


Χρησιμοποιεί το Netflix Kafka?
Διαθέτει το Apache Kafka στο Netflix Studio και Finance World
Περίληψη:
Στο Netflix, οι περισσότερες εφαρμογές χρησιμοποιούν τη βιβλιοθήκη πελατών Java για να παράγουν δεδομένα στον αγωγό Keystone. Ο αγωγός αποτελείται από συστάδες Kafka, υπεύθυνο για τη συλλογή και αποθήκευση δεδομένων, καθώς και τα clusters καταναλωτών Kafka, που περιέχουν θέματα για καταναλωτές σε πραγματικό χρόνο. Η Netflix διαθέτει συνολικά 36 συστάδες Kafka που χειρίζονται περισσότερα από 700 δισεκατομμύρια μηνύματα καθημερινά. Για να επιτευχθεί η παράδοση χωρίς απώλειες, ο αγωγός επιτρέπει ένα ποσοστό απώλειας δεδομένων μικρότερο από 0.01%. Οι παραγωγοί και οι μεσίτες έχουν ρυθμιστεί ώστε να διασφαλίζουν τη διαθεσιμότητα και την καλή εμπειρία των χρηστών.
Βασικά σημεία:
- Οι εφαρμογές Netflix χρησιμοποιούν τη βιβλιοθήκη πελατών Java για να παράγουν δεδομένα στον αγωγό Keystone
- Υπάρχουν πολλοί παραγωγοί Kafka σε κάθε περίπτωση εφαρμογής
- Fronting Kafka clusters συλλέγουν και buffer μηνύματα
- Οι συστάδες καταναλωτών Kafka περιέχουν θέματα για καταναλωτές σε πραγματικό χρόνο
- Το Netflix λειτουργεί 36 συστάδες Kafka με πάνω από 700 δισεκατομμύρια μηνύματα καθημερινά
- Το ποσοστό απώλειας δεδομένων είναι μικρότερο από 0.01%
- Οι παραγωγοί και οι μεσίτες έχουν ρυθμιστεί ώστε να διασφαλίζουν τη διαθεσιμότητα
- Οι παραγωγοί χρησιμοποιούν δυναμική διαμόρφωση για δρομολόγηση θεμάτων και απομόνωση νεροχύτη
- Οι εφαρμογές μη-Java μπορούν να στείλουν συμβάντα σε τελικά σημεία ανάπαυσης Keystone
- Η παραγγελία μηνυμάτων καθορίζεται στην επεξεργασία παρτίδων ή στο στρώμα δρομολόγησης
Ερωτήσεις:
- Πώς οι εφαρμογές Netflix παράγουν δεδομένα στον αγωγό Keystone?
- Ποιοι είναι οι ρόλοι των ομάδων Kafka?
- Ποιοι τύποι συστάδων Kafka υπάρχουν στον αγωγό Keystone?
- Πόσα συστάδες Kafka λειτουργεί το Netflix?
- Ποιο είναι το μέσο ποσοστό κατάποσης δεδομένων για το Netflix?
- Ποια είναι η τρέχουσα έκδοση του Kafka που χρησιμοποιείται από το Netflix?
- Πώς επιτυγχάνει η Netflix χωρίς απώλεια παράδοσης?
- Ποια είναι η διαμόρφωση για τους παραγωγούς και τους μεσίτες για να εξασφαλίσουν τη διαθεσιμότητα?
- Πώς διατηρείται η παραγγελία μηνυμάτων?
- Γιατί οι εφαρμογές πελατών δεν καταναλώνονται απευθείας από τα συστάδες Kafka?
- Τι προκύπτουν προκλήσεις όταν τρέχετε Kafka στο σύννεφο?
- Πώς επηρεάζει η αντιγραφή τη διαθεσιμότητα του Kafka?
- Τι έχει γίνει το Netflix για την αντιμετώπιση συμβάντων και τη διατήρηση της σταθερότητας των συμπλέγματος?
- Ποια είναι η στρατηγική ανάπτυξης της Netflix για τα clusters Kafka?
Οι περισσότερες εφαρμογές Netflix χρησιμοποιούν τη βιβλιοθήκη πελατών Java για να παράγουν δεδομένα στον αγωγό Keystone. Κάθε παρουσία εφαρμογής έχει πολλούς παραγωγούς Kafka.
Fronting Kafka Συλλόγους συλλέγουν μηνύματα και μηνύματα buffer από τους παραγωγούς. Χρησιμεύουν ως πύλη για ένεση μηνυμάτων.
Ο αγωγός Keystone αποτελείται από συστάδες Kafka και συστάδες καταναλωτή Kafka.
Το Netflix λειτουργεί 36 συστάδες Kafka.
Η Netflix καταπιεί πάνω από 700 δισεκατομμύρια μηνύματα καθημερινά.
Η Netflix μεταβαίνει από την έκδοση Kafka 0.8.2.1 έως 0.9.0.1.
Λογίζοντας τον τεράστιο όγκο δεδομένων, η Netflix συνεργάστηκε με τις ομάδες για να δεχτεί μια αποδεκτή απώλεια δεδομένων, με αποτέλεσμα ένα ποσοστό απώλειας δεδομένων ημερήσιας δεδομένων μικρότερο από 0.01%.
Οι παραγωγοί και οι μεσίτες έχουν ρυθμιστεί με “ACKS = 1”, “Block.επί.ρυθμιστής.πλήρης = ψευδής “, και” ακάθαρτη.ηγέτης.εκλογή.Ενεργοποίηση = true “.
Οι παραγωγοί δεν χρησιμοποιούν μηνύματα κλειδιού και η παραγγελία μηνυμάτων αποκαθίσταται στο στρώμα επεξεργασίας παρτίδας ή στο στρώμα δρομολόγησης.
Οι εφαρμογές πελατών δεν επιτρέπεται να καταναλώνουν άμεσα από τα συστάδες Kafka για να εξασφαλίσουν προβλέψιμο φορτίο και σταθερότητα.
Η εκτέλεση του Kafka στο σύννεφο δημιουργεί προκλήσεις όπως ο απρόβλεπτος κύκλος ζωής, τα μεταβατικά ζητήματα δικτύωσης και οι υπερβολές που προκαλούν προβλήματα απόδοσης.
Η αντιγραφή βελτιώνει τη διαθεσιμότητα, αλλά ένας μεσίτης εξωραϊσμού μπορεί να προκαλέσει καταρράκτες και πτώση μηνυμάτων λόγω της καθυστέρησης αναπαραγωγής και της εξάντλησης του buffer.
Η Netflix μείωσε την κατάσταση και την πολυπλοκότητα, εφάρμοσε την ανίχνευση εξωραϊσμού και αναπτύχθηκε μέτρα για να ανακάμψει γρήγορα από περιστατικά.
Το Netflix ευνοεί πολλαπλές μικρές συστάδες Kafka σε ένα γιγαντιαίο σύμπλεγμα για να μειώσουν τις εξαρτήσεις και να βελτιώσουν τη σταθερότητα.
Kafka μέσα στον αγωγό Keystone
Έχουμε δύο σετ Kafka Clusters στο Keystone Pipeline: Fronting Kafka και καταναλωτή Kafka. Οι ομάδες Kafka είναι υπεύθυνα για τη λήψη των μηνυμάτων από τους παραγωγούς που είναι σχεδόν κάθε παρουσία εφαρμογής στο Netflix. Οι ρόλοι τους είναι η συλλογή δεδομένων και το buffering για τα κατάντη συστήματα. Οι συστάδες καταναλωτών Kafka περιέχουν ένα υποσύνολο θεμάτων που δρομολογούνται από τη Samza για καταναλωτές σε πραγματικό χρόνο.
Αυτή τη στιγμή λειτουργούμε 36 συστάδες Kafka που αποτελούνται από 4.000+ περιπτώσεις μεσίτη για τόσο για το Kafka όσο και για τον καταναλωτή Kafka. Περισσότερα από 700 δισεκατομμύρια μηνύματα καταναλώνονται σε μια μέση ημέρα. Αυτήν τη στιγμή μεταβαίνουν από την έκδοση Kafka 0.8.2.1 έως 0.9.0.1.
Αρχές σχεδιασμού
Δεδομένης της τρέχουσας αρχιτεκτονικής Kafka και του τεράστιου όγκου δεδομένων μας, για να επιτύχουμε την παράδοση χωρίς απώλειες για τον αγωγό δεδομένων μας είναι απαγορευτικό στο AWS EC2. Λογιστική για αυτό, εμείς’Η VE συνεργάστηκε με ομάδες που εξαρτώνται από την υποδομή μας για να φτάσουν σε αποδεκτή απώλεια δεδομένων, ενώ εξισορροπώντας το κόστος. Εμείς’έχει επιτύχει ένα ημερήσιο ποσοστό απώλειας δεδομένων μικρότερο από 0.01%. Οι μετρήσεις συγκεντρώνονται για μηνύματα που έχουν υποχωρήσει, ώστε να μπορέσουμε να αναλάβουμε δράση αν χρειαστεί.
Ο αγωγός Keystone παράγει μηνύματα ασύγχρονα χωρίς παρεμπόδιση εφαρμογών. Σε περίπτωση που ένα μήνυμα δεν μπορεί να παραδοθεί μετά από επαναλήψεις, θα πέσει από τον παραγωγό για να εξασφαλίσει τη διαθεσιμότητα της εφαρμογής και της καλής εμπειρίας των χρηστών. Γι ‘αυτό έχουμε επιλέξει την ακόλουθη διαμόρφωση για τον παραγωγό και τον μεσίτη μας:
- ACKS = 1
- ΟΙΚΟΔΟΜΙΚΟ ΤΕΤΡΑΓΩΝΟ.επί.ρυθμιστής.Πλήρης = ψευδής
- ακάθαρτος.ηγέτης.εκλογή.Ενεργοποίηση = αλήθεια
Οι περισσότερες από τις εφαρμογές στο Netflix χρησιμοποιούν τη βιβλιοθήκη πελατών Java για να παράγουν στον αγωγό Keystone. Σε κάθε περίπτωση αυτών των εφαρμογών, υπάρχουν πολλοί παραγωγοί Kafka, με κάθε ένα να παράγει ένα fronting kafka cluster για απομόνωση επιπέδου νεροχύτη. Οι παραγωγοί έχουν ευέλικτη διαμόρφωση δρομολόγησης θεμάτων και νεροχύτη που οδηγούνται μέσω δυναμικής διαμόρφωσης που μπορεί να αλλάξει κατά το χρόνο εκτέλεσης χωρίς να χρειάζεται να επανεκκινήσει τη διαδικασία εφαρμογής. Αυτό επιτρέπει τα πράγματα όπως η ανακατεύθυνση της κυκλοφορίας και τα θέματα μετανάστευσης σε συστάδες Kafka. Για εφαρμογές εκτός Java, μπορούν να επιλέξουν να στείλουν συμβάντα σε τελικά σημεία REST Keystone, τα οποία αναμεταδίδουν μηνύματα για να φτιάχνουν συστάδες Kafka.
Για μεγαλύτερη ευελιξία, οι παραγωγοί δεν χρησιμοποιούν μηνύματα κλειδιού. Η κατά προσέγγιση παραγγελία μηνυμάτων αποκαθίσταται στο στρώμα επεξεργασίας παρτίδας (Hive / Elasticsearch) ή στο στρώμα δρομολόγησης για ροή καταναλωτών.
Βάζουμε τη σταθερότητα των ομάδων Kafka σε υψηλή προτεραιότητα επειδή είναι η πύλη για ένεση μηνύματος. Ως εκ τούτου, δεν επιτρέπουμε στις εφαρμογές πελατών να καταναλώνουν άμεσα από αυτούς για να βεβαιωθούν ότι έχουν προβλέψιμο φορτίο.
Προκλήσεις της λειτουργίας Kafka στο σύννεφο
Το Kafka αναπτύχθηκε με το κέντρο δεδομένων ως στόχος ανάπτυξης στο LinkedIn. Έχουμε καταβάλει αξιοσημείωτες προσπάθειες για να κάνουμε το Kafka να τρέχει καλύτερα στο σύννεφο.
Στο σύννεφο, οι περιπτώσεις έχουν έναν απρόβλεπτο κύκλο ζωής και μπορούν να τερματιστούν ανά πάσα στιγμή λόγω προβλημάτων υλικού. Αναμένονται ζητήματα παροδικής δικτύωσης. Αυτά δεν είναι προβλήματα για τις υπηρεσίες απάθειας, αλλά αποτελούν μεγάλη πρόκληση για μια κρατική υπηρεσία που απαιτεί zookeeper και έναν μόνο ελεγκτή για συντονισμό.
Τα περισσότερα από τα ζητήματά μας ξεκινούν με μεσίτες Outlier. Μια απόκλιση μπορεί να προκληθεί από άνιση φόρτο εργασίας, προβλήματα υλικού ή το συγκεκριμένο περιβάλλον του, για παράδειγμα, θορυβώδεις γείτονες λόγω πολλαπλών ενοικιαστών. Ένας μεσίτης απόκλισης μπορεί να έχει αργές απαντήσεις σε αιτήματα ή συχνές χρονικές όψεις TCP/retransmissionions. Οι παραγωγοί που στέλνουν εκδηλώσεις σε έναν τέτοιο μεσίτη θα έχουν καλή ευκαιρία να εξαντλήσουν τα τοπικά buffers τους, ενώ περιμένουν απαντήσεις, μετά από την οποία η πτώση μηνυμάτων γίνεται βεβαιότητα. Ο άλλος παράγοντας που συμβάλλει στην εξάντληση του buffer είναι ότι το kafka 0.8.2 παραγωγός δεν’t Χρονικό όριο υποστήριξης για μηνύματα που περιμένουν στο buffer.
Καφκά’Η αναπαραγωγή S βελτιώνει τη διαθεσιμότητα. Ωστόσο, η αντιγραφή οδηγεί σε αλληλένδετες μεταξύ των μεσίων όπου ένα απόκλιση μπορεί να προκαλέσει φαινόμενο Cascading. Εάν ένα outlier επιβραδύνει την αναπαραγωγή, η υστέρηση αναπαραγωγής μπορεί να δημιουργηθεί και τελικά να προκαλέσει τους ηγέτες διαμερισμάτων να διαβάζουν από το δίσκο για να εξυπηρετήσουν τα αιτήματα αναπαραγωγής. Αυτό επιβραδύνει τους επηρεαζόμενους μεσίτες και τελικά οδηγεί σε παραγωγούς που πέφτουν μηνύματα λόγω εξαντλημένου buffer όπως εξηγείται σε προηγούμενες περιπτώσεις.
Κατά τη διάρκεια των πρώτων ημερών λειτουργίας του Kafka, βιώσαμε ένα περιστατικό όπου οι παραγωγοί έριχναν ένα σημαντικό αριθμό μηνυμάτων σε ένα σύμπλεγμα Kafka με εκατοντάδες περιπτώσεις λόγω ενός ζητήματος zookeeper, ενώ δεν μπορούσαμε να κάνουμε λίγα. Τα θέματα εντοπισμού σφαλμάτων όπως αυτό σε ένα μικρό χρονικό παράθυρο με εκατοντάδες μεσίτες δεν είναι απλά ρεαλιστικά.
Μετά το περιστατικό, καταβλήθηκαν προσπάθειες για τη μείωση της κρατικής και πολυπλοκότητας για τα συστάδες μας Kafka, την ανίχνευση των υπερβολικών τιμών και την εύρεση ενός τρόπου να ξεκινήσουμε γρήγορα με μια καθαρή κατάσταση όταν εμφανιστεί ένα περιστατικό.
Στρατηγική ανάπτυξης Kafka
Τα παρακάτω είναι οι βασικές στρατηγικές που χρησιμοποιήσαμε για την ανάπτυξη ομάδων Kafka:
- Προτιμήστε πολλές μικρές συστάδες Kafka σε αντίθεση με ένα γιγαντιαίο σύμπλεγμα. Αυτό μειώνει τις εξαρτήσεις και βελτιώνει τη σταθερότητα.
- Εφαρμόστε μηχανισμούς ανίχνευσης εξωγήινων για τον εντοπισμό και τη διαχείριση προβληματικών μεσιτών.
- Αναπτύξτε μέτρα για να ανακάμψετε γρήγορα από περιστατικά και ξεκινήστε με καθαρή κατάσταση.
Διαθέτει το Apache Kafka στο Netflix Studio και Finance World
Οι περισσότερες από τις εφαρμογές στο Netflix χρησιμοποιούν τη βιβλιοθήκη πελατών Java για να παράγουν στον αγωγό Keystone. Σε κάθε περίπτωση αυτών των εφαρμογών, υπάρχουν πολλοί παραγωγοί Kafka, με κάθε ένα να παράγει ένα fronting kafka cluster για απομόνωση επιπέδου νεροχύτη. Οι παραγωγοί έχουν ευέλικτη διαμόρφωση δρομολόγησης θεμάτων και νεροχύτη που οδηγούνται μέσω δυναμικής διαμόρφωσης που μπορεί να αλλάξει κατά το χρόνο εκτέλεσης χωρίς να χρειάζεται να επανεκκινήσει τη διαδικασία εφαρμογής. Αυτό επιτρέπει τα πράγματα όπως η ανακατεύθυνση της κυκλοφορίας και τα θέματα μετανάστευσης σε συστάδες Kafka. Για εφαρμογές εκτός Java, μπορούν να επιλέξουν να στείλουν συμβάντα σε τελικά σημεία REST Keystone, τα οποία αναμεταδίδουν μηνύματα για να φτιάχνουν συστάδες Kafka.
Kafka μέσα στον αγωγό Keystone
Έχουμε δύο σετ Kafka Clusters στο Keystone Pipeline: Fronting Kafka και καταναλωτή Kafka. Οι ομάδες Kafka είναι υπεύθυνα για τη λήψη των μηνυμάτων από τους παραγωγούς που είναι σχεδόν κάθε παρουσία εφαρμογής στο Netflix. Οι ρόλοι τους είναι η συλλογή δεδομένων και το buffering για τα κατάντη συστήματα. Οι συστάδες καταναλωτών Kafka περιέχουν ένα υποσύνολο θεμάτων που δρομολογούνται από τη Samza για καταναλωτές σε πραγματικό χρόνο.
Αυτή τη στιγμή λειτουργούμε 36 συστάδες Kafka που αποτελούνται από 4.000+ περιπτώσεις μεσίτη για τόσο για το Kafka όσο και για τον καταναλωτή Kafka. Περισσότερα από 700 δισεκατομμύρια μηνύματα καταναλώνονται σε μια μέση ημέρα. Αυτήν τη στιγμή μεταβαίνουν από την έκδοση Kafka 0.8.2.1 έως 0.9.0.1.
Αρχές σχεδιασμού
Δεδομένης της τρέχουσας αρχιτεκτονικής Kafka και του τεράστιου όγκου δεδομένων μας, για να επιτύχουμε την παράδοση χωρίς απώλειες για τον αγωγό δεδομένων μας είναι απαγορευτικό στο AWS EC2. Λογιστική για αυτό, εμείς’Η VE συνεργάστηκε με ομάδες που εξαρτώνται από την υποδομή μας για να φτάσουν σε αποδεκτή απώλεια δεδομένων, ενώ εξισορροπώντας το κόστος. Εμείς’έχει επιτύχει ένα ημερήσιο ποσοστό απώλειας δεδομένων μικρότερο από 0.01%. Οι μετρήσεις συγκεντρώνονται για μηνύματα που έχουν υποχωρήσει, ώστε να μπορέσουμε να αναλάβουμε δράση αν χρειαστεί.
Ο αγωγός Keystone παράγει μηνύματα ασύγχρονα χωρίς παρεμπόδιση εφαρμογών. Σε περίπτωση που ένα μήνυμα δεν μπορεί να παραδοθεί μετά από επαναλήψεις, θα πέσει από τον παραγωγό για να εξασφαλίσει τη διαθεσιμότητα της εφαρμογής και της καλής εμπειρίας των χρηστών. Γι ‘αυτό έχουμε επιλέξει την ακόλουθη διαμόρφωση για τον παραγωγό και τον μεσίτη μας:
- ACKS = 1
- ΟΙΚΟΔΟΜΙΚΟ ΤΕΤΡΑΓΩΝΟ.επί.ρυθμιστής.Πλήρης = ψευδής
- ακάθαρτος.ηγέτης.εκλογή.Ενεργοποίηση = αλήθεια
Οι περισσότερες από τις εφαρμογές στο Netflix χρησιμοποιούν τη βιβλιοθήκη πελατών Java για να παράγουν στον αγωγό Keystone. Σε κάθε περίπτωση αυτών των εφαρμογών, υπάρχουν πολλοί παραγωγοί Kafka, με κάθε ένα να παράγει ένα fronting kafka cluster για απομόνωση επιπέδου νεροχύτη. Οι παραγωγοί έχουν ευέλικτη διαμόρφωση δρομολόγησης θεμάτων και νεροχύτη που οδηγούνται μέσω δυναμικής διαμόρφωσης που μπορεί να αλλάξει κατά το χρόνο εκτέλεσης χωρίς να χρειάζεται να επανεκκινήσει τη διαδικασία εφαρμογής. Αυτό επιτρέπει τα πράγματα όπως η ανακατεύθυνση της κυκλοφορίας και τα θέματα μετανάστευσης σε συστάδες Kafka. Για εφαρμογές εκτός Java, μπορούν να επιλέξουν να στείλουν συμβάντα σε τελικά σημεία REST Keystone, τα οποία αναμεταδίδουν μηνύματα για να φτιάχνουν συστάδες Kafka.
Για μεγαλύτερη ευελιξία, οι παραγωγοί δεν χρησιμοποιούν μηνύματα κλειδιού. Η κατά προσέγγιση παραγγελία μηνυμάτων αποκαθίσταται στο στρώμα επεξεργασίας παρτίδας (Hive / Elasticsearch) ή στο στρώμα δρομολόγησης για ροή καταναλωτών.
Βάζουμε τη σταθερότητα των ομάδων Kafka σε υψηλή προτεραιότητα επειδή είναι η πύλη για ένεση μηνύματος. Ως εκ τούτου, δεν επιτρέπουμε στις εφαρμογές πελατών να καταναλώνουν άμεσα από αυτούς για να βεβαιωθούν ότι έχουν προβλέψιμο φορτίο.
Προκλήσεις της λειτουργίας Kafka στο σύννεφο
Το Kafka αναπτύχθηκε με το κέντρο δεδομένων ως στόχος ανάπτυξης στο LinkedIn. Έχουμε καταβάλει αξιοσημείωτες προσπάθειες για να κάνουμε το Kafka να τρέχει καλύτερα στο σύννεφο.
Στο σύννεφο, οι περιπτώσεις έχουν έναν απρόβλεπτο κύκλο ζωής και μπορούν να τερματιστούν ανά πάσα στιγμή λόγω προβλημάτων υλικού. Αναμένονται ζητήματα παροδικής δικτύωσης. Αυτά δεν είναι προβλήματα για τις υπηρεσίες απάθειας, αλλά αποτελούν μεγάλη πρόκληση για μια κρατική υπηρεσία που απαιτεί zookeeper και έναν μόνο ελεγκτή για συντονισμό.
Τα περισσότερα από τα ζητήματά μας ξεκινούν με μεσίτες Outlier. Μια απόκλιση μπορεί να προκληθεί από άνιση φόρτο εργασίας, προβλήματα υλικού ή το συγκεκριμένο περιβάλλον του, για παράδειγμα, θορυβώδεις γείτονες λόγω πολλαπλών ενοικιαστών. Ένας μεσίτης απόκλισης μπορεί να έχει αργές απαντήσεις σε αιτήματα ή συχνές χρονικές όψεις TCP/retransmissionions. Οι παραγωγοί που στέλνουν εκδηλώσεις σε έναν τέτοιο μεσίτη θα έχουν καλή ευκαιρία να εξαντλήσουν τα τοπικά buffers τους, ενώ περιμένουν απαντήσεις, μετά από την οποία η πτώση μηνυμάτων γίνεται βεβαιότητα. Ο άλλος παράγοντας που συμβάλλει στην εξάντληση του buffer είναι ότι το kafka 0.8.2 παραγωγός δεν’t Χρονικό όριο υποστήριξης για μηνύματα που περιμένουν στο buffer.
Καφκά’Η αναπαραγωγή S βελτιώνει τη διαθεσιμότητα. Ωστόσο, η αντιγραφή οδηγεί σε αλληλένδετες μεταξύ των μεσίων όπου ένα απόκλιση μπορεί να προκαλέσει φαινόμενο Cascading. Εάν ένα outlier επιβραδύνει την αναπαραγωγή, η υστέρηση αναπαραγωγής μπορεί να δημιουργηθεί και τελικά να προκαλέσει τους ηγέτες διαμερισμάτων να διαβάζουν από το δίσκο για να εξυπηρετήσουν τα αιτήματα αναπαραγωγής. Αυτό επιβραδύνει τους επηρεαζόμενους μεσίτες και τελικά οδηγεί σε παραγωγούς που πέφτουν μηνύματα λόγω εξαντλημένου buffer όπως εξηγείται σε προηγούμενες περιπτώσεις.
Κατά τη διάρκεια των πρώτων ημερών λειτουργίας του Kafka, βιώσαμε ένα περιστατικό όπου οι παραγωγοί έριχναν ένα σημαντικό αριθμό μηνυμάτων σε ένα σύμπλεγμα Kafka με εκατοντάδες περιπτώσεις λόγω ενός ζητήματος zookeeper, ενώ δεν μπορούσαμε να κάνουμε λίγα. Τα θέματα εντοπισμού σφαλμάτων όπως αυτό σε ένα μικρό χρονικό παράθυρο με εκατοντάδες μεσίτες δεν είναι απλά ρεαλιστικά.
Μετά το περιστατικό, καταβλήθηκαν προσπάθειες για τη μείωση της κρατικής και πολυπλοκότητας για τα συστάδες μας Kafka, την ανίχνευση των υπερβολικών τιμών και την εύρεση ενός τρόπου να ξεκινήσουμε γρήγορα με μια καθαρή κατάσταση όταν εμφανιστεί ένα περιστατικό.
Στρατηγική ανάπτυξης Kafka
Τα παρακάτω είναι οι βασικές στρατηγικές που χρησιμοποιήσαμε για την ανάπτυξη ομάδων kafka
- Προτιμήστε πολλές μικρές συστάδες Kafka σε αντίθεση με ένα γιγαντιαίο σύμπλεγμα. Αυτό μειώνει την επιχειρησιακή πολυπλοκότητα για κάθε σύμπλεγμα. Το μεγαλύτερο σύμπλεγμα μας έχει λιγότερους από 200 μεσίτες.
- Περιορίστε τον αριθμό των διαμερισμάτων σε κάθε σύμπλεγμα. Κάθε σύμπλεγμα έχει λιγότερα από 10.000 χωρίσματα. Αυτό βελτιώνει τη διαθεσιμότητα και μειώνει την καθυστέρηση για αιτήματα/απαντήσεις που συνδέονται με τον αριθμό των διαμερισμάτων.
- Προσπαθήστε για ομοιόμορφη διανομή αντιγράφων για κάθε θέμα. Ακόμα και ο φόρτος εργασίας είναι ευκολότερο για τον προγραμματισμό χωρητικότητας και την ανίχνευση των υπερβολικών τιμών.
- Χρησιμοποιήστε το αποκλειστικό σύμπλεγμα zookeeper για κάθε σύμπλεγμα Kafka για να μειώσετε την επίδραση των ζητημάτων zookeper.
Ο παρακάτω πίνακας δείχνει τις διαμορφώσεις ανάπτυξής μας.
Kafka Failover
Αυτοματοποιήσαμε μια διαδικασία όπου μπορούμε να αποκαταστήσουμε τόσο την κυκλοφορία παραγωγών όσο και καταναλωτή (δρομολογητή) σε ένα νέο σύμπλεγμα Kafka όταν το κύριο σύμπλεγμα έχει πρόβλημα. Για κάθε σύμπλεγμα Kafka, υπάρχει ένα cluster cold standby με την επιθυμητή διαμόρφωση εκτόξευσης, αλλά ελάχιστη αρχική χωρητικότητα. Για να εξασφαλιστεί μια καθαρή κατάσταση για να ξεκινήσει, το σύμπλεγμα αποτυχίας δεν έχει θέματα που δημιουργούνται και δεν μοιράζονται το σύμπλεγμα Zookeeper με το κύριο σύμπλεγμα Kafka. Το σύμπλεγμα αποτυχίας έχει επίσης σχεδιαστεί για να έχει παράγοντα αναπαραγωγής 1 έτσι ώστε να είναι απαλλαγμένο από τυχόν προβλήματα αναπαραγωγής που μπορεί να έχει το αρχικό σύμπλεγμα.
Όταν συμβεί το Failover, λαμβάνονται τα ακόλουθα βήματα για την εκτροπή της κυκλοφορίας των παραγωγών και των καταναλωτών:
- Αλλάξτε το μέγεθος του συμπλέγματος αποτυχίας στο επιθυμητό μέγεθος.
- Δημιουργήστε θέματα και εκκίνηση εργασιών δρομολόγησης για το σύμπλεγμα αποτυχίας παράλληλα.
- (Προαιρετικά) Περιμένετε τους ηγέτες των διαμερισμάτων να καθιερωθούν από τον ελεγκτή για να ελαχιστοποιήσουν την αρχική πτώση μηνυμάτων κατά την παραγωγή του σε αυτό.
- Αλλάξτε δυναμικά τη διαμόρφωση παραγωγού για να αλλάξετε την επισκεψιμότητα του παραγωγού στο σύμπλεγμα αποτυχίας.
Το σενάριο αποτυχίας μπορεί να απεικονιστεί από τον ακόλουθο γράφημα:
Με την πλήρη αυτοματοποίηση της διαδικασίας, μπορούμε να κάνουμε αποτυχία σε λιγότερο από 5 λεπτά. Μόλις ολοκληρωθεί η αποτυχία με επιτυχία, μπορούμε να εντοπίσουμε εντοπισμό των προβλημάτων με το αρχικό σύμπλεγμα χρησιμοποιώντας αρχεία καταγραφής και μετρήσεις. Είναι επίσης δυνατό να καταστρέψετε πλήρως το σύμπλεγμα και να ανοικοδομήσετε με νέες εικόνες πριν μετακινήσουμε την κυκλοφορία. Στην πραγματικότητα, χρησιμοποιούμε συχνά στρατηγική αποτυχίας για την εκτροπή της κυκλοφορίας ενώ κάνουμε συντήρηση εκτός σύνδεσης. Αυτός είναι ο τρόπος με τον οποίο αναβαθμίζουμε τα clusters kafka μας σε νέα έκδοση Kafka χωρίς να χρειάζεται να κάνουμε την κυλιόμενη αναβάθμιση ή να ρυθμίσετε την έκδοση πρωτοκόλλου επικοινωνίας Inter-Broker.
Ανάπτυξη για το Kafka
Αναπτύξαμε αρκετά χρήσιμα εργαλεία για το kafka. Εδώ είναι μερικά από τα σημαντικότερα σημεία:
Παραγωγός κολλώδης διαμερίσματος
Πρόκειται για έναν ειδικό προσαρμοσμένο διαμεριστή που έχουμε αναπτύξει για τη βιβλιοθήκη παραγωγών Java. Όπως υποδηλώνει το όνομα, κολλάει σε ένα συγκεκριμένο διαμέρισμα για την παραγωγή για ένα διαμορφώσιμο χρονικό διάστημα πριν από την τυχαία επιλογή του επόμενου διαμερίσματος. Διαπιστώσαμε ότι η χρήση κολλώδους διαμεριστή μαζί με την παρατεταμένη βοηθάει στη βελτίωση της παρτίδας μηνυμάτων και στη μείωση του φορτίου για τον μεσίτη. Εδώ είναι ο πίνακας για να δείξει την επίδραση του κολλώδους διαμεριστή:
Rack Aware Replica Assignment
Όλες οι συστάδες μας Kafka εκτείνονται σε τρεις ζώνες διαθεσιμότητας AWS. Μια ζώνη διαθεσιμότητας AWS είναι εννοιολογικά ένα ράφι. Για να διασφαλιστεί η διαθεσιμότητα σε περίπτωση που μειώνεται η μία ζώνη, αναπτύξαμε την ανάθεση αντιγράφων Rack (Zone), έτσι ώστε τα αντίγραφα για το ίδιο θέμα να αντιστοιχούν σε διαφορετικές ζώνες. Αυτό όχι μόνο συμβάλλει στη μείωση του κινδύνου διακοπής ζώνης, αλλά και βελτιώνει τη διαθεσιμότητά μας όταν οι πολλαπλοί μεσίτες που συνυπάρχουν στον ίδιο φυσικό ξενιστή τερματίζονται λόγω προβλημάτων ξενιστών. Σε αυτή την περίπτωση, έχουμε καλύτερη ανοχή σφάλματος από το kafka’s n – 1 όπου n είναι ο παράγοντας αναπαραγωγής.
Το έργο συμβάλλει στην κοινότητα Kafka στο KIP-36 και στο Apache Kafka Github Pull Αίτημα #132.
Kafka μεταδεδομένα οπτικοποιητής
Καφκά’Τα μεταδεδομένα αποθηκεύονται στο zookeeper. Ωστόσο, η προβολή δέντρων που παρέχεται από τον εκθέτη είναι δύσκολο να πλοηγηθεί και είναι χρονοβόρα για να βρει και να συσχετίσει πληροφορίες.
Δημιουργήσαμε το δικό μας UI για να απεικονίσουμε τα μεταδεδομένα. Παρέχει τόσο διάγραμμα όσο και σε πίνακες και χρησιμοποιεί πλούσια σχέδια χρωμάτων για να υποδείξει την κατάσταση ISR. Τα βασικά χαρακτηριστικά είναι τα εξής:
- Μεμονωμένη καρτέλα για προβολές για μεσίτες, θέματα και ομάδες
- Οι περισσότερες πληροφορίες μπορούν να διαμορφώσουν και να αναζητηθούν
- Αναζητώντας θέματα σε συστάδες
- Άμεση χαρτογράφηση από το αναγνωριστικό μεσίτη στο AWS
- Συσχέτιση των μεσιτών από τη σχέση αρχηγού-οπαδού
Τα παρακάτω είναι τα στιγμιότυπα οθόνης του UI:
Παρακολούθηση
Δημιουργήσαμε μια ειδική υπηρεσία παρακολούθησης για το Kafka. Είναι υπεύθυνο για την παρακολούθηση:
- Κατάσταση μεσίτη (συγκεκριμένα, εάν είναι εκτός σύνδεσης από το Zookeeper)
- Μεσίτης’η δυνατότητα λήψης μηνυμάτων από παραγωγούς και παραδίδει μηνύματα στους καταναλωτές. Η υπηρεσία παρακολούθησης ενεργεί τόσο ως παραγωγός όσο και ως καταναλωτής για συνεχή μηνύματα καρδιάς και μετρά την καθυστέρηση αυτών των μηνυμάτων.
- Για τους παλιούς καταναλωτές που βασίζονται σε zookeeper, παρακολουθεί τον αριθμό των καταναλωτών για την ομάδα καταναλωτών για να βεβαιωθεί ότι κάθε διαμέρισμα καταναλώνεται.
- Για τους δρομολογητές της Keystone Samza, παρακολουθεί τις αντισταθμίσεις και συγκρίνεται με τον μεσίτη’S Logsets για να βεβαιωθείτε ότι δεν έχουν κολλήσει και δεν έχουν σημαντική καθυστέρηση.
Επιπλέον, έχουμε εκτεταμένους πίνακες ελέγχου για την παρακολούθηση της ροής της κυκλοφορίας σε επίπεδο θέματος και το μεγαλύτερο μέρος του μεσίτη’μετρήσεις.
Μελλοντικό σχέδιο
Αυτή τη στιγμή βρισκόμαστε σε διαδικασία μετανάστευσης στο Kafka 0.9, το οποίο έχει αρκετά χαρακτηριστικά που θέλουμε να χρησιμοποιήσουμε, συμπεριλαμβανομένων νέων API καταναλωτών, χρονικού ορίου μηνυμάτων παραγωγού και ποσοστώσεων. Θα μεταφέρουμε επίσης τα συστάδες Kafka στο AWS VPC και θα πιστεύουμε ότι η βελτιωμένη δικτύωση (σε σύγκριση με το EC2 Classic) θα μας δώσει ένα πλεονέκτημα για να βελτιώσουμε τη διαθεσιμότητα και τη χρήση των πόρων.
Πρόκειται να εισαγάγουμε ένα κλιμακωτό SLA για θέματα. Για θέματα που μπορούν να δεχθούν μικρές απώλειες, σκέφτονται να χρησιμοποιήσουμε ένα αντίγραφο. Χωρίς αναπαραγωγή, όχι μόνο εξοικονομούμε τεράστια σε εύρος ζώνης, αλλά και ελαχιστοποιούμε τις αλλαγές κατάστασης που πρέπει να εξαρτώνται από τον ελεγκτή. Αυτό είναι ένα ακόμη βήμα για να κάνετε το Kafka λιγότερο κρατικό σε ένα περιβάλλον που ευνοεί τις υπηρεσίες ανιθαγενείς. Το μειονέκτημα είναι η πιθανή απώλεια μηνύματος όταν ένας μεσίτης εξαφανίζεται. Ωστόσο, αξιοποιώντας το χρονικό όριο μηνυμάτων παραγωγού στο 0.9 Απελευθέρωση και ενδεχομένως AWS EBS όγκος, μπορούμε να μετριάσουμε την απώλεια.
Μείνετε συντονισμένοι για τα μελλοντικά blogs keystone σχετικά με την υποδομή δρομολόγησης, τη διαχείριση των εμπορευματοκιβωτίων, την επεξεργασία ροής και πολλά άλλα!
Διαθέτει το Apache Kafka στο Netflix Studio και Finance World
Η Netflix δαπάνησε περίπου 15 δισεκατομμύρια δολάρια για να παράγει πρωτότυπο περιεχόμενο παγκόσμιας κλάσης το 2019. Όταν τα πονταρίσματα είναι τόσο υψηλά, είναι υψίστης σημασίας να επιτρέψουμε την επιχείρησή μας με κρίσιμες γνώσεις που βοηθούν στο σχεδιασμό, τον προσδιορισμό των δαπανών και τη λογιστική για όλα τα περιεχόμενα Netflix. Αυτές οι ιδέες μπορούν να περιλαμβάνουν:
- Πόσο πρέπει να περάσουμε το επόμενο έτος σε διεθνείς ταινίες και σειρές?
- Είμαστε τείνοντας να προχωρήσουμε στον προϋπολογισμό παραγωγής μας και χρειάζεται κάποιος να εισέλθει για να κρατήσει τα πράγματα σε καλό δρόμο?
- Πώς προγραμματίζουμε ένα κατάλογο χρόνια εκ των προτέρων με δεδομένα, διαίσθηση και αναλυτικά στοιχεία για να βοηθήσουμε στη δημιουργία του καλύτερου δυνατού σχήματος?
- Πώς παράγουμε οικονομικά για περιεχόμενο σε όλο τον κόσμο και αναφέρουμε στη Wall Street?
Παρόμοια με τον τρόπο με τον οποίο τα VCs συντονίζουν αυστηρά το μάτι τους για καλές επενδύσεις, η ομάδα μηχανικών χρηματοδότησης περιεχομένου’Ο Χάρτης είναι να βοηθήσουμε την Netflix να επενδύσει, να παρακολουθήσει και να μάθει από τις ενέργειές μας, ώστε να κάνουμε συνεχώς καλύτερες επενδύσεις στο μέλλον.
Αγκαλιάζοντας την εκδήλωση
Από τεχνική άποψη, κάθε οικονομική εφαρμογή διαμορφώνεται και εφαρμόζεται ως μικροεπιχειρήσεις. Η Netflix αγκαλιάζει την κατανεμημένη διακυβέρνηση και ενθαρρύνει μια προσέγγιση που βασίζεται σε μικροεπιχειρήσεις στις εφαρμογές, η οποία συμβάλλει στην επίτευξη της σωστής ισορροπίας μεταξύ της αφαίρεσης των δεδομένων και της ταχύτητας ως κλίμακες της εταιρείας. Σε έναν απλό κόσμο, οι υπηρεσίες μπορούν να αλληλεπιδρούν μέσω του HTTP, αλλά καθώς κλιμακώνουμε, εξελίσσονται σε ένα πολύπλοκο γράφημα σύγχρονων αλληλεπιδράσεων που βασίζονται σε αίτια που μπορούν να οδηγήσουν σε διαχωρισμό/κατάσταση και διαταραχή και διαταραχή.
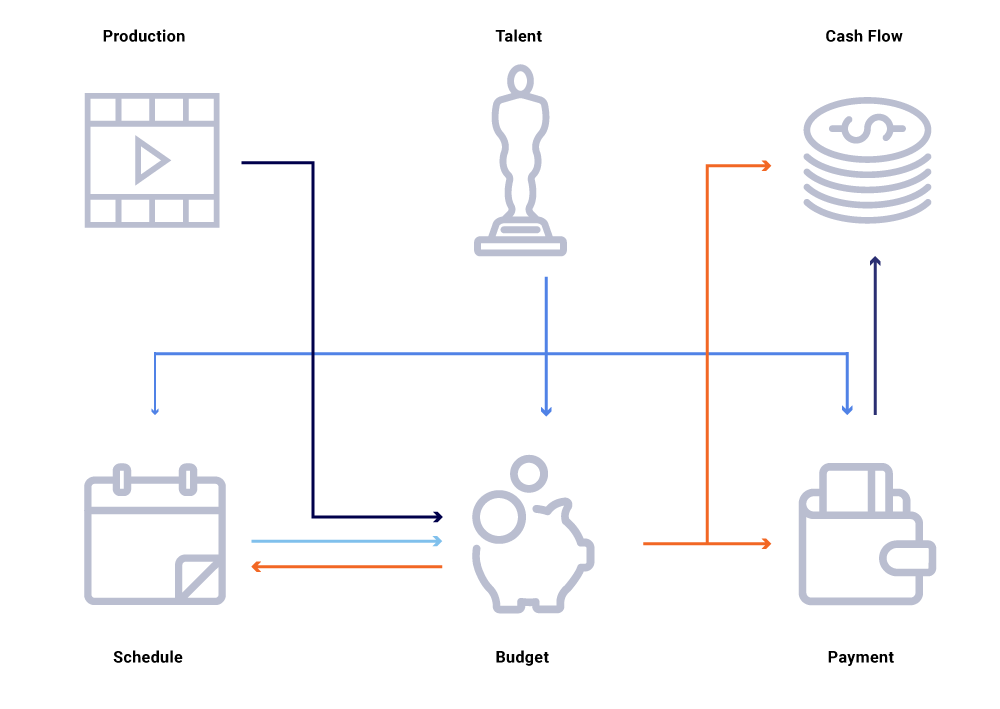
Εξετάστε στο παραπάνω γράφημα των σχετικών οντοτήτων, μια αλλαγή στην ημερομηνία παραγωγής μιας παράστασης. Αυτό επηρεάζει την πλάκα προγραμματισμού μας, η οποία με τη σειρά του επηρεάζει τα έργα ταμειακών ροών, τις πληρωμές ταλέντων, τους προϋπολογισμούς για το έτος κ.λπ. Συχνά σε μια αρχιτεκτονική Microservice, κάποιο ποσοστό αποτυχίας είναι αποδεκτό. Ωστόσο, μια αποτυχία σε οποιαδήποτε από τις απαιτήσεις μικροεπιχειρήσεων για τη μηχανική χρηματοδότησης περιεχομένου θα οδηγούσε σε μια πληθώρα υπολογισμών που δεν έχουν συγχρονιστεί και θα μπορούσαν να οδηγήσουν στην απενεργοποίηση των δεδομένων κατά εκατομμύρια δολάρια. Θα οδηγούσε επίσης σε προβλήματα διαθεσιμότητας, καθώς το γράφημα κλήσεων εκτείνεται και προκαλεί τυφλά σημεία ενώ προσπαθούσε να εντοπίσει αποτελεσματικά και να απαντήσει σε επιχειρηματικές ερωτήσεις, όπως: Γιατί οι προβλέψεις ταμειακών ροών αποκλίνουν από το χρονοδιάγραμμα εκτόξευσης μας? Γιατί η πρόβλεψη για το τρέχον έτος δεν λαμβάνει υπόψη τις εκπομπές που βρίσκονται σε ενεργό ανάπτυξη? Πότε μπορούμε να περιμένουμε τις αναφορές κόστους μας να αντικατοπτρίζουν με ακρίβεια τις ανάντη αλλαγές?
Επανεξετάζοντας τις αλληλεπιδράσεις των υπηρεσιών ως ρεύματα ανταλλαγών συμβάντων – σε αντίθεση με μια ακολουθία σύγχρονων αιτημάτων – αναθέτει τις ΗΠΑ να κατασκευάζουμε υποδομές που είναι εγγενώς ασύγχρονη. Προωθεί την αποσύνδεση και παρέχει ανιχνευσιμότητα ως πολίτης πρώτης κατηγορίας σε έναν ιστό κατανεμημένων συναλλαγών. Οι εκδηλώσεις είναι πολύ περισσότερο από τις ενεργοποιήσεις και τις ενημερώσεις. Γίνονται το αμετάβλητο ρεύμα από το οποίο μπορούμε να ανακατασκευάσουμε ολόκληρη την κατάσταση του συστήματος.
Η μετάβαση προς ένα μοντέλο δημοσίευσης/εγγραφής επιτρέπει σε κάθε υπηρεσία να δημοσιεύσει τις αλλαγές της ως συμβάντα σε ένα λεωφορείο μηνυμάτων, το οποίο στη συνέχεια μπορεί να καταναλωθεί από μια άλλη υπηρεσία ενδιαφέροντος που πρέπει να προσαρμόσει την κατάσταση του κόσμου. Ένα τέτοιο μοντέλο μας επιτρέπει να παρακολουθούμε εάν οι υπηρεσίες είναι σε συγχρονισμό σε σχέση με τις αλλαγές κατάστασης και, αν όχι, πόσο καιρό πριν μπορούν να συγχρονιστούν. Αυτές οι ιδέες είναι εξαιρετικά ισχυρές όταν λειτουργούν ένα μεγάλο γράφημα εξαρτημένων υπηρεσιών. Η επικοινωνία με βάση τα γεγονότα και η αποκεντρωμένη κατανάλωση μας βοηθούν να ξεπεράσουμε τα ζητήματα που συνήθως βλέπουμε σε μεγάλα γραφήματα σύγχρονης κλήσεων (όπως αναφέρθηκε παραπάνω).
Το Netflix αγκαλιάζει το Apache Kafka® ως το πρότυπο de-facto για τις ανάγκες της εκδήλωσης, των μηνυμάτων και της ροής. Το Kafka λειτουργεί ως γέφυρα για όλες τις επικοινωνίες ευρείας επικοινωνίας από σημείο σε σημείο και Netflix Studio. Μας παρέχει την υψηλή ανθεκτικότητα και γραμμικά κλιμακωτή, πολυεπίπεδη αρχιτεκτονική που απαιτείται για λειτουργικά συστήματα στο Netflix. Η εσωτερική μας Kafka ως προσφορά υπηρεσιών παρέχει ανοχή σφάλματος, παρατηρήσιμη, αναπτύξεις πολλαπλών περιφερειών και αυτοεξυπηρέτηση. Αυτό διευκολύνει το σύνολο του οικοσυστήματος των μικροεπιχειρήσεων να παράγουν εύκολα και να καταναλώνουν σημαντικά γεγονότα και να απελευθερώσουν τη δύναμη της ασύγχρονης επικοινωνίας.
Μια τυπική ανταλλαγή μηνυμάτων στο οικοσύστημα του Netflix Studio μοιάζει με αυτό:
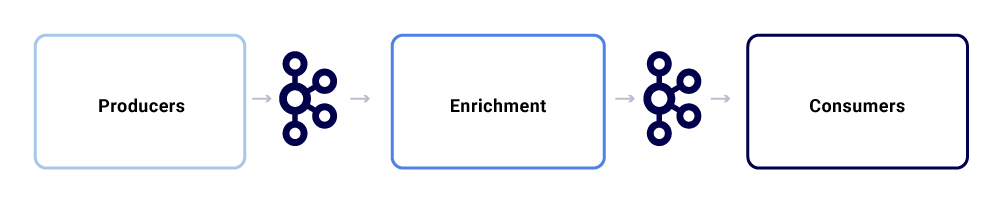
Μπορούμε να τα διαλύσουμε ως τρία μεγάλα υπο-συστατικά.
Παραγωγοί
Ένας παραγωγός μπορεί να είναι οποιοδήποτε σύστημα που θέλει να δημοσιεύσει ολόκληρο το κράτος του ή υπαινιγμό ότι ένα κρίσιμο κομμάτι της εσωτερικής του κατάστασης έχει αλλάξει για μια συγκεκριμένη οντότητα. Εκτός από το ωφέλιμο φορτίο, ένα συμβάν πρέπει να συμμορφωθεί με μια κανονικοποιημένη μορφή, γεγονός που διευκολύνει την ανίχνευση και την κατανόηση. Αυτή η μορφή περιλαμβάνει:
- UUID: Καθολικά μοναδικό αναγνωριστικό
- Τύπος: Ένας από τους τύπους δημιουργίας, ανάγνωσης, ενημέρωσης ή διαγραφής (CRUD)
- TS: Χρονική σήμανση της εκδήλωσης
Τα εργαλεία αλλαγής λήψης δεδομένων (CDC) είναι μια άλλη κατηγορία παραγωγών εκδηλώσεων που παράγουν γεγονότα από αλλαγές στη βάση δεδομένων. Αυτό μπορεί να είναι χρήσιμο όταν θέλετε να κάνετε αλλαγές βάσεων δεδομένων διαθέσιμες σε πολλούς καταναλωτές. Χρησιμοποιούμε επίσης αυτό το μοτίβο για την αναπαραγωγή των ίδιων δεδομένων μεταξύ των δεδομένων (για μεμονωμένες βάσεις δεδομένων). Ένα παράδειγμα είναι όταν έχουμε δεδομένα στο MySQL που πρέπει να αναπροσαρμόζονται σε Elasticsearch ή Apache Solr ™. Το πλεονέκτημα της χρήσης του CDC είναι ότι δεν επιβάλλει πρόσθετο φορτίο στην εφαρμογή πηγής.
Για τα συμβάντα CDC, το πεδίο τύπου στη μορφή συμβάντος διευκολύνει την προσαρμογή και τη μετατροπή των συμβάντων όπως απαιτείται από τους αντίστοιχους νεροχύτες.
Εμπλουτισμός
Μόλις υπάρχουν δεδομένα στο Kafka, μπορούν να εφαρμοστούν διάφορα πρότυπα κατανάλωσης σε αυτό. Τα γεγονότα χρησιμοποιούνται με πολλούς τρόπους, συμπεριλαμβανομένων των ενεργοποιητών για υπολογισμούς συστήματος, μεταφορά ωφέλιμου φορτίου για επικοινωνία σχεδόν πραγματικού χρόνου και ενδείξεις για εμπλουτισμό και υλοποίηση απόψεις σε μνήμη των δεδομένων.
Ο εμπλουτισμός δεδομένων γίνεται όλο και πιο συνηθισμένος όταν οι μικροεπιχειρήσεις χρειάζονται την πλήρη προβολή ενός συνόλου δεδομένων, αλλά μέρος των δεδομένων προέρχεται από άλλη υπηρεσία’SATASET S. Ένα ενωμένο σύνολο δεδομένων μπορεί να είναι χρήσιμο για τη βελτίωση της απόδοσης των ερωτημάτων ή την παροχή μιας προβολής σχεδόν πραγματικών δεδομένων των συγκεντρωτικών δεδομένων. Για να εμπλουτίσουν τα δεδομένα συμβάντων, οι καταναλωτές διαβάζουν τα δεδομένα από την Kafka και καλούν άλλες υπηρεσίες (χρησιμοποιώντας μεθόδους που περιλαμβάνουν GRPC και GraphQL) για να κατασκευάσουν το ενωμένο σύνολο δεδομένων, τα οποία στη συνέχεια τροφοδοτούνται αργότερα σε άλλα θέματα Kafka.
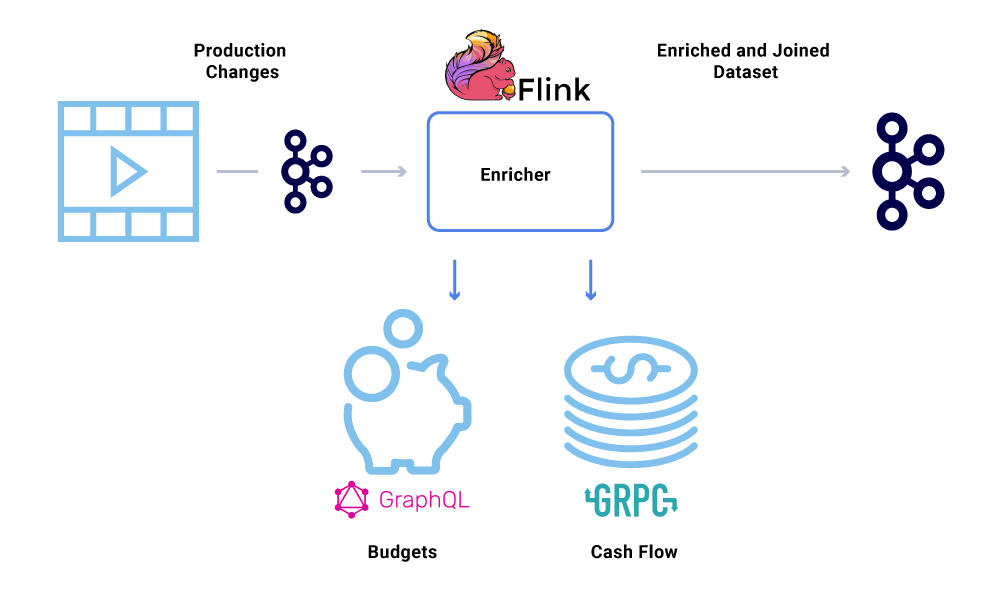
Ο εμπλουτισμός μπορεί να εκτελεστεί ως ξεχωριστή microservice σε αυτό που είναι υπεύθυνο για την εκτέλεση του fan-out και για την υλοποίηση των συνόλων δεδομένων. Υπάρχουν περιπτώσεις όπου θέλουμε να κάνουμε πιο περίπλοκη επεξεργασία όπως παράθυρα, συνεδρίαση και διαχείριση του κράτους. Για τέτοιες περιπτώσεις, συνιστάται να χρησιμοποιήσετε μια μηχανή επεξεργασίας ώριμης ροής στην κορυφή του Kafka για την κατασκευή επιχειρηματικής λογικής. Στο Netflix, χρησιμοποιούμε το Apache Flink ® και το RocksDB για να κάνουμε ροή επεξεργασίας. Εμείς’Εξετάζοντας επίσης το KSQLDB για παρόμοιους σκοπούς.
Παραγγελία γεγονότων
Μία από τις βασικές απαιτήσεις εντός ενός οικονομικού συνόλου δεδομένων είναι η αυστηρή παραγγελία συμβάντων. Το Kafka μας βοηθά να το επιτύχουμε είναι αποστέλλοντας τα κλειδωμένα μηνύματα. Οποιοδήποτε συμβάν ή μήνυμα που αποστέλλεται με το ίδιο κλειδί, θα έχει εγγυημένη παραγγελία από τότε που αποστέλλονται στο ίδιο διαμέρισμα. Ωστόσο, οι παραγωγοί μπορούν ακόμα να ανακατέψουν την παραγγελία των γεγονότων.
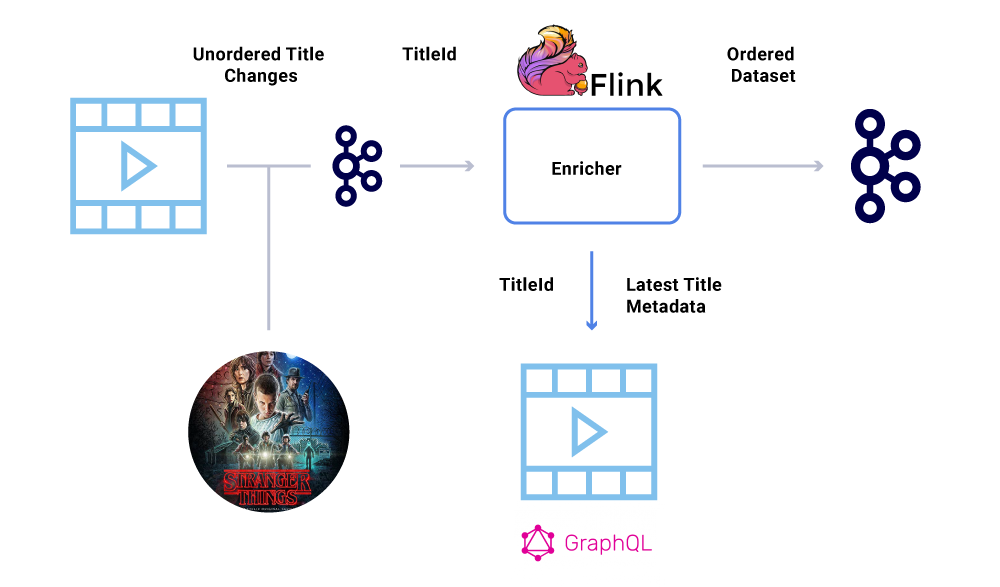
Για παράδειγμα, η ημερομηνία έναρξης του “Stranger Things” αρχικά μεταφέρθηκε από τον Ιούλιο έως τον Ιούνιο, αλλά στη συνέχεια από τον Ιούνιο έως τον Ιούλιο. Για διάφορους λόγους, αυτά τα γεγονότα θα μπορούσαν να γραφτούν με λανθασμένη σειρά στο Kafka (χρονικό όριο δικτύου όταν ο παραγωγός προσπάθησε να φτάσει στο Kafka, ένα σφάλμα ταυτόχρονα στον κώδικα παραγωγού κ.λπ.). Ένας λόξυγκας παραγγελίας θα μπορούσε να έχει επηρεάσει σε μεγάλο βαθμό διάφορους οικονομικούς υπολογισμούς.
Για να παρακάμψουν αυτό το σενάριο, οι παραγωγοί ενθαρρύνονται να στείλουν μόνο το κύριο αναγνωριστικό της οντότητας που έχει αλλάξει και όχι το πλήρες ωφέλιμο φορτίο στο μήνυμα Kafka. Η διαδικασία εμπλουτισμού (που περιγράφεται στην παραπάνω ενότητα) ερωτάει την υπηρεσία προέλευσης με το αναγνωριστικό της οντότητας για να αποκτήσει το πιο ενημερωμένο κατάστασης/ωφέλιμο φορτίο, παρέχοντας έτσι έναν κομψό τρόπο καταστρατήγησης του τεύχους εκτός τάξης. Αναφερόμαστε σε αυτό ως καθυστερημένη υλοποίηση, και εγγυάται τα παραγγελθέντα σύνολα δεδομένων.
Καταναλωτές
Χρησιμοποιούμε την Spring Boot για να εφαρμόσουμε πολλές από τις καταναλωτικές μικροεπιχειρήσεις που διαβάζουν από τα θέματα Kafka. Το Spring Boot προσφέρει εξαιρετικούς ενσωματωμένους καταναλωτές kafka που ονομάζονται spring kafka connectors, οι οποίοι κάνουν την κατανάλωση απρόσκοπτη, παρέχοντας εύκολους τρόπους για να καλύψουν σχολιασμούς για κατανάλωση και αποταμιευοποίηση δεδομένων.
Μια πτυχή των δεδομένων που έχουμε’δεν συζητούνται ακόμη συμβόλαια. Καθώς αυξάνουμε τη χρήση ροών συμβάντων, καταλήγουμε σε μια ποικίλη ομάδα δεδομένων, μερικά από τα οποία καταναλώνονται από μεγάλο αριθμό εφαρμογών. Σε αυτές τις περιπτώσεις, ο καθορισμός ενός σχήματος στην έξοδο είναι ιδανική και βοηθά στη διασφάλιση της συμβατότητας προς τα πίσω. Για να το κάνουμε αυτό, εκμεταλλευόμαστε το μητρώο συρροών και το Apache Avro ™ για να οικοδομήσουμε τα schematized ρεύματα μας για ροές δεδομένων έκδοσης.
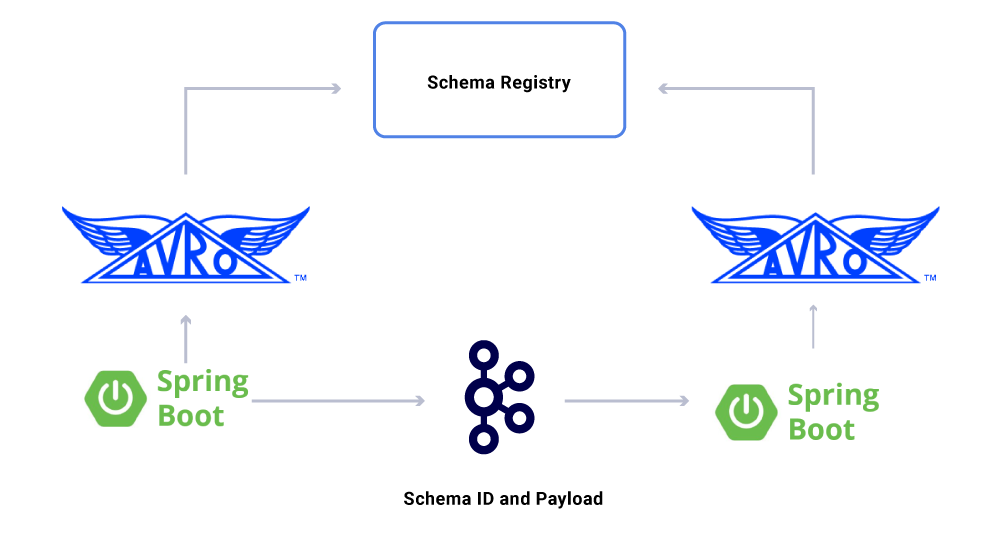
Εκτός από τους αποκλειστικούς καταναλωτές μικροεπιχειρήσεων, έχουμε επίσης νεροχύτες CDC που ευρετήρια τα δεδομένα σε μια ποικιλία καταστημάτων για περαιτέρω ανάλυση. Αυτά περιλαμβάνουν το Elasticsearch για την αναζήτηση λέξεων -κλειδιών, το Apache Hive ™ για τον έλεγχο και την ίδια την Kafka για περαιτέρω επεξεργασία κατάντη. Το ωφέλιμο φορτίο για τέτοιους νεροχύτες προέρχεται απευθείας από το μήνυμα Kafka χρησιμοποιώντας το πεδίο ID ως το κύριο κλειδί και τον τύπο για τον εντοπισμό των λειτουργιών CRUD.
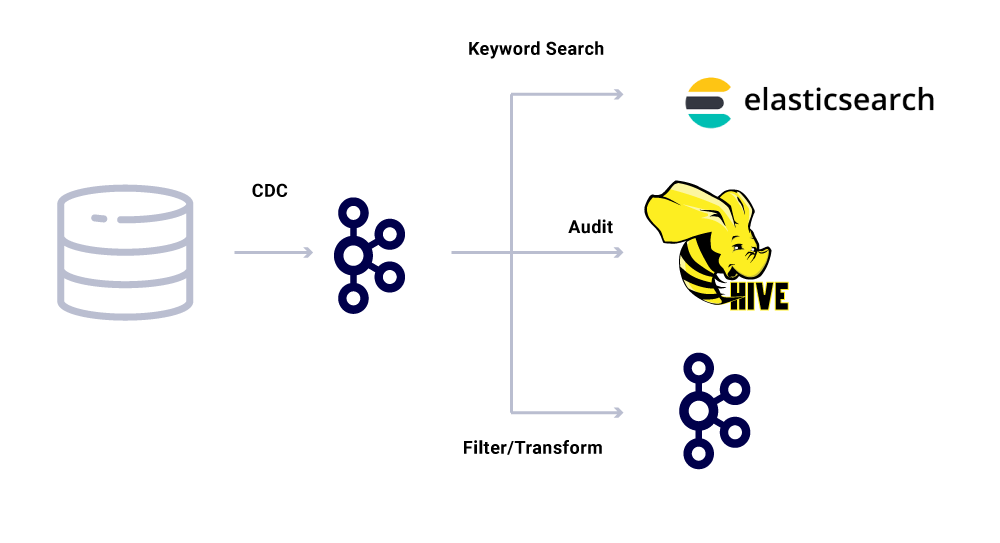
Εγγυήσεις παράδοσης μηνυμάτων
Η εξασφάλιση ακριβώς όταν η παράδοση σε ένα κατανεμημένο σύστημα είναι μη τμηματική λόγω της πολυπλοκότητας και της πληθώρας κινούμενων τμημάτων. Οι καταναλωτές θα πρέπει να έχουν idempotent συμπεριφορά για να υπολογίσουν οποιαδήποτε πιθανή υποδομή και ατυχήματα παραγωγών.
Παρά το γεγονός ότι οι εφαρμογές είναι idempotent, δεν πρέπει να επαναλαμβάνουν τον υπολογισμό βαρέων λειτουργιών για τα ήδη επεξεργασμένα μηνύματα. Ένας δημοφιλής τρόπος για να εξασφαλιστεί αυτό είναι να παρακολουθείτε το UUID των μηνυμάτων που καταναλώνονται από μια υπηρεσία σε μια κατανεμημένη μνήμη cache με λογική λήξη (ορίζεται με βάση τις συμφωνίες επιπέδου υπηρεσιών (SLA). Οποτεδήποτε συναντάται το ίδιο UUID στο διάστημα λήξης, η επεξεργασία παραλείπεται.
Η επεξεργασία στο Flink παρέχει αυτήν την εγγύηση χρησιμοποιώντας την εσωτερική διαχείριση του κράτους RockSDB, με το κλειδί να είναι το UUID του μηνύματος. Εάν θέλετε να το κάνετε αυτό καθαρά χρησιμοποιώντας το Kafka, το Kafka Streams προσφέρει έναν τρόπο να το κάνετε αυτό επίσης. Καταναλώνοντας εφαρμογές βασισμένες στη χρήση της εκκίνησης της άνοιξης για να το επιτύχουμε αυτό.
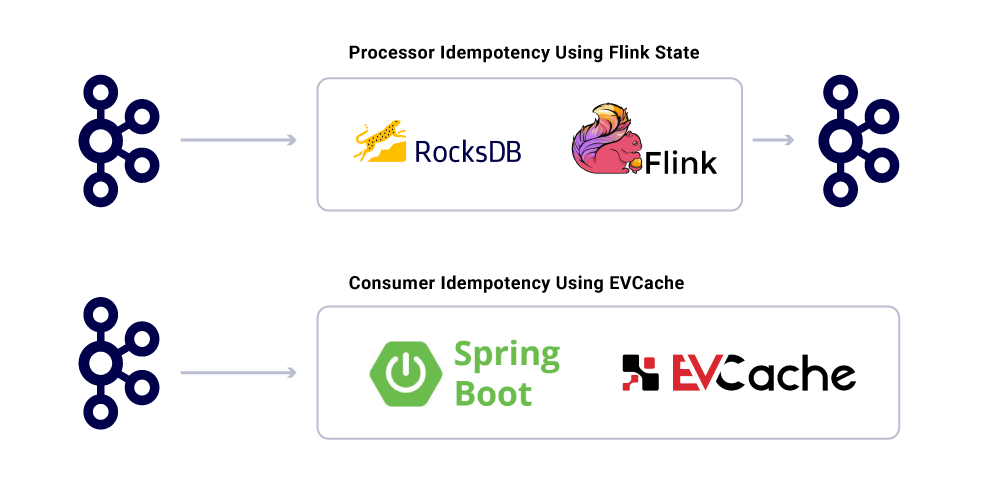
Παρακολούθηση των επιπέδων υπηρεσιών υποδομής
Το’είναι κρίσιμο για το Netflix να έχει μια άποψη σε πραγματικό χρόνο για τα επίπεδα υπηρεσιών μέσα στην υποδομή της. Η Netflix έγραψε τον Atlas για τη διαχείριση δεδομένων χρονοσειρών διαστάσεων, από τα οποία δημοσιεύουμε και απεικονίζουμε μετρήσεις. Χρησιμοποιούμε μια ποικιλία μετρήσεων που δημοσιεύονται από παραγωγούς, επεξεργαστές και καταναλωτές για να μας βοηθήσουν να κατασκευάσουμε μια εικόνα σχεδόν πραγματικού χρόνου ολόκληρης της υποδομής.
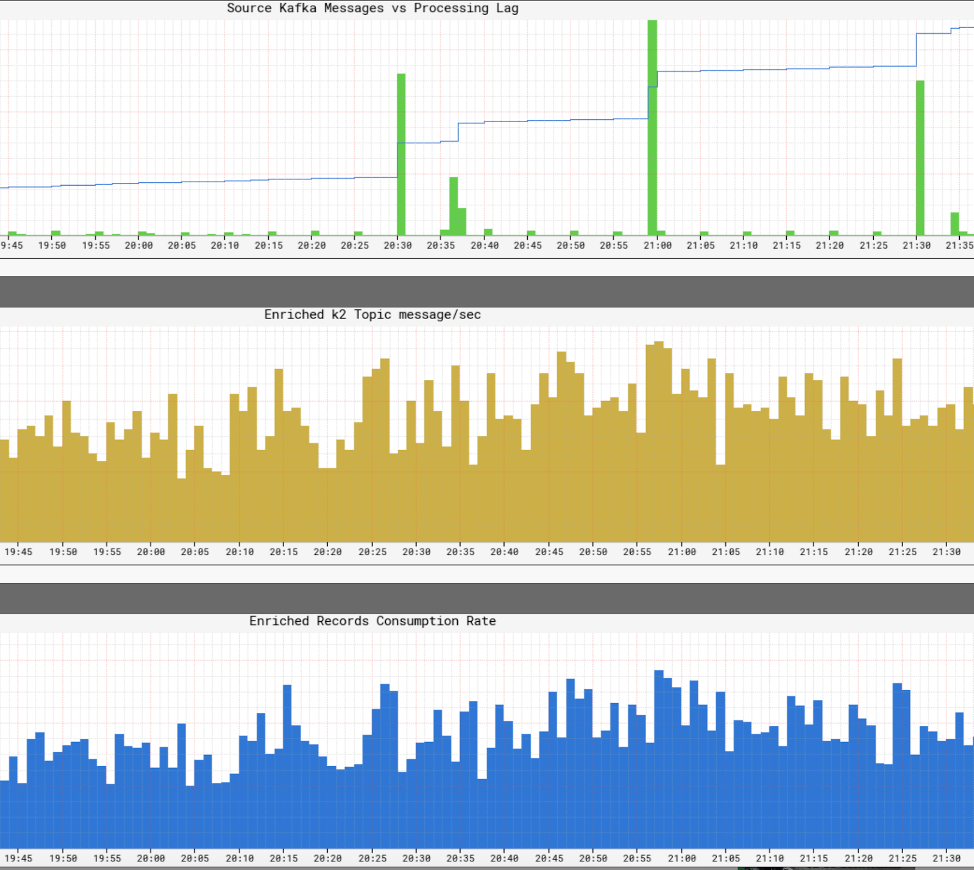
Μερικές από τις βασικές πτυχές που παρακολουθούμε είναι:
- Φρεσκάδα
- Τι είναι το τέλος του χρόνου μέχρι την παραγωγή ενός γεγονότος μέχρι να φτάσει σε όλους τους νεροχύτες?
- Ποια είναι η καθυστέρηση επεξεργασίας για κάθε καταναλωτή?
- Πόσο μεγάλο ωφέλιμο φορτίο είναι σε θέση να στείλουμε?
- Πρέπει να συμπιέσουμε τα δεδομένα?
- Χρησιμοποιούμε αποτελεσματικά τους πόρους μας?
- Μπορούμε να καταναλώνουμε γρηγορότερα?
- Είμαστε σε θέση να δημιουργήσουμε ένα σημείο ελέγχου για την πολιτεία μας και να συνεχίσουμε σε περίπτωση αποτυχίας?
- Εάν δεν είμαστε σε θέση να συμβαδίσουμε με την εκδήλωση Firehose, μπορούμε να εφαρμόσουμε backpressure στις αντίστοιχες πηγές χωρίς να συντρίψουμε την αίτησή μας?
- Πώς αντιμετωπίζουμε τις εκρήξεις εκδηλώσεων?
- Παρέχονται επαρκώς για να συναντήσουμε το SLA?
Σύνοψη
Η Netflix Studio Productions and Finance Team αγκαλιάζει την κατανεμημένη διακυβέρνηση ως τον τρόπο των συστημάτων αρχιτεκτονικής. Χρησιμοποιούμε την Kafka ως την πλατφόρμα επιλογής μας για συνεργασία με εκδηλώσεις, τα οποία είναι ένας αμετάβλητος τρόπος καταγραφής και παραγωγής κατάστασης συστήματος. Ο Kafka μας βοήθησε να επιτύχουμε μεγαλύτερα επίπεδα ορατότητας και αποσύνδεσης στην υποδομή μας, βοηθώντας μας οργανικά. Βρίσκεται στο επίκεντρο της επανάστασης της υποδομής του Netflix Studio και μαζί της, της κινηματογραφικής βιομηχανίας.
Ενδιαφέρεστε για περισσότερα?
Αν εσύ’D αρέσει να μάθετε περισσότερα, μπορείτε να δείτε την εγγραφή και τις διαφάνειες της Kafka Summit Summit μου San Francisco Eventing Things – A Netflix Original!
Netflix: Πώς ο Apache Kafka μετατρέπει δεδομένα από εκατομμύρια σε νοημοσύνη
Η Netflix δαπάνησε 16 δισεκατομμύρια δολάρια για την παραγωγή περιεχομένου το 2020. Τον Ιανουάριο του 2021, η εφαρμογή Netflix Mobile (iOS και Android) λήφθηκε 19 εκατομμύρια φορές και ένα μήνα αργότερα, η εταιρεία ανακοίνωσε ότι είχε χτυπήσει 203.66 εκατομμύρια συνδρομητές παγκοσμίως. Το’είναι ασφαλές να υποθέσουμε ότι η κλίμακα δεδομένων που συλλέγει και διαδικασίες της εταιρείας είναι τεράστια. Η ερώτηση είναι –
Πώς η Netflix διαδικασία δισεκατομμυρίων αρχείων δεδομένων και συμβάντων για τη λήψη κρίσιμων επιχειρηματικών αποφάσεων?
Με ετήσιο προϋπολογισμό περιεχομένου αξίας 16 δισεκατομμυρίων δολαρίων, οι υπεύθυνοι λήψης αποφάσεων στο Netflix Aren’Δεν πρόκειται να λάβουμε αποφάσεις που σχετίζονται με το περιεχόμενο με βάση τη διαίσθηση. Αντ ‘αυτού, οι επιμελητές περιεχομένου τους χρησιμοποιούν τεχνολογία αιχμής για να κατανοήσουν τα τεράστια ποσά δεδομένων σχετικά με τη συμπεριφορά των συνδρομητών, τις προτιμήσεις περιεχομένου των χρηστών, το κόστος παραγωγής περιεχομένου, τους τύπους περιεχομένου που λειτουργούν κ.λπ. Αυτή η λίστα συνεχίζεται.
Οι χρήστες Netflix ξοδεύουν κατά μέσο όρο 3.2 ώρες την ημέρα στην πλατφόρμα τους και τροφοδοτούνται συνεχώς με τις τελευταίες συστάσεις της Netflix’ιδιόκτητος μηχανή σύστασης. Αυτό εξασφαλίζει ότι ο συνδρομητής Churn είναι χαμηλός και προσελκύει νέους συνδρομητές για να εγγραφούν. Η παράδοση περιεχομένου που βασίζεται σε δεδομένα είναι μπροστά και κέντρο αυτού.
Λοιπόν, αυτό που βρίσκεται κάτω από την κουκούλα από μια προοπτική επεξεργασίας δεδομένων?
Με άλλα λόγια, πώς το Netflix δημιούργησε μια τεχνολογική ραχοκοκαλιά που επέτρεψε τη λήψη αποφάσεων με γνώμονα τα δεδομένα σε τόσο μαζική κλίμακα? Πώς μπορεί κανείς να έχει νόημα τη συμπεριφορά των χρηστών 203 εκατομμυρίων συνδρομητών?
Το Netflix χρησιμοποιεί αυτό που ονομάζει τον αγωγό δεδομένων Keystone. Το 2016, ο αγωγός αυτός επεξεργάστηκε 500 δισεκατομμύρια εκδηλώσεις την ημέρα. Αυτά τα συμβάντα περιελάμβαναν αρχεία καταγραφής σφαλμάτων, δραστηριότητες προβολής χρηστών, δραστηριότητες UI, συμβάντα αντιμετώπισης προβλημάτων και πολλά άλλα πολύτιμα σύνολα δεδομένων.
Σύμφωνα με την Netflix, όπως δημοσιεύθηκε στο blog της:
Ο αγωγός Keystone είναι μια ενοποιημένη υποδομή δημοσίευσης, συλλογής και δρομολόγησης για την επεξεργασία παρτίδας και ροής.
Οι συστάδες Kafka αποτελούν βασικό μέρος του αγωγού δεδομένων Keystone στο Netflix. Το 2016, ο αγωγός Netflix χρησιμοποίησε 36 συστάδες Kafka για να επεξεργαστεί δισεκατομμύρια μηνύματα την ημέρα.
Λοιπόν, τι είναι το Apache Kafka? Και, γιατί έγινε τόσο δημοφιλής?
Το Apache Kafka είναι μια πλατφόρμα ροής ανοιχτού κώδικα που επιτρέπει την ανάπτυξη εφαρμογών που καταναλώνουν μεγάλο όγκο δεδομένων σε πραγματικό χρόνο. Κατασκευάστηκε αρχικά από τις ιδιοφυΐες στο LinkedIn και χρησιμοποιείται τώρα σε Netflix, Pinterest και Airbnb για να αναφέρουμε μερικά.
Ο Kafka κάνει συγκεκριμένα τέσσερα πράγματα:
- Επιτρέπει στις εφαρμογές να δημοσιεύουν ή να εγγραφούν σε δεδομένα δεδομένων ή συμβάντων
- Αποθηκεύει τα αρχεία δεδομένων με ακρίβεια και είναι εξαιρετικά ανεκτικό σε σφάλματα
- Είναι ικανό για επεξεργασία δεδομένων σε πραγματικό χρόνο, μεγάλου όγκου.
- Είναι σε θέση να πάρει και να επεξεργαστεί τρισεκατομμύρια αρχεία δεδομένων την ημέρα, χωρίς προβλήματα απόδοσης
Οι ομάδες ανάπτυξης λογισμικού είναι σε θέση να εκμεταλλευτούν το Kafka’S Δυνατότητες S με τα ακόλουθα APIs:
- Producer API: Αυτό το API επιτρέπει σε μια microservice ή μια εφαρμογή να δημοσιεύσει μια ροή δεδομένων σε ένα συγκεκριμένο θέμα Kafka. Ένα θέμα Kafka είναι ένα αρχείο καταγραφής που αποθηκεύει αρχεία δεδομένων και συμβάντων με τη σειρά με την οποία συνέβησαν.
- Consumer API: Αυτό το API επιτρέπει σε μια εφαρμογή να εγγραφεί σε ροές δεδομένων από ένα θέμα Kafka. Χρησιμοποιώντας το API του καταναλωτή, οι εφαρμογές μπορούν να καταναλώσουν και να επεξεργαστούν τη ροή δεδομένων, η οποία θα χρησιμεύσει ως εισροή στην καθορισμένη εφαρμογή.
- Streams API: Αυτό το API είναι κρίσιμο για εξελιγμένες εφαρμογές ροής δεδομένων και συμβάντων. Ουσιαστικά, καταναλώνει ροές δεδομένων από διάφορα θέματα kafka και είναι σε θέση να το επεξεργαστεί ή να το μετατρέψει ανάλογα με τις ανάγκες. Μετά τη επεξεργασία, αυτή η ροή δεδομένων δημοσιεύεται σε ένα άλλο θέμα Kafka για να χρησιμοποιηθεί κατάντη και/ή να μετατρέψει ένα υπάρχον θέμα.
- API Connector: Στις σύγχρονες εφαρμογές, υπάρχει μια συνεχή ανάγκη να επαναχρησιμοποιηθούν οι παραγωγοί ή οι καταναλωτές και να ενσωματώσουν αυτόματα μια πηγή δεδομένων σε ένα σύμπλεγμα Kafka. Το Kafka Connect καθιστά αυτό το περιττό συνδέει το Kafka με εξωτερικά συστήματα.
Βασικά οφέλη του Kafka
Σύμφωνα με τον ιστότοπο Kafka, το 80% όλων των εταιρειών Fortune 100 χρησιμοποιούν το Kafka. Ένας από τους μεγαλύτερους λόγους για αυτό είναι ότι ταιριάζει καλά με εφαρμογές κρίσιμης σημασίας για την αποστολή.
Οι μεγάλες εταιρείες χρησιμοποιούν το Kafka για τους ακόλουθους λόγους:
- Επιτρέπει με ευκολία την αποσύνδεση των ροών και των συστημάτων δεδομένων
- Έχει σχεδιαστεί για να διανέμεται, ανθεκτικό και ανεκτικό σε σφάλματα
- Η οριζόντια επεκτασιμότητα του Kafka είναι ένα από τα μεγαλύτερα πλεονεκτήματά του. Μπορεί να κλιμακωθεί σε 100s από συστάδες και εκατομμύρια μηνύματα ανά δευτερόλεπτο
- Επιτρέπει τη ροή δεδομένων σε πραγματικό χρόνο υψηλής απόδοσης, μια κρίσιμη ανάγκη σε εφαρμογές μεγάλης κλίμακας, που βασίζονται σε δεδομένα
Οι τρόποι Kafka χρησιμοποιούνται για τη βελτιστοποίηση της επεξεργασίας δεδομένων
Το Kafka χρησιμοποιείται σε όλες τις βιομηχανίες για διάφορους σκοπούς, συμπεριλαμβανομένων, ενδεικτικά, των παρακάτω
- Επεξεργασία δεδομένων σε πραγματικό χρόνο: Εκτός από τη χρήση του σε εταιρείες τεχνολογίας, η Kafka αποτελεί αναπόσπαστο μέρος της επεξεργασίας δεδομένων σε πραγματικό χρόνο στον κλάδο της μεταποίησης, όπου τα δεδομένα μεγάλου όγκου προέρχονται από μεγάλο αριθμό συσκευών και αισθητήρων IoT
- Παρακολούθηση ιστότοπου σε κλίμακα: Το Kafka χρησιμοποιείται για την παρακολούθηση της συμπεριφοράς των χρηστών και της δραστηριότητας του ιστότοπου σε ιστότοπους υψηλής κυκλοφορίας. Βοηθά στην παρακολούθηση, την επεξεργασία, τη σύνδεση με το Hadoop και την αποθήκευση δεδομένων εκτός σύνδεσης
- Παρακολούθηση βασικών μετρήσεων: Καθώς το Kafka μπορεί να χρησιμοποιηθεί για τη συγκέντρωση δεδομένων από διαφορετικές εφαρμογές σε μια κεντρική τροφοδοσία, διευκολύνει την παρακολούθηση των λειτουργικών δεδομένων μεγάλου όγκου
- ΣΥΝΔΕΣΗ ΛΟΓΙΣΜΟΥ: Επιτρέπει τα δεδομένα από πολλαπλές πηγές να συγκεντρωθούν σε ένα αρχείο καταγραφής για να αποκτήσουν σαφήνεια στην κατανεμημένη κατανάλωση
- Σύστημα μηνυμάτων: Αυτοματοποιεί εφαρμογές επεξεργασίας μηνυμάτων μεγάλης κλίμακας
- Επεξεργασία ροής: Αφού τα θέματα Kafka καταναλώνονται ως ακατέργαστα δεδομένα στην επεξεργασία αγωγών σε διάφορα στάδια, συγκεντρώνονται, εμπλουτίζονται ή μετατρέπονται με άλλο τρόπο σε νέα θέματα για περαιτέρω κατανάλωση ή επεξεργασία
- Εξάρσεις συστήματος αποσύνθεσης
- Ενσωματωμάτων Με Spark, Flink, Storm, Hadoop και άλλες μεγάλες τεχνολογίες δεδομένων
Οι εταιρείες που χρησιμοποιούν το Kafka για επεξεργασία δεδομένων
Ως αποτέλεσμα της ευελιξίας και της λειτουργικότητάς του, η Kafka χρησιμοποιείται από μερικούς από τον κόσμο’Οι ταχύτερα αναπτυσσόμενες εταιρείες τεχνολογίας για διάφορους σκοπούς:
- Uber-Συγκεντρώστε δεδομένα χρήστη, ταξί και ταξιδιού σε πραγματικό χρόνο για να υπολογίσετε και να προβλέψετε τη ζήτηση και να υπολογίσετε την τιμολόγηση της αύξησης σε πραγματικό χρόνο
- LinkedIn-Αποτρέπει το ανεπιθύμητο και συλλέγει αλληλεπιδράσεις χρήστη για να κάνει καλύτερες συστάσεις σύνδεσης σε πραγματικό χρόνο
- Twitter – Μέρος της υποδομής επεξεργασίας ροής καταιγίδων
- Spotify – μέρος του συστήματος παράδοσης καταγραφής
- Pinterest – μέρος του αγωγού συλλογής καταγραφής του
- Airbnb – αγωγός συμβάντων, παρακολούθηση εξαίρεσης κ.λπ.
- Cisco – για το OpenSoc (Κέντρο Επιχειρήσεων Ασφαλείας)
Ομάδα αξίας’Εμπειρία στο Kafka
Στο Merit Group, εργαζόμαστε με μερικούς από τον κόσμο’Οι κορυφαίες εταιρείες πληροφοριών B2B όπως Wilmington, Dow Jones, Glenigan και Haymarket. Οι ομάδες δεδομένων και μηχανικών μας συνεργάζονται στενά με τους πελάτες μας για την οικοδόμηση προϊόντων δεδομένων και εργαλείων επιχειρηματικών πληροφοριών. Η δουλειά μας επηρεάζει άμεσα την ανάπτυξη των επιχειρήσεων, βοηθώντας τους πελάτες μας να εντοπίσουν ευκαιρίες υψηλής ανάπτυξης.
Οι συγκεκριμένες υπηρεσίες μας περιλαμβάνουν συλλογή δεδομένων μεγάλου όγκου, μετασχηματισμό δεδομένων χρησιμοποιώντας AI και ML, Web Watch και προσαρμοσμένη ανάπτυξη εφαρμογών.
Η ομάδα μας φέρνει επίσης στο τραπέζι βαθιά τεχνογνωσία για την οικοδόμηση εφαρμογών ροής δεδομένων και επεξεργασίας δεδομένων σε πραγματικό χρόνο. Η εμπειρία μας στο Kafka είναι ιδιαίτερα χρήσιμη σε αυτό το πλαίσιο.
ПиINцIцINERY часчастчасии CORRUENT
Σε συστήματα αρχιτέκτονα που καταγράφουν και αντλούν την κατάσταση του συστήματος, η Netflix αξιοποιεί το Apache Kafka και την κατανεμημένη διακυβέρνηση. Νιτίνη. Μοιράζονται πώς αυτό τους βοηθά να επιτύχουν ορατότητα και αποσύνδεση στην υποδομή τους, ενώ οργανώνουν βιολογικές λειτουργίες: https: // lnkd.in/gfxaa6g
Πώς το Netflix χρησιμοποιεί το Kafka για κατανεμημένη ροή
παραπόταμος.IO
- Kolпиров επίσης
- Κελάδημα
Πιστός, σύζυγος, πατέρας 5, Διευθυντής Υποδομής και Υπηρεσιών, Επικεφαλής της Ομάδας, Developer.
Το Netflix δημιουργεί μια αξιόπιστη, κλιμακωτή πλατφόρμα με την προμήθεια συμβάντων, το MQTT και το Alpakka-Kafka
Η Netflix δημοσίευσε πρόσφατα μια δημοσίευση στο blog που περιγράφει λεπτομερώς τον τρόπο με τον οποίο δημιούργησε μια αξιόπιστη πλατφόρμα διαχείρισης συσκευών χρησιμοποιώντας μια υλοποίηση συμβάντων που βασίζεται σε MQTT. Για να κλιμακωθεί η λύση του, η Netflix χρησιμοποιεί Apache Kafka, Alpakka-Kafka και CockroachDB.
Η πλατφόρμα διαχείρισης συσκευών της Netflix είναι το σύστημα που διαχειρίζεται τις συσκευές υλικού που χρησιμοποιούνται για αυτοματοποιημένη δοκιμή των εφαρμογών του. Οι μηχανικοί Netflix Benson Ma και Alok Ahuja περιγράφουν το ταξίδι που πέρασε η πλατφόρμα:
Η επεξεργασία των ροών Kafka μπορεί να είναι δύσκολο να γίνει σωστό. (. ) Ευτυχώς, τα πρωτόγονα που παρέχονται από την Akka Streams και την Alpakka-Kafka μας εξουσιοδοτούν να επιτύχουμε ακριβώς αυτό επιτρέποντάς μας να οικοδομήσουμε λύσεις ροής που ταιριάζουν με τις επιχειρηματικές ροές εργασίας που έχουμε κατά την κλιμάκωση της παραγωγικότητας των προγραμματιστών στην οικοδόμηση και τη διατήρηση αυτών των λύσεων. Με τον επεξεργαστή που βασίζεται στον Alpakka-Kafka (. ), έχουμε εξασφαλίσει την ανοχή σφάλματος στην πλευρά των καταναλωτών του επιπέδου ελέγχου, το οποίο είναι το κλειδί για την ενεργοποίηση ακριβούς και αξιόπιστης συσσωμάτωσης κατάστασης συσκευών εντός της πλατφόρμας διαχείρισης συσκευών.
(. ) Η αξιοπιστία της πλατφόρμας και του επιπέδου ελέγχου της βασίζεται σε σημαντικές εργασίες που πραγματοποιήθηκαν σε διάφορους τομείς, συμπεριλαμβανομένης της μεταφοράς MQTT, της ταυτότητας και της εξουσιοδότησης και της παρακολούθησης των συστημάτων. (. ) Ως αποτέλεσμα αυτού του έργου, μπορούμε να αναμένουμε ότι η πλατφόρμα διαχείρισης συσκευών θα συνεχίσει να κλιμακώνεται με την αύξηση του φόρτου εργασίας με την πάροδο του χρόνου, καθώς επιτυγχάνουμε όλο και περισσότερες συσκευές στα συστήματά μας.
Το ακόλουθο διάγραμμα απεικονίζει την αρχιτεκτονική.

Πηγή: https: // netflixtechblog.com/forure-a-ογκώδη συσκευή-διαχείριση-πλατφόρμα-4f86230ca623
Ένας ενσωματωμένος υπολογιστής τοπικού περιβάλλοντος αναφοράς (RAE) συνδέεται με αρκετές συσκευές υπό δοκιμή (DUT). Η υπηρεσία τοπικής μητρώου είναι υπεύθυνη για την ανίχνευση, την επιβίβαση και τη διατήρηση πληροφοριών σχετικά με όλες τις συνδεδεμένες συσκευές στο RAE. Καθώς τα χαρακτηριστικά και οι ιδιότητες της συσκευής αλλάζουν με την πάροδο του χρόνου, εξοικονομεί αυτές τις αλλαγές στο τοπικό μητρώο και ταυτόχρονα δημοσιεύονται ανάντη σε ένα επίπεδο ελέγχου που βασίζεται σε σύννεφο. Εκτός από τις αλλαγές χαρακτηριστικών, το τοπικό μητρώο δημοσιεύει ένα πλήρες στιγμιότυπο της εγγραφής της συσκευής σε τακτά χρονικά διαστήματα. Αυτά τα συμβάντα σημείου ελέγχου επιτρέπουν την ταχύτερη ανακατασκευή της κατάστασης από τους καταναλωτές της ροής δεδομένων ενώ φυλάσσουν τις χαμένες ενημερώσεις.
Οι ενημερώσεις δημοσιεύονται στο σύννεφο χρησιμοποιώντας το MQTT. Το MQTT είναι ένα πρότυπο πρωτόκολλο μηνυμάτων Oasis για το Διαδίκτυο των πραγμάτων (IoT). Πρόκειται για μια ελαφριά αλλά αξιόπιστη μεταφορά αποστολής μηνυμάτων δημοσίευσης/εγγραφής ιδανικού για τη σύνδεση απομακρυσμένων συσκευών με ένα μικρό αποτύπωμα κώδικα και ελάχιστο εύρος ζώνης δικτύου. Ο μεσίτης MQTT είναι υπεύθυνος για τη λήψη όλων των μηνυμάτων, φιλτράροντας τα και την αποστολή τους στους πελάτες που έχουν εγγραφεί ανάλογα.
Το Netflix χρησιμοποιεί το Apache Kafka σε ολόκληρο τον οργανισμό. Κατά συνέπεια, μια γέφυρα μετατρέπει τα μηνύματα MQTT σε αρχεία Kafka. Ορίζει το κλειδί εγγραφής στο θέμα MQTT που ανατέθηκε το μήνυμα. Οι Ma και Ahuja περιγράφουν ότι “δεδομένου ότι οι ενημερώσεις συσκευών που δημοσιεύονται στο MQTT περιέχουν το devely_session_id Στο θέμα, όλες οι ενημερώσεις πληροφοριών συσκευών για μια δεδομένη συνεδρία συσκευής θα εμφανιστούν αποτελεσματικά στο ίδιο διαμέρισμα Kafka, δίνοντάς μας έτσι μια σαφώς καθορισμένη παραγγελία μηνύματος για κατανάλωση.«
Το μητρώο Cloud καταπιεί τα δημοσιευμένα μηνύματα, τα επεξεργάζεται και ωθεί τα υλικά δεδομένα σε ένα datastore που υποστηρίζεται από το CockroachDB. Το CockroachDB είναι μια εφαρμογή μιας κατηγορίας συστημάτων RDBMS που ονομάζεται NewsQL. Ma και Ahuja Εξηγήστε την επιλογή του Netflix:
Το CockroachDB επιλέγεται ως το κατάστημα δεδομένων υποστήριξης, καθώς προσφέρει δυνατότητες SQL και το μοντέλο δεδομένων μας για τα αρχεία της συσκευής κανονικοποιήθηκε. Επιπλέον, σε αντίθεση με άλλα καταστήματα SQL, το CockroachDB έχει σχεδιαστεί από το έδαφος για να είναι οριζόντια κλιμακωτή, γεγονός που αντιμετωπίζει τις ανησυχίες μας σχετικά με την ικανότητα του Cloud Registry να κλιμακωθεί με τον αριθμό των συσκευών που έχουν επιβιβαστεί στην πλατφόρμα διαχείρισης συσκευών.
Το ακόλουθο διάγραμμα δείχνει τον αγωγό επεξεργασίας Kafka που περιλαμβάνει το μητρώο σύννεφων.
Πηγή: https: // netflixtechblog.com/forure-a-ογκώδη συσκευή-διαχείριση-πλατφόρμα-4f86230ca623
Η Netflix εξέτασε πολλά πλαίσια για την εφαρμογή των αγωγών επεξεργασίας ροής που απεικονίζονται παραπάνω. Αυτά τα πλαίσια περιλαμβάνουν ρεύματα Kafka, Spring Kafkalistener, Project Reactor και Flink. Τελικά επέλεξε το Alpakka-Kafka. Ο λόγος αυτής της επιλογής είναι ότι η Alpakka-Kafka παρέχει ενσωμάτωση της άνοιξης μαζί με τον “λεπτόκοκκο έλεγχο της επεξεργασίας ρεύματος, συμπεριλαμβανομένης της αυτόματης υποστήριξης πίσω-πίεσης και της εποπτείας των ροών.”Επιπλέον, σύμφωνα με τους Ma και Ahuja, Akka και Alpakka-Kafka είναι πιο ελαφρύ από τις εναλλακτικές λύσεις και επειδή είναι πιο ώριμα, το κόστος συντήρησης με την πάροδο του χρόνου θα είναι χαμηλότερο.
Η υλοποίηση με βάση το Alpakka-Kafka αντικατέστησε μια προηγούμενη άνοιξη Kafkalistsen. Οι μετρήσεις που μετρήθηκαν στη νέα εφαρμογή παραγωγής αποκαλύπτουν ότι η υποστήριξη της εγγενούς πίεσης της Alpakka-Kafka μπορεί να μειώσει δυναμικά την κατανάλωσή της Kafka. Σε αντίθεση με το kafkalistener, η alpakka-kafka δεν είναι κάτω από τα μηνύματα kafka. Επίσης, η πτώση των μέγιστων τιμών καθυστέρησης των καταναλωτών μετά την απελευθέρωση αποκάλυψε ότι η Alpakka-Kafka και οι δυνατότητες ροής του Akka αποδίδουν καλά σε κλίμακα, ακόμη και ενόψει των ξαφνικών φορτίων μηνυμάτων.

