


האם נטפליקס משתמשת בקאפקא?
בהשתתפות אפאצ’י קפקא בעולם אולפן ובעולם הכספים של נטפליקס
סיכום:
בנטפליקס, מרבית היישומים משתמשים בספריית לקוח Java כדי לייצר נתונים לצינור המפתח. הצינור מורכב מחזית אשכולות קפקא, האחראים על איסוף ומאגר נתונים, ואשכולות קפקא צרכנים, המכילים נושאים לצרכנים בזמן אמת. נטפליקס מפעילה בסך הכל 36 אשכולות קפקא מטפלים ביותר מ- 700 מיליארד הודעות מדי יום. כדי להשיג מסירה חסרת אובדן, הצינור מאפשר שיעור אובדן נתונים של פחות מ- 0.01%. המפיקים והמתווכים מוגדרים כדי להבטיח זמינות וחווית משתמש טובה.
נקודות מפתח:
- יישומי נטפליקס משתמשים בספריית לקוח Java כדי לייצר נתונים לצינור אבן המפתח
- יצרני קפקא מרובים קיימים בכל מופע יישום
- חזית אשכולות קפקא אוספים ומאגר הודעות
- אשכולות קפקא צרכנים מכילים נושאים עבור צרכנים בזמן אמת
- נטפליקס מפעילה 36 אשכולות קפקא עם למעלה מ- 700 מיליארד הודעות מדי יום
- שיעור אובדן הנתונים הוא פחות מ- 0.01%
- מפיקים ומתווכים מוגדרים כדי להבטיח זמינות
- המפיקים משתמשים בתצורה דינאמית לניתוב נושא ובידוד כיור
- יישומים שאינם Java יכולים לשלוח אירועים לנקודות קצה מנוחה של Keystone
- הזמנת הודעות נקבעת בשכבת עיבוד אצווה או ניתוב
שאלות:
- כיצד יישומי נטפליקס מייצרים נתונים לצינור אבן המפתח?
- מהם התפקידים של חזית אשכולות קפקא?
- אילו סוגים של אשכולות קפקא קיימים בצינור הקיסטון?
- כמה אשכולות קפקא פועלת נטפליקס?
- מהו שיעור בליעת הנתונים הממוצע עבור נטפליקס?
- מהי הגרסה הנוכחית של קפקא המשמשת את נטפליקס?
- איך נטפליקס משיגה משלוח חסר אובדן בצינור?
- מה התצורה עבור מפיקים ומתווכים כדי להבטיח זמינות?
- כיצד נשמרת הזמנת הודעות?
- מדוע יישומי לקוח אינם צורכים ישירות מחזית אשכולות קפקא?
- אילו אתגרים מתעוררים בעת הפעלת קפקא בענן?
- כיצד השכפול משפיע על זמינותו של קפקא?
- מה עשתה נטפליקס כדי לטפל באירועים ולשמור על יציבות האשכול?
- מהי אסטרטגיית הפריסה של נטפליקס עבור אשכולות קפקא?
רוב היישומים של נטפליקס משתמשים בספריית לקוח Java כדי לייצר נתונים לצינור המפתח. לכל מופע יישום יש יצרני קפקא מרובים.
חזית אשכולות קפקא אוספים ומאגר הודעות מהמפיקים. הם משמשים כשער להזריקת הודעה.
צינור הקיסטון מורכב מקבעת אשכולות קפקא ואשכולות קפקא צרכנים.
נטפליקס מפעילה 36 אשכולות קפקא.
נטפליקס בולעת מעל 700 מיליארד הודעות מדי יום.
נטפליקס עוברת מגרסת קפקא 0.8.2.1 עד 0.9.0.1.
בהתחשב בנפח נתונים עצום, נטפליקס עבדה עם צוותים כדי לקבל כמות מקובלת של אובדן נתונים, וכתוצאה מכך שיעור אובדן נתונים יומי של פחות מ- 0.01%.
המפיקים והמתווכים מוגדרים עם “acks = 1”, “בלוק.עַל.בַּלָם.מלא = שקר “, ו”לא טמא.מַנהִיג.בְּחִירָה.enable = true “.
המפיקים אינם משתמשים בהודעות מפתח, והזמנת ההודעות מבוססת מחדש בשכבת עיבוד האצווה או בשכבת הניתוב.
יישומי לקוח אינם רשאים לצרוך ישירות מחזית אשכולות קפקא כדי להבטיח עומס ויציבות צפויים.
הפעלת Kafka בענן מציבה אתגרים כמו מחזור חיים בלתי צפוי, בעיות רשת חולפות, ומחירים הגורמים לבעיות ביצועים.
שכפול משפר את הזמינות, אך מתווך מתאר יותר יכול לגרום לאפקטים מדורגים וירידה של הודעות בגלל פיגור שכפול ותשישות חיץ.
נטפליקס הפחיתה את המצב והמורכבות, יישמה גילוי מתקדם ופיתחה אמצעים להתאוששות במהירות מאירועים.
נטפליקס מעדיפה מספר אשכולות קפקא קטנים על אשכול ענק אחד כדי להפחית את התלות ולשפר את היציבות.
קפקא בתוך צינור קיסטון
יש לנו שתי קבוצות של אשכולות קפקא בצינור הקיסטון: חזית קפקא וצרכנים קפקא. חזית אשכולות Kafka אחראים על קבלת ההודעות מהמפיקים שהם כמעט כל מופע יישום בנטפליקס. התפקידים שלהם הם איסוף נתונים ומאגר למערכות במורד הזרם. אשכולות קפקא צרכנים מכילים תת קבוצה של נושאים המנותבים על ידי SAMZA לצרכנים בזמן אמת.
אנו מפעילים כיום 36 אשכולות Kafka המורכבים מ -4,000 מופעים של מתווך הן לחזית Kafka והן לצרכנים Kafka. יותר מ- 700 מיליארד הודעות נבלעות ביום ממוצע. אנו עוברים כרגע מגרסת קפקא 0.8.2.1 עד 0.9.0.1.
עקרונות עיצוב
בהתחשב בארכיטקטורת Kafka הנוכחית ונפח הנתונים העצום שלנו, כדי להשיג משלוח חסר אובדן עבור צינור הנתונים שלנו הוא עלות אוסרת ב- AWS EC2. חשבונו על זה, אנחנו’עבד עם צוותים התלויים בתשתית שלנו כדי להגיע לכמות מקובלת של אובדן נתונים, תוך איזון עלות. אָנוּ’VE השיג שיעור אובדן נתונים יומי של פחות מ- 0.01%. מדדים נאספים להודעות שנשמטו כך שנוכל לנקוט בפעולה במידת הצורך.
צינור הקיסטון מייצר הודעות באופן אסינכרוני מבלי לחסום יישומים. במקרה שלא ניתן להעביר הודעה לאחר ניסיון חוזר, היא תיפול על ידי המפיק כדי להבטיח את זמינות היישום וחווית המשתמש הטובה. זו הסיבה שבחרנו את התצורה הבאה עבור המפיק והמתווך שלנו:
- acks = 1
- לַחסוֹם.עַל.בַּלָם.מלא = שקר
- טָמֵא.מַנהִיג.בְּחִירָה.Enable = נכון
מרבית היישומים בנטפליקס משתמשים בספריית הלקוחות של Java כדי לייצר לצינור אבן המפתח. בכל מקרה של יישומים אלה, ישנם יצרני קפקא מרובים, כאשר כל אחד מהם מייצר לאשכול קפקא מקדח לבידוד ברמת הכיור. למפיקים יש ניתוב נושא גמיש ותצורת כיור המונעים באמצעות תצורה דינמית שניתן לשנות בזמן ריצה מבלי שתצטרך להפעיל מחדש את תהליך היישום. זה מאפשר לדברים כמו להפנות מחדש תנועה והעברת נושאים על פני אשכולות קפקא. עבור יישומים שאינם ג’אווה הם יכולים לבחור לשלוח אירועים לנקודות קצה המנוחה של Keystone המסייעות הודעות לחזית אשכולות קפקא.
לצורך גמישות רבה יותר, המפיקים אינם משתמשים בהודעות מפתח. הזמנת הודעות משוערת מבוססת מחדש בשכבת עיבוד האצווה (HIVE / Elasticsearch) או בשכבת ניתוב לצרכנים זורמים.
שמנו את היציבות של אשכולות הקפקא החזיתיים שלנו בעדיפות גבוהה מכיוון שהם השער להזריקת הודעה. לכן איננו מאפשרים ליישומי לקוחות לצרוך מהם ישירות כדי לוודא שיש להם עומס צפוי.
אתגרי הפעלת קפקא בענן
קפקא פותח עם מרכז הנתונים כיעד הפריסה בלינקדאין. עשינו מאמצים בולטים לגרום לקאפקא לרוץ טוב יותר בענן.
בענן, במקרים יש מחזור חיים בלתי צפוי וניתן להפסיק אותו בכל עת בגלל בעיות חומרה. צפויים בעיות ברשת חולפות. אלה אינן בעיות לשירותים חסרי מדינה, אך מהווים אתגר גדול לשירות ממלכתי המחייב את ZookeEper ובקר יחיד לתיאום.
רוב הנושאים שלנו מתחילים במתווכים מתקדמים יותר. מתווה יכול להיגרם כתוצאה מעומס עבודה לא אחיד, בעיות חומרה או סביבתו הספציפית, למשל, שכנים רועשים בגלל ריבוי שכר טרחה. מתווך מתקדם עשוי להיות בעל תגובות איטיות לבקשות או פסק זמן/פסקות TCP תכופות. למפיקים ששולחים אירועים למתווך כזה יהיה סיכוי טוב למצות את המאגרים המקומיים שלהם בזמן שהם מחכים לתגובות, לאחר מכן ירידת ההודעה הופכת להיות וודאות. הגורם התורם הנוסף למאגר תשישות הוא ש- Kafka 0.8.2 מפיק לא’T תומך בפסק זמן להודעות הממתינות במאגר.
קפקא’שכפול S משפר את הזמינות. עם זאת, שכפול מוביל לתלות בין מתווכים שבהם מתאר יותר יכול לגרום להשפעה מדורגת. אם מתאר יותר מאט את שכפול, פיגור שכפול עשוי להצטבר ובסופו של דבר לגרום למנהיגי המחיצה לקרוא מהדיסק כדי לשרת את בקשות השכפול. זה מאט את המתווכים שנפגעו ובסופו.
בימינו הראשונים של הפעלת קפקא, חווינו אירוע בו היצרנים הפילו כמות משמעותית של הודעות לאשכול קפקא עם מאות מקרים בגלל סוגיית זוקאפר בזמן שהיינו יכולים לעשות מעט. ניפוי באגים כמו זה בחלון זמן קטן עם מאות מתווכים זה פשוט לא מציאותי.
בעקבות האירוע נעשו מאמצים להפחית את המצב והמורכבות עבור אשכולות הקפקא שלנו, לגלות מחזורים ולמצוא דרך להתחיל במהירות עם מצב נקי כאשר מתרחש אירוע.
אסטרטגיית פריסת קפקה
להלן אסטרטגיות המפתח בהן השתמשנו לפריסת אשכולות קפקא:
- לטובת אשכולות קפקא קטנים מרובים לעומת אשכול ענק אחד. זה מקטין את התלות ומשפר את היציבות.
- ליישם מנגנוני גילוי מתקדמים כדי לזהות ולטפל במתווכים בעייתיים.
- לפתח אמצעים להתאוששות במהירות מאירועים ולהתחיל במצב נקי.
בהשתתפות אפאצ’י קפקא בעולם אולפן ובעולם הכספים של נטפליקס
מרבית היישומים בנטפליקס משתמשים בספריית הלקוחות של Java כדי לייצר לצינור אבן המפתח. בכל מקרה של יישומים אלה, ישנם יצרני קפקא מרובים, כאשר כל אחד מהם מייצר לאשכול קפקא מקדח לבידוד ברמת הכיור. למפיקים יש ניתוב נושא גמיש ותצורת כיור המונעים באמצעות תצורה דינמית שניתן לשנות בזמן ריצה מבלי שתצטרך להפעיל מחדש את תהליך היישום. זה מאפשר לדברים כמו להפנות מחדש תנועה והעברת נושאים על פני אשכולות קפקא. עבור יישומים שאינם ג’אווה הם יכולים לבחור לשלוח אירועים לנקודות קצה המנוחה של Keystone המסייעות הודעות לחזית אשכולות קפקא.
קפקא בתוך צינור קיסטון
יש לנו שתי קבוצות של אשכולות קפקא בצינור הקיסטון: חזית קפקא וצרכנים קפקא. חזית אשכולות Kafka אחראים על קבלת ההודעות מהמפיקים שהם כמעט כל מופע יישום בנטפליקס. התפקידים שלהם הם איסוף נתונים ומאגר למערכות במורד הזרם. אשכולות קפקא צרכנים מכילים תת קבוצה של נושאים המנותבים על ידי SAMZA לצרכנים בזמן אמת.
אנו מפעילים כיום 36 אשכולות Kafka המורכבים מ -4,000 מופעים של מתווך הן לחזית Kafka והן לצרכנים Kafka. יותר מ- 700 מיליארד הודעות נבלעות ביום ממוצע. אנו עוברים כרגע מגרסת קפקא 0.8.2.1 עד 0.9.0.1.
עקרונות עיצוב
בהתחשב בארכיטקטורת Kafka הנוכחית ונפח הנתונים העצום שלנו, כדי להשיג משלוח חסר אובדן עבור צינור הנתונים שלנו הוא עלות אוסרת ב- AWS EC2. חשבונו על זה, אנחנו’עבד עם צוותים התלויים בתשתית שלנו כדי להגיע לכמות מקובלת של אובדן נתונים, תוך איזון עלות. אָנוּ’VE השיג שיעור אובדן נתונים יומי של פחות מ- 0.01%. מדדים נאספים להודעות שנשמטו כך שנוכל לנקוט בפעולה במידת הצורך.
צינור הקיסטון מייצר הודעות באופן אסינכרוני מבלי לחסום יישומים. במקרה שלא ניתן להעביר הודעה לאחר ניסיון חוזר, היא תיפול על ידי המפיק כדי להבטיח את זמינות היישום וחווית המשתמש הטובה. זו הסיבה שבחרנו את התצורה הבאה עבור המפיק והמתווך שלנו:
- acks = 1
- לַחסוֹם.עַל.בַּלָם.מלא = שקר
- טָמֵא.מַנהִיג.בְּחִירָה.Enable = נכון
מרבית היישומים בנטפליקס משתמשים בספריית הלקוחות של Java כדי לייצר לצינור אבן המפתח. בכל מקרה של יישומים אלה, ישנם יצרני קפקא מרובים, כאשר כל אחד מהם מייצר לאשכול קפקא מקדח לבידוד ברמת הכיור. למפיקים יש ניתוב נושא גמיש ותצורת כיור המונעים באמצעות תצורה דינמית שניתן לשנות בזמן ריצה מבלי שתצטרך להפעיל מחדש את תהליך היישום. זה מאפשר לדברים כמו להפנות מחדש תנועה והעברת נושאים על פני אשכולות קפקא. עבור יישומים שאינם ג’אווה הם יכולים לבחור לשלוח אירועים לנקודות קצה המנוחה של Keystone המסייעות הודעות לחזית אשכולות קפקא.
לצורך גמישות רבה יותר, המפיקים אינם משתמשים בהודעות מפתח. הזמנת הודעות משוערת מבוססת מחדש בשכבת עיבוד האצווה (HIVE / Elasticsearch) או בשכבת ניתוב לצרכנים זורמים.
שמנו את היציבות של אשכולות הקפקא החזיתיים שלנו בעדיפות גבוהה מכיוון שהם השער להזריקת הודעה. לכן איננו מאפשרים ליישומי לקוחות לצרוך מהם ישירות כדי לוודא שיש להם עומס צפוי.
אתגרי הפעלת קפקא בענן
קפקא פותח עם מרכז הנתונים כיעד הפריסה בלינקדאין. עשינו מאמצים בולטים לגרום לקאפקא לרוץ טוב יותר בענן.
בענן, במקרים יש מחזור חיים בלתי צפוי וניתן להפסיק אותו בכל עת בגלל בעיות חומרה. צפויים בעיות ברשת חולפות. אלה אינן בעיות לשירותים חסרי מדינה, אך מהווים אתגר גדול לשירות ממלכתי המחייב את ZookeEper ובקר יחיד לתיאום.
רוב הנושאים שלנו מתחילים במתווכים מתקדמים יותר. מתווה יכול להיגרם כתוצאה מעומס עבודה לא אחיד, בעיות חומרה או סביבתו הספציפית, למשל, שכנים רועשים בגלל ריבוי שכר טרחה. מתווך מתקדם עשוי להיות בעל תגובות איטיות לבקשות או פסק זמן/פסקות TCP תכופות. למפיקים ששולחים אירועים למתווך כזה יהיה סיכוי טוב למצות את המאגרים המקומיים שלהם בזמן שהם מחכים לתגובות, לאחר מכן ירידת ההודעה הופכת להיות וודאות. הגורם התורם הנוסף למאגר תשישות הוא ש- Kafka 0.8.2 מפיק לא’T תומך בפסק זמן להודעות הממתינות במאגר.
קפקא’שכפול S משפר את הזמינות. עם זאת, שכפול מוביל לתלות בין מתווכים שבהם מתאר יותר יכול לגרום להשפעה מדורגת. אם מתאר יותר מאט את שכפול, פיגור שכפול עשוי להצטבר ובסופו של דבר לגרום למנהיגי המחיצה לקרוא מהדיסק כדי לשרת את בקשות השכפול. זה מאט את המתווכים שנפגעו ובסופו.
בימינו הראשונים של הפעלת קפקא, חווינו אירוע בו היצרנים הפילו כמות משמעותית של הודעות לאשכול קפקא עם מאות מקרים בגלל סוגיית זוקאפר בזמן שהיינו יכולים לעשות מעט. ניפוי באגים כמו זה בחלון זמן קטן עם מאות מתווכים זה פשוט לא מציאותי.
בעקבות האירוע נעשו מאמצים להפחית את המצב והמורכבות עבור אשכולות הקפקא שלנו, לגלות מחזורים ולמצוא דרך להתחיל במהירות עם מצב נקי כאשר מתרחש אירוע.
אסטרטגיית פריסת קפקה
להלן אסטרטגיות המפתח בהן השתמשנו לפריסת אשכולות קפקא
- לטובת אשכולות קפקא קטנים מרובים לעומת אשכול ענק אחד. זה מצמצם את המורכבות המבצעית עבור כל אשכול. לאשכול הגדול ביותר שלנו יש פחות מ -200 מתווכים.
- הגבל את מספר המחיצות בכל אשכול. לכל אשכול יש פחות מ -10,000 מחיצות. זה משפר את הזמינות ומפחית את החביון לבקשות/תגובות המחויבות למספר המחיצות.
- שאפו אפילו להפצה של העתקים לכל נושא. אפילו עומס עבודה קל יותר לתכנון קיבולת וגילוי של מחקרים.
- השתמש באשכול Zookeeper ייעודי לכל אשכול קפקא כדי להפחית את ההשפעה של סוגיות Zookeeper.
הטבלה הבאה מציגה את תצורות הפריסה שלנו.
קפקא כישלון
אוטומציה של תהליך בו אנו יכולים להיכשל גם בתנועה של יצרן וגם לצרכן (נתב) לאשכול קפקא חדש כאשר האשכול הראשוני נמצא בבעיה. לכל אשכול קפקא חזית, יש אשכול המתנה קר עם תצורת שיגור רצויה אך קיבולת ראשונית מינימלית. כדי להבטיח מצב נקי מלכתחילה, לאשכול Failover אין נושאים שנוצרו ואינו חולק את אשכול Zookeeper עם אשכול הקפקא הראשי. אשכול Failover נועד גם להיות גורם שכפול 1 כך שהוא יהיה חופשי מכל סוגיות שכפול.
כאשר נכשל, ננקטים הצעדים הבאים כדי להסיט את היצרן ואת תנועת הצרכנים:
- שינוי גודל של אשכול Failover עד הגודל הרצוי.
- צור נושאים והשיק עבודות ניתוב עבור אשכול Failover במקביל.
- (אופציונלי) לחכות למנהיגי המחיצות שיוקמו על ידי הבקר כדי למזער את ירידת ההודעות הראשונית בעת הפקה אליו.
- שנה באופן דינמי את תצורת היצרן כדי להחליף את תנועת היצרנים לאשכול Failover.
ניתן לתאר את תרחיש Failover על ידי התרשים הבא:
עם האוטומציה המלאה של התהליך, אנו יכולים לעשות כישלון תוך פחות מחמש דקות. לאחר שכישלון הושלם בהצלחה, נוכל לבצע ניפוי באגים בבעיות עם האשכול המקורי באמצעות יומנים ומדדים. אפשר גם להרוס לחלוטין את האשכול ולבנות מחדש עם תמונות חדשות לפני שנחזור את התנועה חזרה. למעשה, לעתים קרובות אנו משתמשים באסטרטגיית Failover כדי להסיט את התנועה תוך כדי תחזוקה לא מקוונת. כך אנו משדרגים את אשכולות הקפקא שלנו לגירסת קפקא החדשה מבלי שנצטרך לבצע את השדרוג המתגלגל או להגדיר את גרסת פרוטוקול התקשורת הבין-מתווך.
פיתוח לקפקא
פיתחנו די הרבה כלים שימושיים עבור קפקא. להלן כמה מהדגשים:
מפיק דביק
זוהי מחיצה מיוחדת בהתאמה אישית שפיתחנו עבור ספריית המפיקים של Java שלנו. כפי שהשם מרמז, הוא נדבק למחיצה מסוימת לייצור זמן הניתן להגדרה לפני שהוא בוחר באופן אקראי את המחיצה הבאה. גילינו ששימוש במחיצה דביקה יחד עם התנהלות עוזר לשפר את אצוות ההודעות ולהקטין את העומס עבור המתווך. להלן הטבלה שתציג את ההשפעה של המפלגה הדביקה:
מטלת העתק מודעת למתלה
כל אשכולות הקפקא שלנו משתרעים על פני שלושה אזורי זמינות AWS. אזור זמינות AWS הוא מתלה רעיוני. כדי להבטיח זמינות למקרה שאזור אחד יירד, פיתחנו את הקצאת העתק המודע (אזור) מודעת כך ששכפולים לאותו נושא יוקצו לאזורים שונים. זה לא רק עוזר להפחית את הסיכון להפסקת אזור, אלא גם משפר את הזמינות שלנו כאשר מתווכים מרובים ממוקמים יחד באותו מארח פיזי מסתיימים בגלל בעיות מארח. במקרה זה, יש לנו סובלנות טובה יותר לתקלות מאשר קפקא’s n – 1 כאשר n הוא גורם השכפול.
העבודה תורמת לקהילת Kafka ב- KIP-36 ולבקשת משיכה Apache Kafka github #132.
Kafka Metadata Visualizer
קפקא’מטא נתונים S מאוחסנים ב- Zookeeper. עם זאת, קשה לנווט בתצוגת העץ המסופקת על ידי המציגה והיא הולכת זמן רב למצוא ולתאם בין מידע.
יצרנו ממשק משתמש משלנו כדי לדמיין את המטא נתונים. הוא מספק תצוגות תרשים וגם טבלאות ומשתמש בתכניות צבע עשירות כדי לציין את מצב ISR. תכונות המפתח הן הבאות:
- כרטיסייה פרטנית לתצוגות למתווכים, נושאים ואשכולות
- רוב המידע ניתן למיון וניתן לחיפוש
- מחפש נושאים בין אשכולות
- מיפוי ישיר ממזהה מתווך למזהה מופע AWS
- מתאם בין מתווכים על ידי מערכת היחסים המנהיגים
להלן צילומי המסך של ממשק המשתמש:
ניטור
יצרנו שירות ניטור ייעודי עבור Kafka. זה אחראי למעקב:
- סטטוס מתווך (באופן ספציפי, אם הוא לא מקוון מ- Zookeeper)
- סַרְסוּר’היכולת לקבל הודעות ממפיקים ולהעביר הודעות לצרכנים. שירות הניטור פועל כמפיק וגם כצרכן עבור הודעות פעימות לב רציפות ומודד את החביון של הודעות אלה.
- עבור צרכנים מבוססי Zookeeper ישנים, הוא עוקב אחר ספירת המחיצות עבור קבוצת הצרכנים כדי לוודא שכל מחיצה נצרכת.
- עבור נתבי Samza של Keystone, זה עוקב אחר הקיזוזים המבוססים ומשתווה למתווך’S קיזוזי יומן כדי לוודא שהם אינם תקועים ואין להם פיגור משמעותי.
בנוסף, יש לנו לוחות מחוונים נרחבים כדי לפקח על זרימת התנועה לרמת נושא ולרוב המתווך’מדדים.
תוכנית עתידית
אנו נמצאים כרגע בתהליך של העברה לקפקא 0.9, שיש בו לא מעט תכונות בהן אנו רוצים להשתמש כולל ממשקי API צרכנים חדשים, פסק זמן של הודעת מפיק ומכסות. אנו גם נעביר את אשכולות הקפקא שלנו ל- AWS VPC ונאמין שהרשתות המשופרות שלה (בהשוואה ל- EC2 Classic) ייתן לנו יתרון לשיפור הזמינות וניצול המשאבים.
אנו הולכים להציג SLA שכבה לנושאים. עבור נושאים שיכולים לקבל אובדן קל, אנו שוקלים להשתמש העתק אחד. ללא שכפול, אנו לא רק חוסכים ענק ברוחב הפס, אלא גם ממזער את שינויי המצב שצריכים להיות תלויים בבקר. זהו צעד נוסף להפוך את קפקא למצב פחות בסביבה המעדיפה שירותים חסרי מדינה. החיסרון הוא אובדן ההודעה הפוטנציאלי כאשר מתווך נעלם. עם זאת, על ידי מינוף פסק הזמן של הודעת המפיק ב- 0.9 שחרור ואולי AWS EBS נפח, אנו יכולים להקל על האובדן.
הישאר מעודכן לבלוגים עתידיים של Keystone בתשתית הניתוב שלנו, ניהול מכולות, עיבוד זרם ועוד!
בהשתתפות אפאצ’י קפקא בעולם אולפן ובעולם הכספים של נטפליקס
נטפליקס הוציאה כ -15 מיליארד דולר כדי לייצר תוכן מקורי ברמה העולמית בשנת 2019. כאשר ההימור כל כך גבוה, חשוב ביותר לאפשר לעסק שלנו עם תובנות ביקורתיות המסייעות בתכנון, לקבוע את ההוצאות ולהגביר את כל תוכן Netflix. תובנות אלה יכולות לכלול:
- כמה עלינו לבלות בשנה הבאה על סרטים וסדרות בינלאומיות?
- האם אנו מגנדרים לעבור על תקציב הייצור שלנו והאם מישהו צריך להיכנס כדי לשמור על דברים על המסלול?
- כיצד אנו מתכנתים קטלוג שנים מראש עם נתונים, אינטואיציה ואנליטיקס כדי לעזור ביצירת הצפחה הטובה ביותר האפשרית?
- כיצד אנו מייצרים כספים לתכנים ברחבי העולם ומדווחים לוול סטריט?
בדומה לאופן בו VCS מכוונים בקפדנות את עיןם להשקעות טובות, צוות ההנדסה של מימון התוכן’אמנת S היא לעזור לנטפליקס להשקיע, לעקוב וללמוד מהפעולות שלנו כך שנשקיע ברציפות השקעות טובות יותר בעתיד.
לחבק אירועים
מבחינה הנדסית, כל יישום פיננסי מיושם ומיושם כשירות מיקרו. נטפליקס מחבקת ממשל מבוזר ומעודדת גישה מונעת שירותי מיקרו ליישומים, המסייעת בהשגת האיזון הנכון בין הפשטת נתונים למהירות כאשר החברה מתרחשת. בעולם פשוט, שירותים יכולים לקיים אינטראקציה באמצעות HTTP בסדר גמור, אך כאשר אנו מתרחשים, הם מתפתחים לתרשים מורכב של אינטראקציות סינכרוניות ומבוססות על בקשה שיכולות להוביל למוח/מצב מפוצל ולשבש את הזמינות.
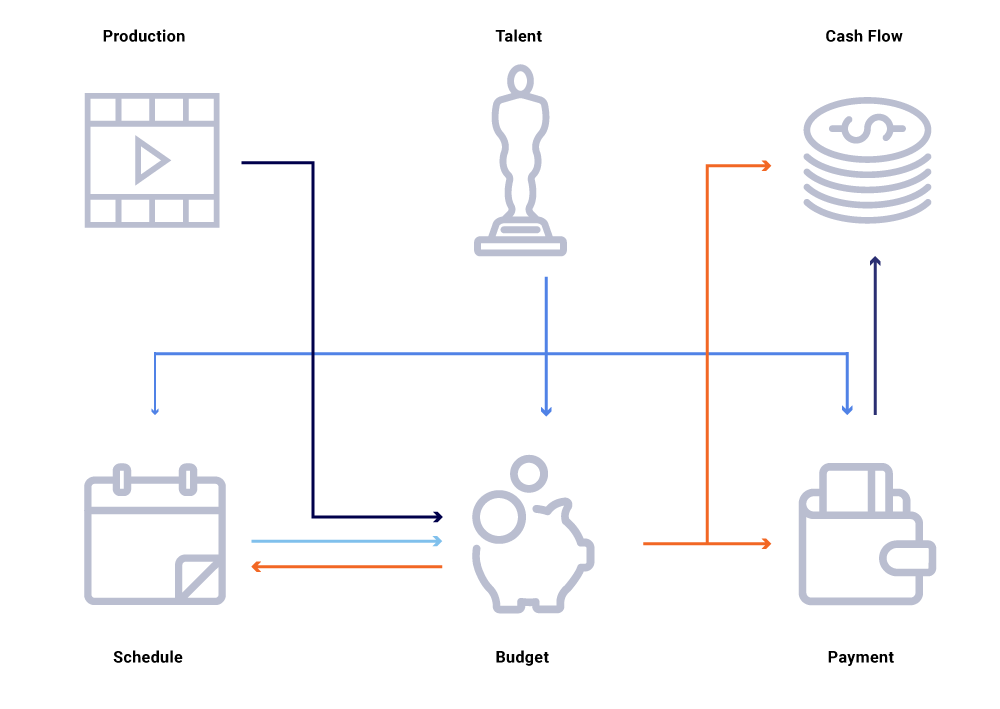
קחו בחשבון בתרשים לעיל של ישויות קשורות, שינוי בתאריך הייצור של מופע. זה משפיע על צפחה של התכנות שלנו, אשר בתורו משפיע על פרויקטים של תזרים מזומנים, תשלומי כישרון, תקציבים לשנה וכו ‘. לעתים קרובות בארכיטקטורת שירות מיקרו, אחוז מסוים של כישלון מקובל. עם זאת, כישלון בכל אחת מהשירות המיקרו -שיחות להנדסת מימון תוכן יוביל לכך ששפע של חישובים לא מסונכרנים ויכול לגרום לכך שהנתונים יופעלו על ידי מיליוני דולרים. זה גם יוביל לבעיות זמינות כאשר גרף השיחה משתרע ויגרום לנקודות עיוורות תוך ניסיון לאתר ביעילות ולענות על שאלות עסקיות, כגון: מדוע תחזיות תזרים מזומנים חורגים מלוח זמנים ההשקה שלנו? מדוע התחזית לשנה הנוכחית אינה לוקחת בחשבון את ההצגות שנמצאות בפיתוח פעיל? מתי אנו יכולים לצפות שדוחות העלויות שלנו ישקפו במדויק את השינויים במעלה הזרם?
מחשבה מחדש על אינטראקציות שירות כזרמים של חילופי אירועים – בניגוד לרצף של בקשות סינכרוניות – באים לנו לבנות תשתית שהיא מטבעו אסינכרונית. זה מקדם ניתוק ומספק עקיבות כאזרח מהשורה הראשונה ברשת של עסקאות מבוזרות. האירועים הם הרבה יותר מאשר טריגרים ועדכונים. הם הופכים לזרם הבלתי ניתן לשינוי ממנו אנו יכולים לשחזר את כל מצב המערכת.
התקדמות לעבר מודל פרסום/מנוי מאפשרת לכל שירות לפרסם את השינויים שלו כאירועים לאוטובוס הודעה, שאפשר לצרוך אותה על ידי שירות אחר בעל עניין שצריך להתאים את מצב העולם שלו. מודל כזה מאפשר לנו לעקוב אחר השירותים מסונכרנים ביחס לשינויי מצב, ואם לא, כמה זמן לפני שהם יכולים להיות בסנכרון. תובנות אלה חזקות ביותר בעת הפעלת גרף גדול של שירותים תלויים. תקשורת מבוססת אירועים וצריכה מבוזרת עוזרים לנו להתגבר על סוגיות שאנו רואים בדרך כלל בתרשימי שיחה סינכרוניים גדולים (כאמור לעיל).
נטפליקס מחבקת את Apache Kafka ® כתקן De-Facto לצרכי עיבוד האירועים, ההודעות והזרם שלו. קפקא משמש כגשר לכל תקשורת רחבה לנקודה לנקודה ונטפליקס תקשורת רחבה. זה מספק לנו את העמידות הגבוהה והארכיטקטורה הרב-דייר המדרגית לינארית הנדרשת למערכות הפעלה בנטפליקס. הקפקא הפנימי שלנו כמציע שירות מספק סובלנות לתקלות, יכולת תצפית, פריסות רב-אזורים ושירות עצמי. זה מקל על כל המערכת האקולוגית שלנו של שירותי מיקרו לייצר בקלות ולצרוך אירועים משמעותיים ולשחרר את כוחה של תקשורת אסינכרונית.
החלפת הודעות טיפוסית בתוך מערכת האקולוגית של Studio Studio נראית כך:
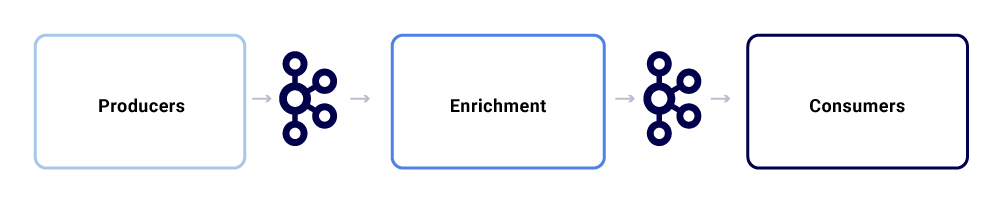
אנחנו יכולים לפרק אותם כשלושה רכיבי משנה עיקריים.
מפיקים
מפיק יכול להיות כל מערכת שרוצה לפרסם את כל מצבה או לרמוז כי חלק קריטי ממצבה הפנימי השתנה עבור ישות מסוימת. מלבד העומס, אירוע צריך לדבוק בפורמט מנורמל, מה שמקל על עקבותיו והבנה. פורמט זה כולל:
- Uuid: מזהה ייחודי אוניברסלי
- סוּג: אחד מסוגי היצירה, הקריאה, העדכון או מחק (CRUD)
- TS: חותמת זמן של האירוע
שינוי כלים לכידת נתונים (CDC) הם קטגוריה נוספת של מפיקי אירועים שמפיקים אירועים משינויי מסד נתונים. זה יכול להיות שימושי כאשר ברצונך להנגיש שינויים בבסיס נתונים לרבים צרכנים. אנו משתמשים גם בתבנית זו כדי לשכפל את אותם נתונים על פני מרכזי נתונים (עבור מסדי נתונים יחידים). דוגמה לכך היא שיש לנו נתונים ב- MySQL שצריך לאינדקס ב- Elasticsearch או Apache Solr ™. היתרון בשימוש ב- CDC הוא שהוא אינו מטיל עומס נוסף על יישום המקור.
עבור אירועי CDC, שדה הסוג בפורמט האירוע מקל על הסתגלות ושינוי אירועים כנדרש בכיורים המתאימים.
מעשרים
ברגע שקיימים נתונים בקפקא, ניתן ליישם עליהם דפוסי צריכה שונים. אירועים משמשים במובנים רבים, כולל כטריגרים לחישובי מערכת, העברת עומס על תקשורת כמעט אמיתית, ורמזים להעשרה ולהתממש בתצוגות זיכרון של נתונים.
העשרת נתונים הופכת נפוצה יותר ויותר כאשר שירותי מיקרו זקוקים לתצוגה המלאה של מערך נתונים אך חלק מהנתונים מגיע משירות אחר’מערך נתונים. מערך נתונים שהצטרף יכול להיות שימושי לשיפור ביצועי השאילתה או מתן תצוגה כמעט אמיתית של נתונים מצטברים. כדי להעשיר את נתוני האירועים, הצרכנים קוראים את הנתונים מ- Kafka ומתקשרים לשירותים אחרים (בשיטות הכוללות GRPC ו- GraphQL) לבניית מערך הנתונים המצטרף, אשר אז מוזנים אחר כך לנושאי Kafka אחרים.
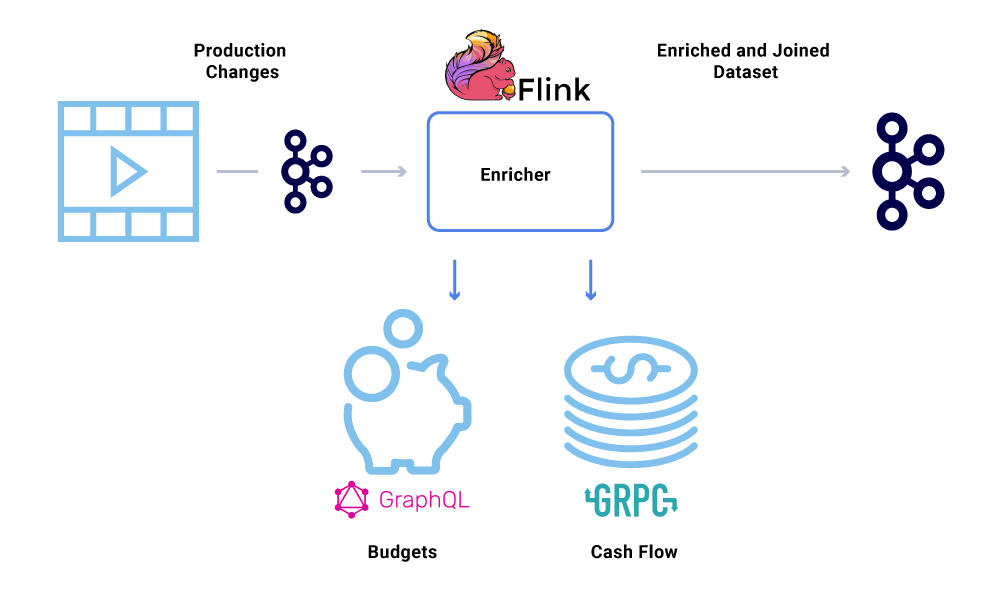
העשרה יכולה להיות מופעלת כשירות מיקרו נפרד בעצמו האחראי על ביצוע המאוורר ולמימון מערכי נתונים. ישנם מקרים שבהם אנו רוצים לבצע עיבוד מורכב יותר כמו חלון, הפעלה וניהול מדינה. במקרים כאלה, מומלץ להשתמש במנוע עיבוד זרם בוגר על גבי קפקא כדי לבנות היגיון עסקי. ב- Netflix אנו משתמשים ב- Apache Flink ® ו- RockSDB כדי לבצע עיבוד זרם. אָנוּ’מחדש בהתחשב ב- KSQLDB למטרות דומות.
הזמנת אירועים
אחת מדרישות המפתח במערך נתונים פיננסי היא הזמנת האירועים הקפדנית. Kafka עוזר לנו להשיג זאת הוא על ידי שליחת הודעות מפתח. לכל אירוע או הודעה שנשלחת עם אותו מפתח, יהיה לו הזמנה מובטחת מכיוון שהם נשלחים לאותה מחיצה. עם זאת, המפיקים עדיין יכולים לבלגן את סדר האירועים.
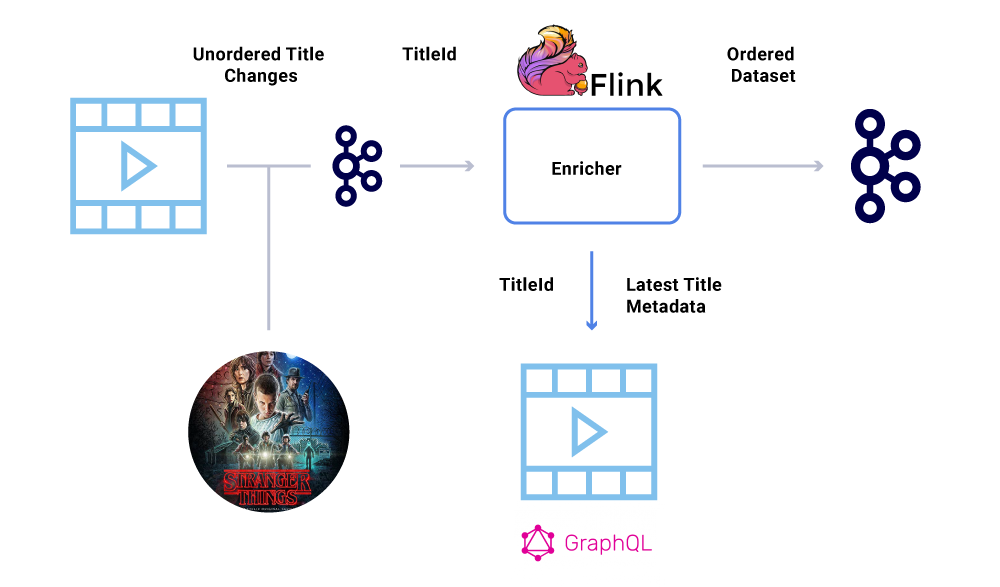
לדוגמה, תאריך ההשקה של “דברים זרים יותר” במקור הועבר מיולי ליוני אך לאחר מכן מיוני עד יולי. מסיבות שונות ומגוונות, ניתן היה לכתוב אירועים אלה בסדר שגוי לקאפקא (פסק זמן לרשת כאשר המפיק ניסה להגיע לקאפקא, באג במקביל בקוד המפיק וכו ‘). שיהוק בהזמנה יכול היה להשפיע מאוד על חישובים פיננסיים שונים.
כדי לעקוף תרחיש זה, מעודדים את המפיקים לשלוח רק את המזהה העיקרי של הישות שהשתנה ולא את העומס המלא בהודעת הקאקה. תהליך ההעשרה (המתואר בסעיף לעיל) ששאל את שירות המקור עם מזהה הישות כדי להשיג את המצב/עומס המטען המעודכן ביותר, ובכך לספק דרך אלגנטית לעקוף את הנושא מחוץ להזמנה. אנו מתייחסים לזה התממשות מעוכבת, וזה מבטיח מערכי נתונים שהוזמנו.
צרכנים
אנו משתמשים ב- Spring Boot כדי ליישם רבים משירותי המיקרו הצורכים שקוראים מנושאי Kafka. Boot Spring מציע צרכני קפקא מובנים מעולים הנקראים מחברי Spring Kafka, שהופכים את הצריכה לחלקים, ומספקת דרכים קלות לחבר הערות לצריכה ולתריסציה של נתונים.
היבט אחד של הנתונים שאנו מקיים’לא נדון עדיין חוזים. כשאנחנו מגדלים את השימוש בזרמי אירועים, אנו בסופו של דבר עם קבוצה מגוונת של מערכי נתונים, שחלקם נצרכים על ידי מספר גדול של יישומים. במקרים אלה, הגדרת סכימה בפלט היא אידיאלית ומסייעת להבטיח תאימות לאחור. לשם כך, אנו ממנפים את רישום הסכימה הקונפונטי ו- Apache Avro ™ לבניית הזרמים הסכימים שלנו לזרמי נתונים גרסאות.
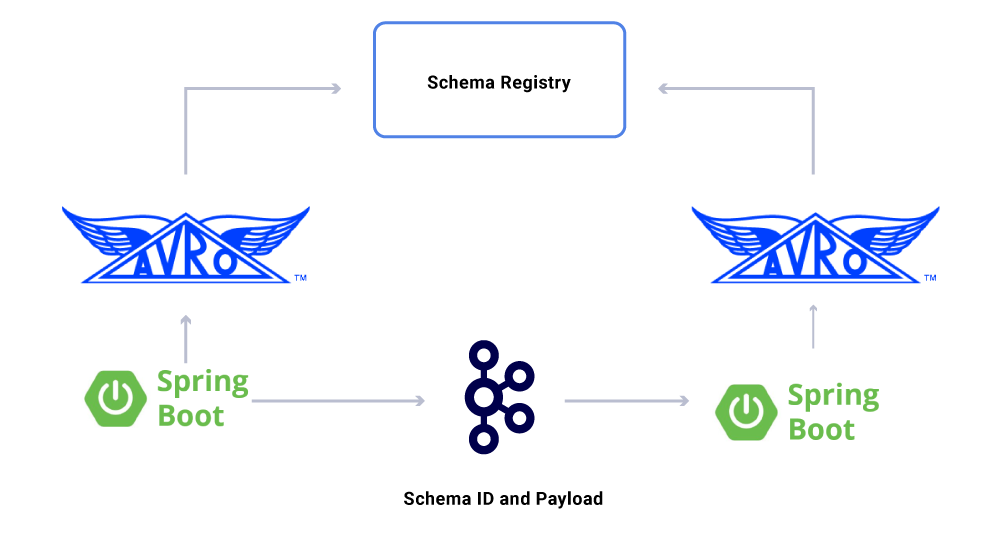
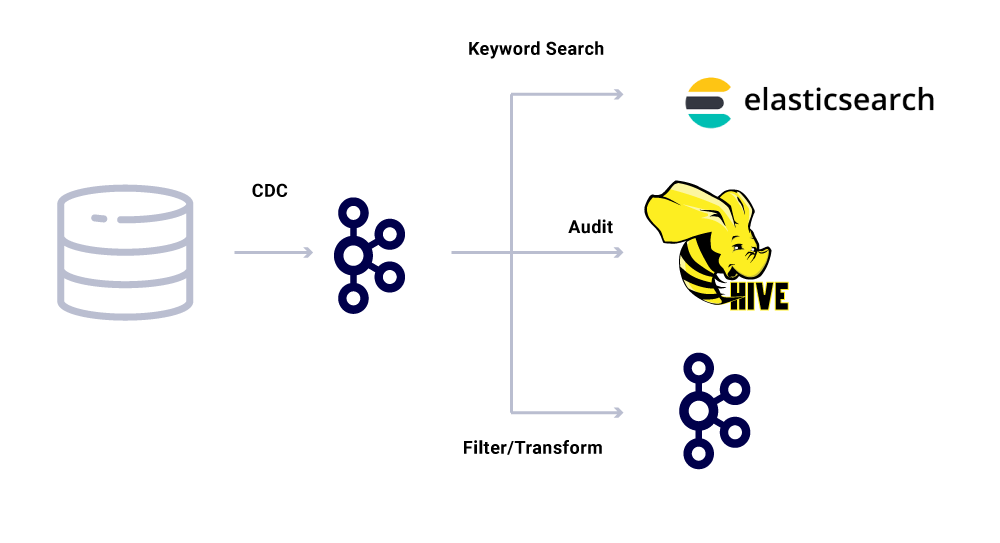
בנוסף לצרכנים ייעודיים של שירותי מיקרו, יש לנו גם כיורי CDC המיידדים את הנתונים למגוון חנויות לצורך ניתוח נוסף. אלה כוללים Elasticsearch לחיפוש מילות מפתח, Apache Hive ™ לביקורת, ו- Kafka עצמה להמשך עיבוד הזרם במורד הזרם. העומס של כיורים כאלה נגזר ישירות מהודעת Kafka על ידי שימוש בשדה מזהה כמפתח וסוג העיקרי לזיהוי פעולות גס.
ערבויות למסירת הודעות
הבטחת בדיוק פעם אחת המסירה במערכת מבוזרת אינה טריוויאלית בגלל המורכבות המעורבת ושפע של חלקים נעים. על הצרכנים להיות בעלי התנהגות נמרצת כדי להסביר כל תשתית ותקלות יצרניות פוטנציאליות.
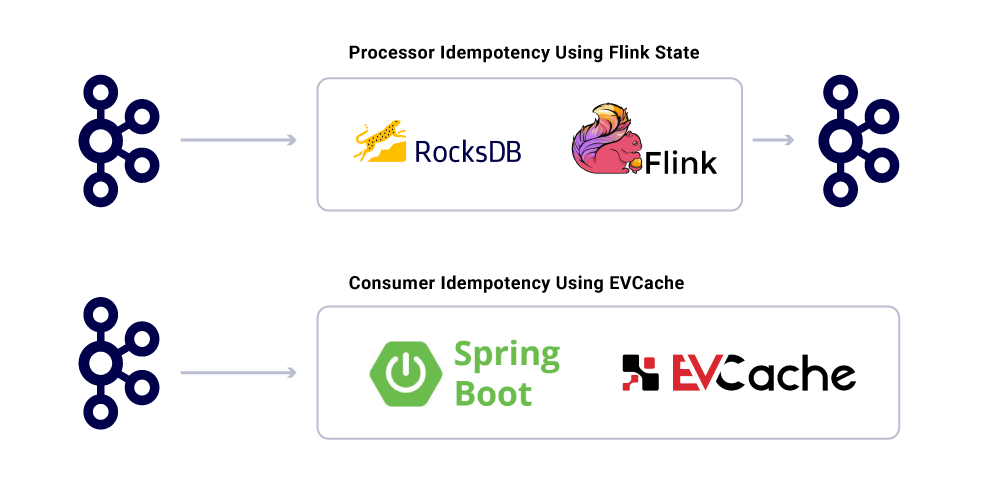
למרות העובדה שהיישומים הם דמויי-תועלת, הם לא צריכים לחזור על חישוב פעולות כבדות עבור הודעות שכבר מעובדות. דרך פופולרית להבטיח זאת היא לעקוב אחר UUID של הודעות הנצרכות על ידי שירות במטמון מבוזר עם תפוגה סבירה (מוגדרת על בסיס הסכמי רמת שירות (SLA). בכל עת שאותו UUID נתקלת במרווח התפוגה, הדילוג על העיבוד.
עיבוד בפלינק מספק ערבות זו על ידי שימוש בניהול המדינה הפנימי מבוסס ROCKSDB, כאשר המפתח הוא UUID של ההודעה. אם אתה רוצה לעשות זאת באופן גריד. צריכת יישומים המבוססים על אתחול האביב השימוש ב- EvCache כדי להשיג זאת.
ניטור רמות שירות תשתיות
זה’S חיוני עבור נטפליקס לתצוגה בזמן אמת של רמות השירות בתשתית שלה. נטפליקס כתבה את אטלס לניהול נתוני סדרות זמן ממדיות, מהם אנו מפרסמים ומדמיינים מדדים. אנו משתמשים במגוון מדדים שפורסמו על ידי מפיקים, מעבדים וצרכנים כדי לעזור לנו לבנות תמונה כמעט אמיתית של התשתית כולה.
חלק מהיבטי המפתח שאנו עוקבים אחריהם הם:
- רעננות SLA
- מה הקצה הזמן לקצה מהפקת אירוע עד שהוא מגיע לכל הכיורים?
- מהו פיגור העיבוד עבור כל צרכן?
- כמה גדול עומס אנו מסוגלים לשלוח?
- האם עלינו לדחוס את הנתונים?
- האם אנו מנצלים ביעילות את המשאבים שלנו?
- אנחנו יכולים לצרוך מהר יותר?
- האם אנו מסוגלים ליצור מחסום למצבנו ולחדש במקרה של כישלונות?
- אם איננו מסוגלים לעמוד בקצב האירוע האש, האם נוכל להחיל לחץ אחורי על המקורות המתאימים מבלי לקרוס את היישום שלנו?
- איך נתמודד עם התפרצויות אירועים?
- האם אנו מועברים מספיק כדי לפגוש את ה- SLA?
תַקצִיר
צוות ההפקות והפיננסים של סטודיו נטפליקס מחבק ממשל מבוזר כדרך המערכות האדריכלות. אנו משתמשים ב- Kafka כפלטפורמת הבחירה שלנו לעבודה עם אירועים, שהם דרך בלתי ניתנת לשינוי להקליט ולגמור את מצב המערכת. קפקא עזר לנו להשיג רמות גדולות יותר של נראות וניתוק בתשתית שלנו תוך כדי עזרה לנו באופן אורגני לגודל פעולות באופן אורגני. זה בלב המהפכה בתשתית סטודיו נטפליקס ואיתו, תעשיית הקולנוע.
מעוניין יותר?
אם אתה’D רוצה לדעת יותר, אתה יכול להציג את ההקלטה והשקופיות של פסגת קפקא שלי סן פרנסיסקו מצגת דברים – מקור נטפליקס!
נטפליקס: כיצד אפאצ’י קפקא הופך נתונים ממיליונים לאינטליגנציה
נטפליקס הוציאה 16 מיליארד דולר על ייצור תוכן בשנת 2020. בינואר 2021 הורדה אפליקציית Netflix Mobile (iOS ו- Android) 19 מיליון פעמים וחודש לאחר מכן, החברה הודיעה כי היא פגעה 203.66 מיליון מנויים ברחבי העולם. זה’בטוח להניח כי היקף הנתונים שהחברה אוספת ותהליכים הם מסיביים. השאלה היא –
כיצד נטפליקס מעבדת מיליארדי רישומי נתונים ואירועים כדי לקבל החלטות עסקיות קריטיות?
עם תקציב תוכן שנתי בשווי 16 מיליארד דולר, מקבלי ההחלטות בנטפליקס ארון’לא הולך לקבל החלטות הקשורות לתוכן על בסיס אינטואיציה. במקום זאת, אוצרי התוכן שלהם משתמשים בטכנולוגיה מתקדמת כדי להבין את כמויות עצומות של נתונים על התנהגות מנויים, העדפות תוכן למשתמש, עלויות ייצור תוכן, סוגים של תוכן שעובד וכו ‘. רשימה זו נמשכת.
משתמשי נטפליקס מוציאים בממוצע 3.שעתיים ביום בפלטפורמה שלהם וניזונים כל הזמן מההמלצות האחרונות של נטפליקס’S קנייני מנוע המלצות. זה מבטיח כי נטיית המנויים תהיה נמוכה ומפתה מנויים חדשים להירשם. משלוח תוכן מונע נתונים נמצא בחזית ובמרכז זה.
אז מה שנמצא מתחת למכסה המנוע מנקודת מבט לעיבוד נתונים?
במילים אחרות, כיצד בנתה נטפליקס עמוד שדרה טכנולוגי שאיפשר קבלת החלטות מונעת נתונים בקנה מידה כה מסיבי? כיצד ניתן להבין את התנהגות המשתמש של 203 מיליון מנויים?
נטפליקס משתמש במה שהיא מכנה צינור נתוני המפתח. בשנת 2016 צינור זה עיבד 500 מיליארד אירועים ביום. אירועים אלה כללו יומני שגיאות, פעילויות הצגת משתמשים, פעילויות ממשק משתמש, אירועי פתרון בעיות ועוד מערכי נתונים יקרי ערך אחרים.
לדברי נטפליקס, כפי שפורסם בבלוג הטכנולוגי שלה:
צינור Keystone הוא תשתיות פרסום, איסוף וניתוב של אירועים אחידים עבור עיבוד אצווה וזרם כאחד.
אשכולות Kafka הם חלק ליבה מצינור נתוני Keystone בנטפליקס. בשנת 2016, צינור נטפליקס השתמש ב -36 אשכולות קפקא כדי לעבד מיליארדי הודעות ביום.
אז מה זה אפאצ’ה קפקא? ולמה זה הפך כל כך פופולרי?
Apache Kafka היא פלטפורמת סטרימינג קוד פתוח המאפשרת פיתוח יישומים המובילים נפח גבוה של נתונים בזמן אמת. הוא נבנה במקור על ידי הגאונים בלינקדאין ומשמש כיום בנטפליקס, פינטרסט ו- Airbnb כדי להזכיר כמה.
קפקא עושה באופן ספציפי ארבעה דברים:
- זה מאפשר ליישומים לפרסם או להירשם לנתונים או לזרמי אירועים
- הוא מאחסן נתונים במדויק והוא סובלני תקלות מאוד
- זה מסוגל לעיבוד נתונים בזמן אמת בנפח גבוה.
- זה מסוגל לקחת ולעבד טריליוני רישומי נתונים ביום, ללא בעיות ביצועים
צוותי פיתוח תוכנה מסוגלים למנף את קפקא’יכולות S עם ממשקי ה- API הבאים:
- ממשק API של מפיק: ממשק API זה מאפשר לשירות מיקרו או יישום לפרסם זרם נתונים לנושא קפקה מסוים. נושא Kafka הוא יומן המאחסן נתונים ורשומות אירועים לפי הסדר בו הם התרחשו.
- ממשק API של צרכנים: ממשק API זה מאפשר ליישום להירשם לזרמי נתונים מנושא Kafka. בעזרת ממשק ה- API של הצרכן, יישומים יכולים לבלוט ולעבד את זרם הנתונים, שישמש כקלט ליישום שצוין.
- זרמים API: ממשק API זה קריטי לנתונים מתוחכמים ויישומי הזרמת אירועים. בעיקרו של דבר, הוא צורך זרמי נתונים מנושאי קפקא שונים ומסוגל לעבד או לשנות זאת לפי הצורך. לאחר עיבוד, זרם נתונים זה מתפרסם לנושא קפקא אחר שישמש במורד הזרם ו/או להפוך נושא קיים.
- API של מחבר: ביישומים מודרניים, יש צורך מתמיד לעשות שימוש חוזר במפיקים או בצרכנים ולשלב אוטומטית מקור נתונים באשכול קפקא. Kafka Connect הופך את זה ליותר מיותר על ידי חיבור קפקא למערכות חיצוניות.
היתרונות העיקריים של קפקא
על פי נתוני אתר Kafka, 80% מכלל חברות Fortune 100 משתמשות ב- Kafka. אחת הסיבות הגדולות ביותר לכך היא שהיא מתאימה היטב ליישומים קריטיים למשימה.
חברות מרכזיות משתמשות בקפקא מהסיבות הבאות:
- זה מאפשר ניתוק זרמי נתונים ומערכות בקלות
- זה נועד להיות מופץ, עמיד וסובלני תקלות
- המדרגיות האופקית של קפקא היא אחד היתרונות הגדולים ביותר שלה. זה יכול לקנה מידה של מאה של אשכולות ומיליוני הודעות בשנייה
- זה מאפשר הזרמת נתונים בזמן אמת בעלת ביצועים גבוהים, צורך קריטי ביישומים גדולים ומונעים נתונים
דרכים Kafka משמש למיטוב עיבוד הנתונים
קפקא משמש בכל תעשיות למגוון מטרות, כולל אך לא מוגבל להלן
- עיבוד נתונים בזמן אמת: בנוסף לשימוש שלה בחברות טכנולוגיה, Kafka הוא חלק בלתי נפרד מעיבוד נתונים בזמן אמת בענף הייצור, שם נתונים בעלי נפח גבוה מגיעים ממספר גדול של מכשירי IoT וחיישנים
- ניטור אתרים בקנה מידה: Kafka משמש למעקב אחר התנהגות משתמשים ופעילות אתרים באתרי תנועה גבוהה. זה עוזר עם ניטור, עיבוד, חיבור עם Hadoop בזמן אמת ואחסון נתונים לא מקוון
- מעקב אחר מדדי מפתח: מכיוון שניתן להשתמש ב- Kafka כדי לצבור נתונים מיישומים שונים לעדכון ריכוזי, הוא מקל על ניטור נתונים תפעוליים בעלי נפח גבוה
- צבירת יומן: זה מאפשר לצבור נתונים ממקורות מרובים ליומן כדי לקבל בהירות בצריכה מבוזרת
- מערכת העברת הודעות: זה אוטומטי יישומי עיבוד הודעות בקנה מידה גדול
- עיבוד זרם: לאחר שנושאי קפקא נצרכים כנתונים גולמיים בצינורות עיבוד בשלבים שונים, הם מצטברים, מועשרים או הופכים בדרך אחרת לנושאים חדשים לצריכה או עיבוד נוספים
- דה-צימוד תלות במערכת
- אינטגרציות עם Spark, Flink, Storm, Hadoop וטכנולוגיות נתונים גדולים אחרים
חברות המשתמשות בקאפקא כדי לעבד נתונים
כתוצאה מהגמישות והפונקציונליות שלו, Kafka משמש חלק מהעולם’חברות הטכנולוגיה הצומחות במהירות ביותר למטרות שונות:
- Uber-אסוף נתוני משתמש, מונית וטיול בזמן אמת כדי לחשב ולחזות את הביקוש ולחשוב תמחור מתח בזמן אמת
- LinkedIn-מונע דואר זבל ואוסף אינטראקציות משתמשים בכדי להמליץ על המלצות חיבור טובות יותר בזמן אמת
- טוויטר – חלק מתשתית עיבוד הסערה שלה
- Spotify – חלק ממערכת משלוח היומן שלה
- Pinterest – חלק מצינור איסוף היומן שלו
- Airbnb – צינור אירועים, מעקב חריגים וכו ‘.
- סיסקו – עבור OpenSOC (מרכז פעולות אבטחה)
קבוצת ראייה’המומחיות בקפקא
בקבוצת Merit, אנו עובדים עם חלק מהעולם’S חברות מודיעין B2B מובילות כמו וילמינגטון, דאו ג’ונס, גלניגן והיימרקט. צוותי הנתונים וההנדסה שלנו עובדים בשיתוף פעולה הדוק עם לקוחותינו כדי לבנות מוצרי נתונים וכלי בינה עסקיים. העבודה שלנו משפיעה ישירות על צמיחה עסקית על ידי עזרה ללקוחותינו לזהות הזדמנויות בעלות צמיחה גבוהה.
השירותים הספציפיים שלנו כוללים איסוף נתונים בנפח גבוה, טרנספורמציה של נתונים באמצעות AI ו- ML, צפייה באינטרנט ופיתוח יישומים בהתאמה אישית.
הצוות שלנו מביא גם לשולחן המומחיות העמוקה בבניית יישומי הזרמת נתונים בזמן אמת ועיבוד נתונים. המומחיות שלנו בקפקא מועילה במיוחד בהקשר זה.
Пикация
למערכות אדריכלות שרושמות ומגירות את מצב המערכת, נטפליקס ממנפת את אפאצ’ה קפקא וממשל מופץ. ניטין. משתף כיצד זה עוזר להם להשיג נראות וניתוק בתשתית שלהם תוך כדי גודל אורגני של פעולות: https: // lnkd.ב/gfxaa6g
כיצד נטפליקס משתמשת בקאפקא לסטרימינג מבוזר
קונפלינט.io
- Копироват
- לינקדאין
- פייסבוק
- טוויטר
מאמין, בעל, אב ל -5, מנהל תשתיות ושירותים IT, מנהיג צוות, מפתח.
נטפליקס בונה פלטפורמה אמינה וניתנת להרחבה עם מקור אירועים, MQTT ו- Alpakka-Kafka
נטפליקס פרסמה לאחרונה פוסט בבלוג המפרט כיצד היא בנתה פלטפורמת ניהול מכשירים אמינה באמצעות יישום מקור אירוע מבוסס MQTT. כדי לקנה מידה את הפיתרון שלה, נטפליקס מנצלת את אפאצ’ה קפקא, אלפקקה-קפקא וסיקר.
פלטפורמת ניהול המכשירים של נטפליקס היא המערכת שמנהלת מכשירי חומרה המשמשים לבדיקה אוטומטית של היישומים שלה. מהנדסי נטפליקס בנסון מא ואלוק אהוג’ה מתארים את המסע שעבר הרציף:
עיבוד זרמי קפקא יכול להיות קשה להשיג נכון. ((. ) למרבה המזל, הפרימיטיביות שמספקים זרמי אקה ואלפקקה-קפקא מאפשרים לנו להשיג בדיוק זאת על ידי כך שהם מאפשרים לנו לבנות פתרונות סטרימינג התואמים את זרימות העבודה העסקיות שיש לנו תוך כדי קנה מידה של תפוקת המפתחים בבניית פתרונות אלה. עם המעבד מבוסס Alpakka-Kafka במקום (. ), הבטחנו סובלנות לתקלות בצד הצרכני של מישור הבקרה, שהוא המפתח לאפשר צבירה של מצב מכשיר מדויק ואמין בפלטפורמת ניהול המכשירים.
((. ) אמינות הפלטפורמה ומישור הבקרה שלה נשענת על עבודה משמעותית שנעשתה במספר תחומים, כולל הובלת MQTT, אימות והרשאה, וניטור מערכות. ((. ) כתוצאה מעבודה זו, אנו יכולים לצפות כי פלטפורמת ניהול המכשירים תמשיך להתגבר על הגדלת עומסי העבודה לאורך זמן כאשר אנו על הספינה יותר מכשירים למערכות שלנו.
התרשים הבא מתאר את הארכיטקטורה.

מקור: https: // netflixtechblog.COM/COND-A-ARIMING-DEVICE-MANALING-PLATFORM-4F86230CA623
סביבת אוטומציה מקומית לאוטומציה (RAE) מחשב משובץ מתחבר למספר מכשירים שנמצאים במבחן (DUT). שירות הרישום המקומי אחראי לגילוי, אונלייה ושמירה על מידע על כל המכשירים המחוברים ב- RAE. כאשר תכונות המכשירים והמאפיינים משתנים לאורך זמן, זה חוסך שינויים אלה ברישום המקומי ופורסם בו זמנית במעלה הזרם למישור בקרה מבוסס ענן. בנוסף לשינויי תכונות, הרישום המקומי מפרסם תמונת מצב מלאה של רשומת המכשיר במרווחים קבועים. אירועי מחסום אלה מאפשרים שחזור מהיר יותר של מצב על ידי צרכני עדכון הנתונים תוך שמירה מפני עדכונים שהוחמצו.
עדכונים מתפרסמים בענן באמצעות MQTT. MQTT הוא פרוטוקול העברת הודעות סטנדרטיות של OASIS לאינטרנט של הדברים (IOT). זהו הובלת הובלת העברת הודעות קלה ועם זאת אמין אך אמין אידיאלית לחיבור מכשירים מרוחקים עם טביעת רגל קטנה ורוחב פס רשת מינימלי. מתווך MQTT אחראי על קבלת כל ההודעות, סינון אותן ושליחתן ללקוחות המנויים בהתאם.
נטפליקס משתמשת באפצ’ה קפקא ברחבי הארגון. כתוצאה מכך, גשר ממיר הודעות MQTT לרשומות Kafka. זה מגדיר את מפתח הרשומה לנושא MQTT שהודר הוקצה. מא ואחוג’ה מתארים כי “מכיוון שעדכוני מכשירים שפורסמו ב- MQTT מכילים את device_session_id בנושא, כל עדכוני המידע למכשירים להפעלת מכשירים נתון יופיעו למעשה באותה מחיצה של Kafka, ובכך יעניקו לנו סדר הודעה מוגדר היטב לצריכה.”
רישום הענן בולע את ההודעות שפורסמו, מעבד אותן ודוחף נתונים ממומשים למערך נתונים המגובה על ידי ג’וקדב. ג’וקד הוא יישום של מחלקה של מערכות RDBMS בשם NewsQL. מא ואחוג’ה מסבירים את הבחירה של נטפליקס:
ג’וקדב נבחר כחנות נתוני הגיבוי מכיוון שהוא הציע יכולות SQL, ומודל הנתונים שלנו עבור רשומות המכשיר נרמל. בנוסף, בניגוד לחנויות SQL אחרות, JockOachDB נועד מהיסוד כדי להיות מדרגית אופקית, מה שמתייחס לדאגות שלנו ביכולת רישום הענן להתגבר עם מספר המכשירים שנמצאים בפלטפורמת ניהול המכשירים.
התרשים הבא מציג את צינור העיבוד של קפקא הכולל את רישום הענן.
מקור: https: // netflixtechblog.COM/COND-A-ARIMING-DEVICE-MANALING-PLATFORM-4F86230CA623
נטפליקס שקלה מסגרות רבות ליישום צינורות עיבוד הזרם המתוארים לעיל. מסגרות אלה כוללות זרמי קפקא, אביב קפקאליסטנר, פרויקט כור ופלינק. בסופו של דבר הוא בחר באלפקה-קפקה. הסיבה לבחירה זו היא שאלפקקה-קפקא מספקת שילוב מגף האביב יחד עם “שליטה עדינה על עיבוד זרם, כולל תמיכה אוטומטית בלחץ אחורי ופיקוח על זרמים.”יתר על כן, לדברי מא ואחוג’ה, אקקה ואלפקקה-קפקא הם קלים יותר מהחלופות, ומכיוון שהן בוגרות יותר, עלויות התחזוקה לאורך זמן יהיו נמוכות יותר.
היישום מבוסס Alpakka-Kafka החליף את ההשתלה המבוססת על קפקליסטנר אביבית מוקדם יותר. מדדים שנמדדו על יישום הייצור החדש מגלים כי התמיכה בלחץ האחורי הילידים של אלפקה-קפקא יכולה לגודל דינמי של צריכת הקפקא שלה. שלא כמו Kafkalistener, Alpakka-Kafka אינו מכוון או מכריח יתר על המידה הודעות Kafka. כמו כן, ירידה בערכי הפיגור הצרכנים המרביים בעקבות המהדורה העלתה כי אלפקקה-קפקא ויכולות הסטרימינג של אקה מבצעות היטב בקנה מידה, אפילו לנוכח עומסי הודעה פתאומית.

