grado di elaborare o trasformare questo secondo necessità. Post-elaborazione, questo flusso di dati è pubblicato su un altro argomento Kafka da utilizzare a valle e/o trasformare un argomento esistente.
- Connector API: nelle moderne applicazioni, è necessario riutilizzare produttori o consumatori e integrare automaticamente una fonte di dati in un cluster Kafka. Kafka Connect lo rende non necessario collegando Kafka ai sistemi esterni.
I principali vantaggi di Kafka
Secondo il sito web di Kafka, l’80% di tutte le aziende Fortune 100 utilizza Kafka. Uno dei principali motivi di ciò è che si adatta bene alle applicazioni mission-critical.
Le principali aziende utilizzano Kafka per i seguenti motivi:
- Consente facilmente il disaccoppiamento di flussi di dati e sistemi
- È progettato per essere distribuito, resistente e tollerante ai guasti
- La scalabilità orizzontale di Kafka è uno dei suoi maggiori vantaggi. Può ridimensionare a 100 di cluster e milioni di messaggi al secondo
- Abilita lo streaming dei dati in tempo reale ad alte prestazioni, un’esigenza critica in su larga scala, applicazioni basate sui dati
Modi in cui kafka viene utilizzato per ottimizzare l’elaborazione dei dati
Kafka viene utilizzato in tutti i settori per una varietà di scopi, tra cui ma non limitato a quanto segue
- Elaborazione dei dati in tempo reale: Oltre al suo utilizzo nelle aziende tecnologiche, Kafka è parte integrante dell’elaborazione dei dati in tempo reale nel settore manifatturiero, dove i dati ad alto volume provengono da un gran numero di dispositivi e sensori IoT
- Monitoraggio del sito Web su scala: Kafka viene utilizzato per monitorare il comportamento degli utenti e l’attività del sito in siti Web ad alto traffico. Aiuta con monitoraggio in tempo reale, elaborazione, connessione con Hadoop e data warehousing offline
- Metriche chiave di monitoraggio: Poiché il kafka può essere utilizzato per aggregare i dati da diverse applicazioni a un feed centralizzato, facilita il monitoraggio di dati operativi ad alto volume
- Aggregazione del registro: Consente di aggregare i dati provenienti da più fonti in un registro per ottenere chiarezza sul consumo distribuito
- Sistema di messaggistica: Automatizza le applicazioni di elaborazione dei messaggi su larga scala
- Elaborazione del flusso: Dopo che gli argomenti di Kafka sono stati consumati come dati grezzi nelle condutture di elaborazione in varie fasi, sono aggregati, arricchiti o trasformati in nuovi argomenti per ulteriori consumi o elaborazione
- Dipendenze del sistema di co-accoppiamento
- Integrazioni Con Spark, Flink, Storm, Hadoop e altre tecnologie di Big Data
Aziende che usano kafka per elaborare i dati
Come risultato della sua versatilità e funzionalità, Kafka è usato da parte del mondo’S per vari scopi le aziende tecnologiche in più rapida crescita:
- Uber-Raccogli i dati di un utente, di taxi e di viaggio in tempo reale per calcolare e prevedere la domanda e calcolare i prezzi delle sovratensioni in tempo reale
- LinkedIn-impedisce lo spam e raccoglie le interazioni utente per formulare raccomandazioni di connessione migliori in tempo reale
- Twitter – Parte della sua infrastruttura di elaborazione del flusso di tempeste
- Spotify – Parte del suo sistema di consegna del registro
- Pinterest – Parte della sua pipeline di raccolta di registro
- Airbnb – Pipeline di eventi, monitoraggio delle eccezioni, ecc.
- Cisco – per OpenSoc (Security Operations Center)
Gruppo di merito’competenza in kafka
In Merit Group, lavoriamo con un po ‘del mondo’S principali compagnie di intelligence B2B come Wilmington, Dow Jones, Glenigan e Haymarket. I nostri team di dati e ingegneria lavorano a stretto contatto con i nostri clienti per creare prodotti di dati e strumenti di business intelligence. Il nostro lavoro influisce direttamente sulla crescita del business aiutando i nostri clienti a identificare opportunità ad alta crescita.
I nostri servizi specifici includono raccolta di dati ad alto volume, trasformazione dei dati utilizzando AI e ML, Web watching e sviluppo di applicazioni personalizzate.
Il nostro team porta inoltre alla tabella una profonda competenza nella creazione di applicazioni di streaming di dati e elaborazione dei dati in tempo reale. La nostra esperienza in Kafka è particolarmente utile in questo contesto.
Пубnare confluente
Ai sistemi di architetti che registrano e derivano lo stato di sistema, Netflix sfrutta Apache Kafka e distribuisce governance. Nitin s. condivide come questo li aiuta a raggiungere la visibilità e il disaccoppiamento nella loro infrastruttura mentre si ridimensionano le operazioni: https: // lnkd.in/gfxaa6g
Come Netflix utilizza Kafka per lo streaming distribuito
confluente.io
- Копировать
Credente, marito, padre di 5 anni, responsabile dell’infrastruttura e dei servizi IT, leader del team, sviluppatore.
Netflix crea una piattaforma affidabile e scalabile con eventi di approvvigionamento, MQTT e Alpakka-Kafka
Netflix ha recentemente pubblicato un post sul blog in dettaglio come ha creato una piattaforma di gestione dei dispositivi affidabile utilizzando un’implementazione di sourcing di eventi basata su MQTT. Per ridimensionare la sua soluzione, Netflix utilizza Apache Kafka, Alpakka-Kafka e Cockroachdb.
La piattaforma di gestione dei dispositivi di Netflix è il sistema che gestisce i dispositivi hardware utilizzati per i test automatizzati delle sue applicazioni. Gli ingegneri di Netflix Benson Ma e Alok Ahuja descrivono il viaggio che la piattaforma ha attraversato:
L’elaborazione dei flussi di kafka può essere difficile da ottenere. (. ) Fortunatamente, i primitivi forniti da Akka Streams e Alpakka-Kafka ci consentono di raggiungere esattamente questo permettendoci di costruire soluzioni di streaming che corrispondono ai flussi di lavoro aziendali che abbiamo mentre aumentano la produttività degli sviluppatori nella costruzione e nel mantenimento di queste soluzioni. Con il processore basato su Alpakka-Kafka in atto (. ).
(. ) L’affidabilità della piattaforma e del suo piano di controllo si basano su un lavoro significativo svolto in diverse aree, tra cui il trasporto MQTT, l’autenticazione e l’autorizzazione e il monitoraggio dei sistemi. (. ) Come risultato di questo lavoro, possiamo aspettarci che la piattaforma di gestione dei dispositivi continui a scalare per aumentare i carichi di lavoro nel tempo mentre a bordo sempre più dispositivi nei nostri sistemi.
Il seguente diagramma raffigura l’architettura.

Fonte: https: // netflixtechblog.com/over-a-affidabile-device-management-platform-4f86230ca623
Un computer incorporato di Automtion Environment (RAE) locale si collega a più dispositivi in Test (DUT). Il servizio di registro locale è responsabile del rilevamento, dell’onboarding e della manutenzione di informazioni su tutti i dispositivi connessi sulla RAE. Poiché gli attributi e le proprietà del dispositivo cambiano nel tempo, salva queste modifiche al registro locale e contemporaneamente pubblicati a monte su un piano di controllo basato su cloud. Oltre alle modifiche agli attributi, il registro locale pubblica un’istantanea completa del record del dispositivo a intervalli regolari. Questi eventi di checkpoint consentono una ricostruzione statale più veloce da parte dei consumatori del feed di dati mentre si proteggono dagli aggiornamenti mancati.
Gli aggiornamenti vengono pubblicati nel cloud utilizzando MQTT. MQTT è un protocollo di messaggistica standard Oasis per Internet of Things (IoT). È un trasporto di messaggistica pubblica/iscrizione leggero ma affidabile ideale per collegare dispositivi remoti con un’impronta di codice ridotta e una larghezza di banda di rete minima. Il broker MQTT è responsabile della ricezione di tutti i messaggi, filtrarli e inviarli di conseguenza ai clienti abbonati.
Netflix utilizza Apache Kafka in tutta l’organizzazione. Di conseguenza, un ponte converte i messaggi MQTT ai record di Kafka. Imposta la chiave di record sull’argomento MQTT che è stato assegnato il messaggio. Ma e Ahuja descrivono che “dagli aggiornamenti dei dispositivi pubblicati su MQTT contengono il dispositivo_session_id Nell’argomento, tutti gli aggiornamenti delle informazioni sul dispositivo per una determinata sessione del dispositivo appariranno effettivamente sulla stessa partizione Kafka, dandoci così un ordine di messaggio ben definito per il consumo.”
Il registro del cloud ingerisce i messaggi pubblicati, li elabora e spinge i dati materializzati in un dataStore sostenuto da CockroachDB. CockroachDB è un’implementazione di una classe di sistemi RDBMS chiamati Newsql. Ma e Ahuja spiegano la scelta di Netflix:
CockroachDB è scelto come archivio di dati di supporto poiché ha offerto funzionalità SQL e il nostro modello di dati per i record del dispositivo è stato normalizzato. Inoltre, a differenza di altri negozi di SQL, CockroachDB è progettato da zero per essere scalabile orizzontalmente, il che affronta le nostre preoccupazioni sulla capacità del Registro di cloud di aumentare il numero di dispositivi on -bordo sulla piattaforma di gestione dei dispositivi.
Il diagramma seguente mostra la pipeline di elaborazione Kafka che comprende il registro delle nuvole.
Fonte: https: // netflixtechblog.com/over-a-affidabile-device-management-platform-4f86230ca623
Netflix ha considerato molti framework per l’implementazione delle condotte di elaborazione del flusso raffigurate sopra. Questi quadri includono corsi d’acqua Kafka, Kafkalistener primaverile, reattore del progetto e flink. Alla fine ha scelto Alpakka-Kafka. Il motivo di questa scelta è che Alpakka-Kafka fornisce l’integrazione di avvio a molla insieme al “controllo a grana fine sull’elaborazione del flusso, incluso il supporto automatico di back-pressione e la supervisione dei flussi.”Inoltre, secondo MA e Ahuja, Akka e Alpakka-Kafka sono più leggeri delle alternative e poiché sono più maturi, i costi di manutenzione nel tempo saranno più bassi.
L’implementazione basata su Alpakka-Kafka ha sostituito una precedente implementazione basata su Kafkalister primaverili. Le metriche misurate sulla nuova implementazione della produzione rivelano che il supporto di back-pressione nativo di Alpakka-Kafka può ridimensionare dinamicamente il suo consumo di Kafka. A differenza di Kafkalistener, Alpakka-Kafka non consuma o consuma eccessivamente i messaggi Kafka. Inoltre, un calo dei valori massimi di ritardo del consumatore a seguito del rilascio ha rivelato che Alpakka-Kafka e le capacità di streaming di Akka funzionano bene su scala, anche di fronte a improvvisi carichi di messaggi.

